Loop Rolling
One of the optimization features of the Target Language Compiler is the intrinsic support for loop rolling. Based on a specified threshold, code generation for looping operations can be unrolled or left as a loop (rolled).
Coupled with loop rolling is the concept of noncontiguous signals. Consider the following model:
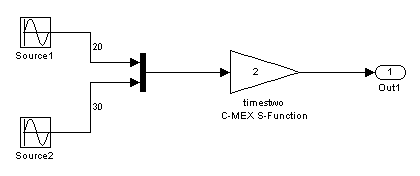
The input to the timestwo S-function comes from two arrays located at
two different memory locations, one for the output of source1 and one for
the output of block source2. This is because of an optimization that makes
the Mux block virtual, meaning that code is not
explicitly generated for the Mux block and thus processor cycles are not spent
evaluating it (i.e., it becomes a pure graphical convenience for the block diagram). So this
is represented in the model.rtw
Block {
Type "S-Function"
MaskType "S-function: timestwo"
BlockIdx [0, 0, 2]
SL_BlockIdx 2
GrSrc [0, 1]
ExprCommentInfo {
SysIdxList []
BlkIdxList []
PortIdxList []
}
ExprCommentSrcIdx {
SysIdx -1
BlkIdx -1
PortIdx -1
}
Name "<Root>/timestwo C-MEX S-Function"
SLName "<Root>/timestwo \nC-MEX S-Function"
Identifier timestwoCMEXSFunction
TID 0
RollRegions [0:19, 20:49]
NumDataInputPorts 1
DataInputPort {
SignalSrc [b0@20, b1@30]
SignalOffset [0:19, 0:29]
Width 50
RollRegions [0:19, 20:49]
}
NumDataOutputPorts 1
DataOutputPort {
SignalSrc [b2@50]
SignalOffset [0:49]
Width 50
}
Connections {
InputPortContiguous [no]
InputPortConnected [yes]
OutputPortConnected [yes]
OutputPortBeingMerged [no]
DirectSrcConn [no]
DirectDstConn [yes]
DataOutputPort {
NumConnPoints 1
ConnPoint {
SrcSignal [0, 50]
DstBlockAndPortEl [0, 4, 0, 0]
}
}
}
.
.
.From this fragment of the model.rtwRollRegion entries are not just one
number, but two groups of numbers. This denotes two groupings in memory for the input signal.
The generated code looks like this:
/* S-Function Block: <Root>/timestwo C-MEX S-Function */
/* Multiply input by two */
{
int_T i1;
const real_T *u0 = &contig_sample_B.u[0];
real_T *y0 = contig_sample_B.timestwoCMEXSFunction_m;
for (i1=0; i1 < 20; i1++) {
y0[i1] = u0[i1] * 2.0;
}
u0 = &contig_sample_B.u_o[0];
y0 = &contig_sample_B.timestwoCMEXSFunction_m[20];
for (i1=0; i1 < 30; i1++) {
y0[i1] = u0[i1] * 2.0;
}
}Notice that two loops are generated and between them the input signal is redirected from
the first base address, &contig_sample_B.u[0], to the second base
address of the signals, &contig_sample_B.u_o[0]. If you do not want to
support this in your S-function or your generated code, you can use
ssSetInputPortRequiredContiguous(S, 1);
in the mdlInitializeSizes function to cause Simulink® to implicitly generate code that performs a buffering operation. This option
uses both extra memory and CPU cycles at run-time, but might be worth it if your algorithm
performance increases enough to offset the overhead of the
buffering.
Use the %roll directive to generate loops. See also %roll for the
reference entry for %roll, and Input Signal Functions for a discussion on the behavior of
%roll.