Deep Learning Processor IP Core Architecture
Deep Learning HDL Toolbox™ provides a target-independent generic deep learning processor IP core that you can deploy to any custom platform. You can reuse the deep learning processor IP core and share it to accommodate deep neural networks that have various layer sizes and parameters. Use this deep learning processor IP core to rapidly prototype deep neural networks from MATLAB® and deploy the network to FPGAs.
This image shows the deep learning processor IP core architecture:
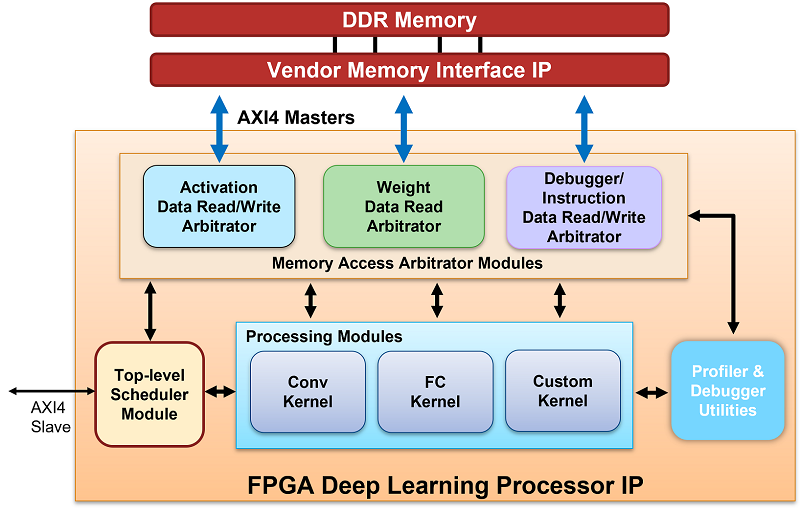
To illustrate the deep learning processor IP core architecture, consider an image classification example.
DDR Memory
You can store the input images, weights, and output images in the external DDR memory.
The processor consists of three AXI4 master interfaces that communicate with the external
memory. You can use one of the AXI4 Master interfaces to load the input images onto the
processing modules. The compile method
generates the weight data. To retrieve the activation data from the DDR , see Deep Learning Processor IP Core External Memory Data Format. You can write the weight
data to a deployment file and use the deployment file to initialize the generated deep
learning processor. For more information, see Initialize Deployed Deep Learning Processor Without Using a MATLAB Connection.
Memory Access Arbitrator Modules
The activation and weight memory access arbitrator modules use AXI Master interface to read and write weights and activation data to and from the processing modules. The profiler AXI Master interface reads and writes profiler timing data and instructions to the profiler module.
Convolution Kernel
The Conv Kernel implements layers that have a convolution layer
output format. The two AXI4 master interfaces provide the weights and activations for the
layer to the Conv Kernel. The Conv Kernel then
performs the implemented layer operation on the input image. This kernel is generic because
it can support tensors and shapes of various sizes. For a list of layers with the
conv output format, see Supported Layers. For a list of the
conv kernel properties, see dlhdl.ProcessorConfig.
Top-Level Scheduler Module
The top-level scheduler module schedules what instructions to run, what data to read from DDR, and when to read the data from DDR. The scheduler module acts as the central computer in a distributed computer architecture that distributes instructions to the processing modules. For example, if the network has a convolution layer, fully connected layer, and a multiplication layer the scheduler:
Schedules the processing and data read instructions for the convolution layer and sends them to the
convkernel.Schedules the processing and data read instructions for the fully connected layer and sends them to the
FCkernel.Schedules the processing and data read instructions for the multiplication layer and sends them to the
customkernel.
Fully Connected Kernel
The fully connected (FC) kernel implements layers that have a fully connected layer
output format. The two AXI4 master interfaces provide the weights and activations to the
FC Kernel. The FC Kernel then performs the
fully-connected layer operation on the input image. This kernel is also generic because it
can support tensors and shapes of various sizes. For a list of layers with FC output format,
see Supported Layers. For a list of the
FC Kernel properties, see dlhdl.ProcessorConfig.
Custom Kernel
The custom kernel module implements layers that are registered as a custom layer by
using the registerCustomLayer method. To learn how to create, register, and validate your
own custom layers, see Register, Validate, and Deploy Custom Natural Logarithm Layer Network to FPGA. For example, the addition
layer, multiplication layer, resize2dlayer, and so on are implemented on
the custom kernel module. For a list of layers implemented on this module, see Supported Layers. For a list of the
Custom Kernel properties, see dlhdl.ProcessorConfig.
Profiler Utilities
When you set the Profiler argument of the predict
or predictAndUpdateState methods to on, the profiler
module collects information from the kernel, such as the Conv Kernel
start and stop times, FC Kernel start and stop times, and so on. The
profiler module uses this information to create a profiler table with these results. For
more information, see Profile Inference Run.
See Also
dlhdl.ProcessorConfig | compile