k-Means Clustering
This topic provides an introduction to k-means clustering and an
example that uses the Statistics and Machine Learning Toolbox™ function kmeans to find the best clustering solution
for a data set.
Introduction to k-Means Clustering
k-means clustering is a partitioning method. The function kmeans partitions data into k mutually exclusive
clusters and returns the index of the cluster to which it assigns each observation.
kmeans treats each observation in your data as an object
that has a location in space. The function finds a partition in which objects within
each cluster are as close to each other as possible, and as far from objects in
other clusters as possible. You can choose a distance metric to use with
kmeans based on attributes of your data. Like many
clustering methods, k-means clustering requires you to specify
the number of clusters k before clustering.
Unlike hierarchical clustering, k-means clustering operates on actual observations rather than the dissimilarity between every pair of observations in the data. Also, k-means clustering creates a single level of clusters, rather than a multilevel hierarchy of clusters. Therefore, k-means clustering is often more suitable than hierarchical clustering for large amounts of data.
Each cluster in a k-means partition consists of member objects and a
centroid (or center). In each cluster, kmeans minimizes the sum
of the distances between the centroid and all member objects of the cluster.
kmeans computes centroid clusters differently for the
supported distance metrics. For details, see 'Distance'.
You can control the details of the minimization using name-value pair arguments available to
kmeans; for example, you can specify the initial values of
the cluster centroids and the maximum number of iterations for the algorithm. By
default, kmeans uses the k-means++ algorithm to initialize cluster
centroids, and the squared Euclidean distance metric to determine distances.
When performing k-means clustering, follow these best practices:
Compare k-means clustering solutions for different values of k to determine an optimal number of clusters for your data.
Evaluate clustering solutions by examining silhouette plots and silhouette values. You can also use the
evalclustersfunction to evaluate clustering solutions based on criteria such as gap values, silhouette values, Davies-Bouldin index values, and Calinski-Harabasz index values.Replicate clustering from different randomly selected centroids and return the solution with the lowest total sum of distances among all the replicates.
To perform k-means clustering interactively, use the Cluster Data Live Editor task.
Compare k-Means Clustering Solutions
This example explores k-means clustering on a four-dimensional data set. The example shows how to determine the correct number of clusters for the data set by using silhouette plots and values to analyze the results of different k-means clustering solutions. The example also shows how to use the 'Replicates' name-value pair argument to test a specified number of possible solutions and return the one with the lowest total sum of distances.
Load Data Set
Load the kmeansdata data set.
rng('default') % For reproducibility load('kmeansdata.mat') size(X)
ans = 1×2
560 4
The data set is four-dimensional and cannot be visualized easily. However, kmeans enables you to investigate whether a group structure exists in the data.
Create Clusters and Examine Separation
Partition the data set into three clusters using k-means clustering. Specify the city block distance metric, and use the default k-means++ algorithm for cluster center initialization. Use the 'Display' name-value pair argument to print the final sum of distances for the solution.
