mainvarsetnorm
Perform rank invariant set normalization on gene expression values from two experimental conditions or phenotypes
Syntax
NormDataY =
mainvarsetnorm(DataX, DataY)
NormDataY =
mainvarsetnorm(..., 'Thresholds', ThresholdsValue,
...)
NormDataY =
mainvarsetnorm(..., 'Exclude', ExcludeValue,
...)
NormDataY =
mainvarsetnorm(..., 'Percentile', PercentileValue,
...)
NormDataY =
mainvarsetnorm(..., 'Iterate', IterateValue,
...)
NormDataY =
mainvarsetnorm(..., 'Method', MethodValue,
...)
NormDataY =
mainvarsetnorm(..., 'Span', SpanValue,
...)
NormDataY =
mainvarsetnorm(..., 'Showplot', ShowplotValue,
...)
Arguments
DataX | Vector of gene expression values from a single experimental condition or phenotype, where each row corresponds to a gene. These data points are used as the baseline. |
DataY | Vector of gene expression values from a single experimental condition or phenotype, where each row corresponds to a gene. These data points will be normalized using the baseline. |
ThresholdsValue | Vector that sets the thresholds for the lowest average
rank and the highest average rank between the two data sets. The average
rank for each data point is determined by first converting the values
in Note These individual thresholds are used to determine the rank invariant set, which is a set of data points, each having a proportional rank difference (prd) smaller than its predetermined threshold. For more information on the rank invariant set, see Description.
|
ExcludeValue | Property to filter the invariant set of data points,
by excluding the data points whose average rank (between |
PercentileValue | Property to stop the iteration process when the number
of data points in the invariant set reaches Note If you do not use this property, the iteration process continues until no more data points are eliminated.
|
IterateValue | Property to control the iteration process for determining
the invariant set of data points. Enter Tip Select
|
MethodValue | Property to select the smoothing method used to normalize
the data. Enter |
SpanValue | Property to set the window size for the smoothing method.
If |
ShowplotValue | Property to control the plotting of a pair of M-A scatter
plots (before and after normalization). M is the ratio between |
Description
NormDataY =
mainvarsetnorm(DataX, DataY)DataY, a vector of gene expression
values, to a reference vector, DataX, using
the invariant set method. NormDataY is
a vector of normalized gene expression values from DataY.
Specifically, mainvarsetnorm:
Determines the proportional rank difference (prd) for each pair of ranks, RankX and RankY, from the two vectors of gene expression values,
DataXandDataY.prd = abs(RankX - RankY)
Determines the invariant set of data points by selecting data points whose proportional rank differences (prd) are below threshold, which is a predetermined threshold for a given data point (defined by the
ThresholdsValueproperty). It optionally repeats the process until either no more data points are eliminated, or a predetermined percentage of data points is reached.The invariant set is data points with a prd < threshold.
Uses the invariant set of data points to calculate the lowess or running median smoothing curve, which is used to normalize the data in
DataY.
Note
If DataX or DataY contains
NaN values, then NormDataY will also contain
NaN values at the corresponding positions.
Tip
mainvarsetnorm is useful for correcting for
dye bias in two-color microarray data.
NormDataY = mainvarsetnorm(...,
'PropertyName', PropertyValue,
...)mainvarsetnorm with optional
properties that use property name/property value pairs. You can specify
one or more properties in any order. Each PropertyName must
be enclosed in single quotation marks and is case insensitive. These
property name/property value pairs are as follows:
sets the thresholds for the lowest average rank and
the highest average rank between the two data sets. The average rank
for each data point is determined by first converting the values in NormDataY =
mainvarsetnorm(..., 'Thresholds', ThresholdsValue,
...)DataX and DataY to
ranks, then averaging the two ranks for each data point. Then, the
threshold for each data point is determined by interpolating between
the threshold for the lowest average rank and the threshold for the
highest average rank.
Note
These individual thresholds are used to determine the rank invariant set, which is a set of data points, each having a proportional rank difference (prd) smaller than its predetermined threshold. For more information on the rank invariant set, see Description.
