What Is Reinforcement Learning?
Reinforcement learning is a goal-directed computational approach in which an agent learns to perform a task by interacting with a dynamic environment. This learning approach enables the agent to make a series of decisions to maximize the cumulative reward for the task without human intervention and without explicitly programming the agent to achieve a goal. The following diagram shows a general representation of a reinforcement learning scenario.
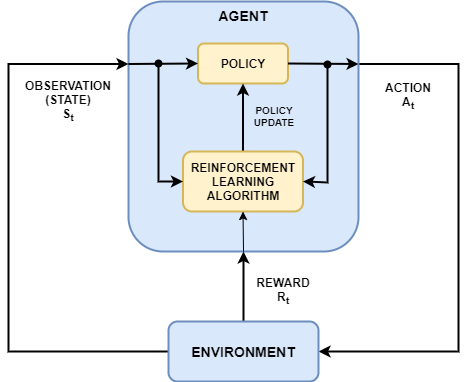
The agent contains two components: a policy and a learning algorithm.
The policy is a mapping that selects actions based on the observations from the environment. Typically, the policy is a function approximator with tunable parameters, such as a deep neural network.
The learning algorithm continuously updates the policy parameters based on the actions, observations, and reward. The goal of the learning algorithm is to find an optimal policy that maximizes the cumulative reward received during the task.
The reinforcement learning algorithm trains the agent to complete a task within the environment (which is unknown to the agent). The agent receives observations and a reward from the environment and sends actions to the environment. The reward is a measure of how successful an action is with respect to eventually completing the task goal.
In other words, reinforcement learning involves an agent learning the optimal behavior through repeated trial-and-error interactions with the environment without human involvement.
As an example, consider the task of parking a vehicle using an automated driving system. The goal of this task is for the vehicle computer (agent) to park the vehicle in the correct position and orientation. To do so, the controller uses readings from cameras, accelerometers, gyroscopes, a GPS receiver, and lidar (observations) to generate steering, braking, and acceleration commands (actions). The action commands are sent to the actuators that control the vehicle. The resulting observations depend on the actuators, sensors, vehicle dynamics, road surface, wind, and many other less-important factors. All these factors, that is, everything that is not the agent, make up the environment in reinforcement learning.
To learn how to generate the correct actions from the observations, the computer repeatedly tries to park the vehicle using a trial-and-error process. To guide the learning process, you provide a signal that is one when the car successfully reaches the desired position and orientation and zero otherwise (reward). During each trial, the computer selects actions using a mapping (policy) initialized with some default values. After each trial, the computer updates the mapping to maximize the reward (learning algorithm). This process continues until the computer learns an optimal mapping that successfully parks the car.
For an introduction to the typical workflow used in reinforcement learning, see Reinforcement Learning Workflow.