[idx3,C,sumdist3] = kmeans(X,3,'Distance','cityblock', ... 'Display','final');
Replicate 1, 7 iterations, total sum of distances = 12.33359.9739211.091610.116811.700510.187913.532612.580711.219112.853510.704410.77138.1630912.171811.45579.8538112.795914.45599.6384511.238811.47769.7562110.123212.32649.889067.9706610.418212.44569.5151813.42537.2736915.41889.27369.8963410.768712.716310.249114.86810.06114.32529.8808910.224410.9798.194249.6843810.12610.37459.6912610.432918.862112.424610.39059.7947712.0569.237947.192279.8355711.795813.549418.02813.513310.538115.215712.89.2484611.52888.301189.2878714.401612.558510.48410.101410.28399.737857.5376310.087512.188111.936816.910110.36532.424443.605043.009376.141930.7777841.275414.437837.683983.299182.974482.164524.141572.512513.691782.439292.260422.138720.3402413.059593.563791.504873.504481.640413.24173.071245.230583.621591.815782.63742.231127.019662.391782.75715.896420.6779552.677142.014591.678420.5832696.274682.599293.145995.006793.620742.74974.378482.172092.514132.438561.897813.279913.415875.648724.072633.611244.724717.301022.696322.746784.426383.89472.534974.733063.241314.133842.646882.442330.889671.519181.458941.612132.854781.571712.325032.15933.76761.06813.353431.085264.871233.935892.697852.955311.566992.421531.331792.126571.121152.591592.476291.079673.813861.357062.856981.336592.617471.469792.846445.400326.266552.010324.869181.624674.274263.272334.068951.366133.987062.402827.719572.692591.583231.749414.244762.257793.045331.817942.349951.317742.891512.062391.841353.024056.257353.894233.212662.465583.087333.196456.468895.055881.578383.829412.847735.021947.242854.409553.820693.416131.554374.686762.595072.783435.921083.788213.724522.426563.828561.592593.265851.944974.448221.95850.9445461.232322.978152.227741.720342.340593.055992.181499.579881.994862.509331.870951.987523.21696.594761.659552.606422.473987.124972.289892.748422.446481.12951.429993.671496.682094.405384.846433.293162.569161.408522.538991.540382.621443.226881.920264.184716.529713.003374.678543.481483.064462.715841.659710.9387373.506092.938462.829382.99012.378763.13991.729052.329211.716221.534693.631311.4264.504781.347640.9666442.715343.752922.991482.456372.344163.321973.001276.299943.210953.82422.618236.897514.000036.634695.061853.944296.593628.401773.720713.118053.489322.658992.872313.632082.225950.8828163.319422.922281.022671.868071.303553.539033.794393.6481.768263.422975.897644.255962.67984.48661.991481.409152.165113.123423.336836.073052.2654.391941.1681.542493.598338.56184.953921.530273.065412.230056.847555.549352.671972.185062.2427911.4684.366762.229123.181826.636053.901067.207545.533744.548713.004341.989721.254471.496712.088621.881631.692231.305738.704622.331792.570672.527942.617058.464034.935452.805255.110151.898143.375360.9778493.264722.864252.684771.436129.013262.44463.983841.704511.420123.131071.901315.424463.892031.229182.825833.444072.051535.60644.720963.602781.873483.863843.974692.436382.067874.07954.13224.609053.285962.745673.44613.607193.481222.576364.811530.891972.507010.4076293.235464.14985.64743.400672.942361.605714.800314.289742.029511.808715.022014.119913.653584.235262.408924.747940.9184210.9380626.022292.149263.952862.65231.473832.904876.019271.437680.9252253.11951.367062.306645.604272.205082.644647.931324.286935.577791.3393.511392.408346.755854.839241.1444.056041.837293.318472.374675.648681.755874.691081.605943.165321.989192.937344.754833.094567.388235.82343.942322.582552.291162.416673.35712.277261.76032.701683.688493.019361.526613.023412.175051.635656.544232.603592.085315.107912.402074.905294.190414.307886.729182.112541.983072.47596.588732.781192.230742.537285.03830.7022944.95294.080833.748713.645825.11992.633530.7536962.921783.544072.691234.159253.544612.066853.36262.018013.104162.199141.084125.693791.636896.090332.29823.84711.348190.6705253.620344.00251.719842.640425.939321.99731.783964.767265.337361.984899.134861.292222.713231.880253.772266.164281.925753.527832.422754.910284.647242.91052.572332.644713.50167. Best total sum of distances = 2459.98
idx3 contains cluster indices that indicate the cluster assignment for each row in X. To see if the resulting clusters are well separated, you can create a silhouette plot.
A silhouette plot displays a measure of how close each point in one cluster is to points in the neighboring clusters. This measure ranges from 1 (indicating points that are very distant from neighboring clusters) through 0 (points that are not distinctly in one cluster or another) to –1 (points that are probably assigned to the wrong cluster). silhouette returns these values in its first output.
Create a silhouette plot from idx3. Specify 'cityblock' for the distance metric to indicate that the k-means clustering is based on the sum of absolute differences.