ThresholdsValue is a 1-by-2 vector
[LT, HT], where LT is
the threshold for the lowest average rank and HT is
threshold for the highest average rank. Select these two thresholds
empirically to limit the spread of the invariant set, but allow enough
data points to determine the normalization relationship. Values must
be between 0 and 1. Default
is [0.03, 0.07].
NormDataY =
mainvarsetnorm(..., 'Exclude', ExcludeValue,
...)DataX and DataY)
is in the highest N ranked averages or
lowest N ranked averages.
NormDataY =
mainvarsetnorm(..., 'Percentile', PercentileValue,
...)N percent
of the total number of input data points. Default is 1.
Note
If you do not use this property, the iteration process continues until no more data points are eliminated.
NormDataY =
mainvarsetnorm(..., 'Iterate', IterateValue,
...)IterateValue is true, mainvarsetnorm repeats
the process until either no more data points are eliminated, or a
predetermined percentage of data points (PercentileValue)
is reached. When IterateValue is false,
performs only one iteration of the process. Default is true.
Tip
Select false for smaller data sets, typically
less than 200 data points.
NormDataY =
mainvarsetnorm(..., 'Method', MethodValue,
...)MethodValue is 'lowess', mainvarsetnorm uses
the lowess method. When MethodValue is
'runmedian', mainvarsetnorm uses
the running median method. Default is 'lowess'.
NormDataY =
mainvarsetnorm(..., 'Span', SpanValue,
...)SpanValue is
less than 1, the window size is that percentage of the number of data
points. If SpanValue is equal to or greater
than 1, the window size is of size SpanValue.
Default is 0.05, which corresponds to a window
size equal to 5% of the total number of data points in the invariant
set.
NormDataY =
mainvarsetnorm(..., 'Showplot', ShowplotValue,
...)DataX and DataY.
A is the average of DataX and DataY.
When ShowplotValue is true, mainvarsetnorm plots
the M-A scatter plots. Default is false.
Examples
Normalize Microarray Data
This example illustrates how to correct for dye bias or scanning differences between two channels of data from a two-color microarray experiment.
Read microarray data from a sample GPR file.
maStruct = gprread('mouse_a1wt.gpr');Extract gene expression values from two different experimental conditions.
cy5data = magetfield(maStruct, 'F635 Median'); cy3data = magetfield(maStruct, 'F532 Median');
Normalize cy3data using cy5data as reference and plot the results.
Normcy3data = mainvarsetnorm(cy5data, cy3data, 'showplot', true);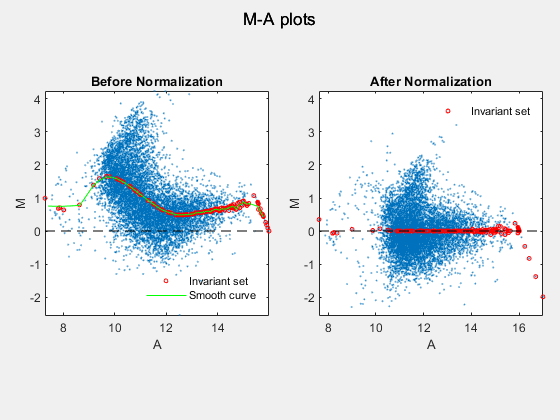
Under perfect experimental conditions, data points with equal expression values would fall along the M = 0 line, which represents a gene expression ratio of 1. However, dye bias caused the measured values in one channel to be higher than the other channel, as seen in the Before normalization plot. Normalization corrected the variance, as seen in the After normalization plot.
References
[1] Tseng, G.C., Oh, Min-Kyu, Rohlin, L., Liao, J.C., and Wong, W.H. (2001) Issues in cDNA microarray analysis: quality filtering, channel normalization, models of variations and assessment of gene effects. Nucleic Acids Research. 29, 2549-2557.
[2] Hoffmann, R., Seidl, T., and Dugas, M. (2002) Profound effect of normalization on detection of differentially expressed genes in oligonucleotide microarray data analysis. Genome Biology. 3(7): research 0033.1-0033.11.
Version History
Introduced in R2006a
See Also
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)