[silh3,h] = silhouette(X,idx3,'cityblock'); xlabel('Silhouette Value') ylabel('Cluster')
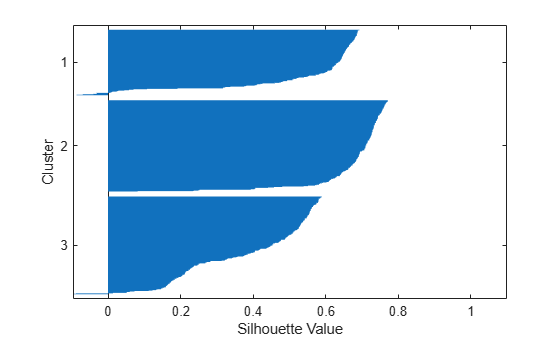
The silhouette plot shows that most points in the second cluster have a large silhouette value (greater than 0.6), indicating that the cluster is somewhat separated from neighboring clusters. However, the third cluster contains many points with low silhouette values, and the first and third clusters contain a few points with negative values, indicating that these two clusters are not well separated.
To see if kmeans can find a better grouping of the data, increase the number of clusters to four. Print information about each iteration by using the 'Display' name-value pair argument.
idx4 = kmeans(X,4,'Distance','cityblock','Display','iter');
iter phase num sum
1 1 560 2.50747
8.304961e-01 2.110459e+00 2.735457e+00 2.46836
2.036070e+00 3.770269e+00 2.866086e+00 1.73312
3.063747e+00 1.697008e+00 1.218750e+00 5.63006
2.345771e+00 2.756564e+00 2.958386e+00 2.96989
4.629916e+00 2.612240e+00 1.476521e+00 2.3564
3.561821e+00 1.910498e+00 3.722177e+00 7.8805
5.601491e+00 3.110286e+00 2.683279e+00 2.05194
3.662951e+00 6.267081e+00 6.011975e+00 3.36686
5.494719e+00 3.108410e+00 3.386063e+00 2.76565
5.105645e+00 2.498318e+00 4.562881e+00 1.6913
5.627059e+00 1.306599e+00 2.944986e+00 4.14043
2.716523e+00 2.287602e+00 8.619236e-01 3.16994
9.099832e+00 2.662265e+00 4.798414e+00 1.07115
2.230025e+00 2.151256e+00 3.884083e+00 3.10084
1.614047e+00 3.367665e+00 8.265723e+00 3.75101
9.444974e-01 5.453364e+00 2.618340e+00 1.2037
2.351116e+00 3.856289e+00 2.856166e+00 4.63925
3.351290e+00 1.401212e+00 1.637554e+00 0.794629
1.079287e+00 4.871440e+00 2.579814e+00 2.42574
1.955302e+00 7.147768e+00 1.649958e+00 2.42486
3.605452e+00 2.964771e+00 6.141513e+00 0.869295
1.264563e+00 4.527010e+00 7.683559e+00 3.22126
3.052403e+00 2.164106e+00 4.063642e+00 2.59043
3.692193e+00 2.494324e+00 2.210258e+00 2.13913
2.852117e-01 3.059171e+00 3.564207e+00 1.47113
3.504066e+00 1.695442e+00 3.241280e+00 3.12799
5.230998e+00 3.621177e+00 1.826625e+00 2.54821
2.186516e+00 7.019246e+00 2.380939e+00 2.75668
5.896008e+00 8.113252e-01 2.699909e+00 1.96998
1.600499e+00 6.078903e-01 6.275097e+00 2.73266
3.223911e+00 5.007212e+00 3.621158e+00 2.74928
4.378065e+00 2.250014e+00 2.513717e+00 2.39396
1.975736e+00 3.279492e+00 3.415449e+00 5.6483
4.072211e+00 3.610826e+00 4.769311e+00 7.30144
2.730053e+00 2.824707e+00 4.371346e+00 3.89428
2.445791e+00 4.732644e+00 3.240896e+00 4.13426
2.568956e+00 2.308963e+00 8.346409e-01 1.55292
1.592312e+00 1.645866e+00 2.721409e+00 1.70508
2.414212e+00 2.237220e+00 3.801339e+00 1.03436
3.353847e+00 9.960760e-01 4.782047e+00 3.84671
2.698268e+00 2.877385e+00 1.566577e+00 2.37692
1.386233e+00 2.048648e+00 1.194570e+00 2.5024
2.475873e+00 1.045929e+00 3.735935e+00 1.30203
2.856561e+00 1.425771e+00 2.695392e+00 1.3806
2.846854e+00 5.399904e+00 6.266968e+00 1.93239
4.869597e+00 1.569636e+00 4.274673e+00 3.27191
4.146875e+00 1.365716e+00 4.031667e+00 2.34779
7.719155e+00 2.658849e+00 1.494046e+00 1.71567
4.299784e+00 2.213185e+00 3.045752e+00 1.90713
2.294917e+00 1.262713e+00 2.936118e+00 2.06197
1.875087e+00 3.101973e+00 6.257766e+00 3.89381
3.213079e+00 2.554766e+00 3.176509e+00 3.10727
6.468477e+00 5.056296e+00 1.633412e+00 3.82899
2.792700e+00 5.022362e+00 7.243271e+00 4.40914
3.821107e+00 3.416549e+00 1.554790e+00 4.60884
2.517145e+00 2.794271e+00 5.920664e+00 3.83281
3.591145e+00 2.460295e+00 3.828974e+00 1.54799
3.221248e+00 1.945387e+00 4.447802e+00 2.0031
9.891492e-01 1.098953e+00 3.033176e+00 2.22816
1.853709e+00 2.429771e+00 2.978063e+00 2.23651
9.579459e+00 2.028599e+00 2.509751e+00 1.86011
1.909599e+00 3.183159e+00 6.595179e+00 1.71458
2.572681e+00 2.551908e+00 7.125384e+00 2.24529
2.881790e+00 2.501508e+00 1.129920e+00 1.46746
3.671077e+00 6.682502e+00 4.405794e+00 4.84685
3.293577e+00 2.514132e+00 1.408936e+00 2.5394
1.451196e+00 2.632279e+00 3.271479e+00 2.05364
4.184291e+00 6.530124e+00 3.058399e+00 4.67896
3.481900e+00 3.019852e+00 2.770868e+00 1.79308
9.049999e-01 3.451058e+00 2.938039e+00 3.05574
4.055653e+00 2.688796e+00 1.887670e+00 1.1077
1.076977e+00 1.678056e+00 1.761055e+00 2.37755
2.678227e+00 4.732665e+00 1.993789e+00 1.61402
2.755025e+00 2.634154e+00 2.227330e+00 1.71136
3.088988e+00 4.575729e+00 1.935710e+00 6.33811
2.000878e+00 3.597843e+00 2.450322e+00 8.15126
2.746277e+00 5.380933e+00 3.814996e+00 2.69053
7.847375e+00 7.148015e+00 2.466952e+00 3.156
3.261437e+00 3.724547e+00 1.796477e+00 2.7035
1.330813e+00 6.707674e-01 2.695014e+00 4.12267
4.493791e-01 1.288885e+00 2.367579e+00 2.2868
4.020752e+00 2.583969e+00 1.167962e+00 3.38481
4.643887e+00 3.003726e+00 1.427571e+00 3.23285
2.695786e+00 2.662904e+00 1.937228e+00 3.84411
4.590588e+00 4.819293e+00 1.391349e+00 5.6457
2.271765e+00 9.566677e-01 2.532769e+00 7.30805
4.347703e+00 1.380990e+00 1.865818e+00 1.61294
8.101306e+00 4.297118e+00 1.574103e+00 2.13363
2.080578e+00 1.181923e+01 4.908753e+00 3.29467
4.435576e+00 5.382291e+00 2.658990e+00 5.95379
4.279986e+00 5.802465e+00 1.750587e+00 3.24348
7.583504e-01 1.534875e+00 8.648290e-01 0.800769
2.060692e+00 2.369757e+00 7.450861e+00 2.48238
1.506635e+00 1.462386e+00 3.138898e+00 7.21028
3.681698e+00 1.739696e+00 3.856392e+00 1.85845
2.123130e+00 7.247386e-01 2.247476e+00 1.79869
1.935554e+00 1.915771e+00 7.759504e+00 2.97069
2.730087e+00 1.317219e+00 1.380430e+00 1.87731
2.966867e+00 6.678214e+00 5.145785e+00 0.976481
3.135821e+00 3.405912e+00 2.055097e+00 4.35264
5.974719e+00 4.856537e+00 2.238908e+00 2.61161
2.720935e+00 1.672036e+00 2.295760e+00 2.82574
5.385957e+00 3.356817e+00 3.058072e+00 2.00609
2.192349e+00 2.354963e+00 2.460035e+00 1.51233
3.745978e+00 1.118331e+00 1.254780e+00 1.02624
3.463346e+00 4.111640e+00 6.901155e+00 4.65443
2.306591e+00 9.567764e-01 4.227085e+00 5.41763
1.334880e+00 1.821775e+00 4.901148e+00 3.99905
3.717171e+00 4.171673e+00 2.229404e+00 4.6099
7.470399e-01 1.058921e+00 9.926443e+00 2.21285
4.073716e+00 2.773153e+00 1.594685e+00 3.17683
6.140131e+00 1.748451e+00 9.315060e-01 2.84753
1.303468e+00 2.034670e+00 5.483409e+00 2.14149
2.708225e+00 8.052183e+00 4.407786e+00 5.30582
1.610961e+00 3.390528e+00 2.344753e+00 6.635
4.718381e+00 1.282042e+00 3.935182e+00 1.5148
3.590432e+00 2.460955e+00 5.527822e+00 1.87673
4.570219e+00 1.726796e+00 3.286179e+00 1.86833
2.665379e+00 4.633968e+00 3.215418e+00 11.8457
5.702546e+00 4.063183e+00 2.518959e+00 2.30423
2.295809e+00 3.236241e+00 2.264191e+00 1.84782
2.765270e+00 3.550448e+00 3.140222e+00 1.40575
3.295379e+00 1.903086e+00 1.548134e+00 6.66509
2.774972e+00 2.172827e+00 4.987054e+00 2.26403
4.784434e+00 4.069548e+00 4.428735e+00 11.1005
1.840577e+00 1.711109e+00 2.153413e+00 10.6973
2.868710e+00 2.109883e+00 2.741946e+00 5.15916
8.854788e-01 4.832042e+00 4.201692e+00 3.62786
3.766674e+00 4.999042e+00 2.569938e+00 0.921282
2.700322e+00 3.557141e+00 2.419263e+00 4.28011
3.272646e+00 2.204892e+00 3.634561e+00 1.87997
2.983304e+00 2.292084e+00 1.147709e+00 5.81465
1.700480e+00 6.211184e+00 2.026233e+00 3.67572
1.519567e+00 9.424900e-01 3.561244e+00 4.12336
1.840696e+00 2.317934e+00 6.060179e+00 1.89123
1.720373e+00 4.646405e+00 5.475396e+00 2.12293
1.193030e+01 1.463597e+00 2.649639e+00 2.00111
3.859778e+00 6.043424e+00 2.248234e+00 3.40697
2.335237e+00 5.031142e+00 4.526379e+00 2.92357
2.451467e+00 2.506669e+00 3.622532e+00 2 1 6 2.50747
8.304961e-01 2.110459e+00 2.735457e+00 2.46836
2.036070e+00 3.770269e+00 2.866086e+00 1.73312
3.063747e+00 1.697008e+00 1.218750e+00 5.63006
2.345771e+00 2.756564e+00 2.958386e+00 2.96989
4.629916e+00 2.612240e+00 1.476521e+00 2.3564
3.561821e+00 1.910498e+00 3.722177e+00 7.8805
5.601491e+00 3.110286e+00 2.683279e+00 2.05194
3.662951e+00 6.267081e+00 6.011975e+00 3.36686
5.494719e+00 3.108410e+00 3.386063e+00 2.76565
5.105645e+00 2.498318e+00 4.562881e+00 1.6913
5.627059e+00 1.306599e+00 2.944986e+00 4.14043
2.716523e+00 2.287602e+00 8.619236e-01 3.16994
9.099832e+00 2.662265e+00 4.798414e+00 1.07115
2.230025e+00 2.151256e+00 3.884083e+00 3.10084
1.614047e+00 3.367665e+00 8.265723e+00 3.75101
9.444974e-01 5.453364e+00 2.618340e+00 1.2037
2.351116e+00 3.856289e+00 2.856166e+00 4.63925
3.351290e+00 1.401212e+00 1.637554e+00 0.794629
1.079287e+00 4.871440e+00 2.579814e+00 2.42574
1.955302e+00 7.147768e+00 1.649958e+00 2.42444
3.605035e+00 3.009374e+00 6.141930e+00 0.777784
1.275406e+00 4.437826e+00 7.683976e+00 3.29918
2.974479e+00 2.164523e+00 4.141565e+00 2.51251
3.691776e+00 2.439294e+00 2.260420e+00 2.13872
3.402411e-01 3.059588e+00 3.563790e+00 1.50487
3.504483e+00 1.640412e+00 3.241697e+00 3.07124
5.230581e+00 3.621594e+00 1.815782e+00 2.6374
2.231120e+00 7.019663e+00 2.391782e+00 2.7571
5.896425e+00 6.779550e-01 2.677140e+00 2.01459
1.678423e+00 5.832689e-01 6.274680e+00 2.59929
3.145988e+00 5.006794e+00 3.620740e+00 2.7497
4.378482e+00 2.172090e+00 2.514135e+00 2.43856
1.897812e+00 3.279909e+00 3.415866e+00 5.64872
4.072629e+00 3.611243e+00 4.724708e+00 7.30102
2.696316e+00 2.746783e+00 4.426376e+00 3.8947
2.534974e+00 4.733061e+00 3.241313e+00 4.13384
2.646879e+00 2.442333e+00 8.896703e-01 1.51918
1.458942e+00 1.612129e+00 2.854779e+00 1.57171
2.325028e+00 2.159296e+00 3.767602e+00 1.0681
3.353429e+00 1.085260e+00 4.871230e+00 3.93589
2.697851e+00 2.955308e+00 1.566995e+00 2.42153
1.331785e+00 2.126572e+00 1.121146e+00 2.59159
2.476290e+00 1.079666e+00 3.813858e+00 1.35706
2.856978e+00 1.336587e+00 2.617469e+00 1.46979
2.846437e+00 5.400321e+00 6.266551e+00 2.01032
4.869179e+00 1.624665e+00 4.274256e+00 3.27233
4.068951e+00 1.366133e+00 3.987064e+00 2.40282
7.719572e+00 2.692586e+00 1.583229e+00 1.74941
4.244755e+00 2.257789e+00 3.045335e+00 1.81794
2.349946e+00 1.317742e+00 2.891514e+00 2.06239
1.841350e+00 3.024049e+00 6.257349e+00 3.89423
3.212662e+00 2.465583e+00 3.087326e+00 3.19645
6.468894e+00 5.055879e+00 1.578383e+00 3.82941
2.847729e+00 5.021945e+00 7.242854e+00 4.40955
3.820690e+00 3.416132e+00 1.554373e+00 4.68676
2.595068e+00 2.783428e+00 5.921081e+00 3.78821
3.724515e+00 2.426557e+00 3.828557e+00 1.59259
3.265852e+00 1.944970e+00 4.448219e+00 1.9585
9.445455e-01 1.232323e+00 2.978147e+00 2.22774
1.720339e+00 2.340588e+00 3.055987e+00 2.18149
9.579876e+00 1.994862e+00 2.509334e+00 1.87095
1.987523e+00 3.216896e+00 6.594762e+00 1.65955
2.606418e+00 2.473984e+00 7.124966e+00 2.28989
2.748420e+00 2.446479e+00 1.129503e+00 1.42999
3.671495e+00 6.682085e+00 4.405377e+00 4.84643
3.293160e+00 2.569162e+00 1.408519e+00 2.53899
1.540380e+00 2.621436e+00 3.226875e+00 1.92026
4.184708e+00 6.529707e+00 3.003369e+00 4.67854
3.481483e+00 3.064456e+00 2.715839e+00 1.65971
9.387371e-01 3.506088e+00 2.938456e+00 3.03276
4.078405e+00 2.657386e+00 1.917555e+00 1.08471
1.106861e+00 1.646879e+00 1.738070e+00 2.40896
2.648342e+00 4.708156e+00 1.962380e+00 1.58413
2.784676e+00 2.658663e+00 2.196153e+00 1.74254
3.057578e+00 4.544319e+00 1.912959e+00 6.36928
2.025388e+00 3.620828e+00 2.473074e+00 8.11985
2.777687e+00 5.412343e+00 3.839506e+00 2.72194
7.815965e+00 7.179425e+00 2.498361e+00 3.13302
3.285946e+00 3.747298e+00 1.820987e+00 2.72801
1.361989e+00 6.393576e-01 2.672029e+00 4.09126
4.179693e-01 1.313394e+00 2.391855e+00 2.31668
3.997767e+00 2.559692e+00 1.197613e+00 3.35363
4.675296e+00 3.033610e+00 1.457455e+00 3.26426
2.664377e+00 2.631494e+00 1.961737e+00 3.81422
4.559179e+00 4.850702e+00 1.360172e+00 5.61429
2.240355e+00 9.252579e-01 2.510018e+00 7.33946
4.378880e+00 1.410641e+00 1.843067e+00 1.58176
8.069896e+00 4.327003e+00 1.549827e+00 2.15639
2.056068e+00 1.146796e+01 4.877343e+00 3.31742
4.404166e+00 5.413701e+00 2.683500e+00 5.9852
4.311396e+00 5.771055e+00 1.781996e+00 3.21207
7.895268e-01 1.566052e+00 8.960054e-01 0.823753
2.029282e+00 2.394033e+00 7.482271e+00 2.45249
1.482358e+00 1.439634e+00 3.161650e+00 7.24169
3.713107e+00 1.716944e+00 3.887802e+00 1.8288
2.153015e+00 7.559150e-01 2.278652e+00 1.77594
1.904378e+00 1.940047e+00 7.790913e+00 2.93928
2.761497e+00 1.287567e+00 1.350779e+00 1.90872
2.989619e+00 6.646804e+00 5.114376e+00 1.00613
3.104411e+00 3.374735e+00 2.077849e+00 4.38405
5.943310e+00 4.825128e+00 2.209023e+00 2.64149
2.752345e+00 1.695020e+00 2.271250e+00 2.85715
5.354547e+00 3.386702e+00 3.082582e+00 1.97644
2.223759e+00 2.384848e+00 2.428859e+00 1.48805
3.723227e+00 1.095346e+00 1.284664e+00 0.996356
3.438836e+00 4.080463e+00 6.869745e+00 4.62302
2.283606e+00 9.271250e-01 4.202575e+00 5.38622
1.366056e+00 2.007330e+00 4.605721e+00 3.70362
3.590079e+00 4.298765e+00 2.212184e+00 4.71374
5.726686e-01 1.354348e+00 5.606007e+00 2.08576
4.369144e+00 3.068581e+00 1.890112e+00 3.36239
6.435558e+00 1.812950e+00 9.887276e-01 2.66198
1.430561e+00 1.849116e+00 5.187982e+00 2.26859
2.581133e+00 8.347610e+00 4.703214e+00 5.12027
1.796515e+00 3.095101e+00 2.539749e+00 6.33957
4.422954e+00 1.209312e+00 3.639755e+00 1.4503
3.775987e+00 2.478175e+00 5.232395e+00 2.17216
4.274792e+00 2.022223e+00 3.581606e+00 1.5795
2.479825e+00 4.338540e+00 3.510846e+00 6.97194
5.407119e+00 4.358610e+00 2.646051e+00 2.29819
2.000382e+00 2.940814e+00 2.270227e+00 1.86504
2.644887e+00 3.654284e+00 3.435649e+00 1.11032
3.480934e+00 1.717532e+00 1.720605e+00 6.96052
2.949344e+00 2.190047e+00 4.691627e+00 2.36786
4.489007e+00 3.774121e+00 4.724163e+00 6.31289
1.655022e+00 1.525554e+00 2.088915e+00 6.17244
3.054264e+00 1.814455e+00 2.927500e+00 5.45459
1.048046e+00 4.536615e+00 4.497119e+00 3.33243
4.062101e+00 4.703615e+00 2.697030e+00 0.98578
2.683102e+00 3.551104e+00 2.233709e+00 4.57553
3.087091e+00 2.101056e+00 3.820115e+00 1.98381
2.687877e+00 2.587511e+00 1.020617e+00 6.11008
1.573388e+00 6.506611e+00 1.840679e+00 3.50135
1.693938e+00 1.128045e+00 3.457408e+00 4.41879
2.136123e+00 2.253435e+00 6.355607e+00 1.87401
1.847466e+00 4.350977e+00 5.371560e+00 2.01909
8.718572e+00 1.637969e+00 2.776731e+00 2.29653
3.876997e+00 5.747996e+00 2.312732e+00 3.11154
2.318018e+00 5.326570e+00 4.230952e+00 2.91753
2.176051e+00 2.610506e+00 3.917959e+00 Best total sum of distances = 1771.1
Create a silhouette plot for the four clusters.
[silh4,h] = silhouette(X,idx4,'cityblock'); xlabel('Silhouette Value') ylabel('Cluster')
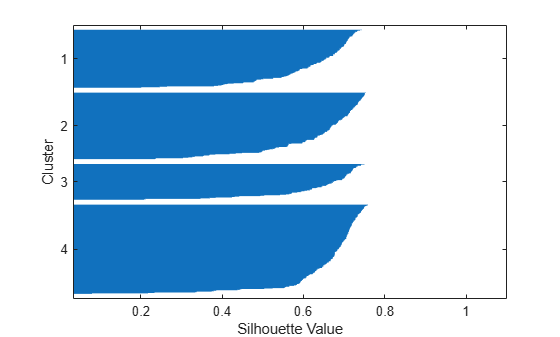
The silhouette plot indicates that these four clusters are better separated than the three clusters in the previous solution. You can take a more quantitative approach to comparing the two solutions by computing the average silhouette values for the two cases.
Compute the average silhouette values.
cluster3 = mean(silh3)
cluster3 = 0.5352
cluster4 = mean(silh4)
cluster4 = 0.6400
The average silhouette value of the four clusters is higher than the average value of the three clusters. These values support the conclusion represented in the silhouette plots.
Finally, find five clusters in the data. Create a silhouette plot and compute the average silhouette values for the five clusters.
idx5 = kmeans(X,5,'Distance','cityblock','Display','final');
Replicate 1, 7 iterations, total sum of distances = 2.507470.8304962.110462.735462.468362.036073.770272.866091.733123.063751.697011.218755.630062.345772.756562.958392.969894.629922.612241.476522.35643.561821.91053.722187.88055.601493.110292.683282.051943.662956.267086.011973.366865.494723.108413.386062.765655.105642.498324.562881.69135.627061.30662.944994.140432.716522.28760.8619243.169949.099832.662264.798411.071152.230032.151263.884083.100841.614053.367668.265723.751010.9444975.453362.618341.20372.351123.856292.856174.639253.351291.401211.637550.7946291.079294.871442.579812.425741.95537.147771.649962.424443.605043.009376.141930.7777841.275414.437837.683983.299182.974482.164524.141572.512513.691782.439292.260422.138720.3402413.059593.563791.504873.504481.640413.24173.071245.230583.621591.815782.63742.231127.019662.391782.75715.896420.6779552.677142.014591.678420.5832696.274682.599293.145995.006793.620742.74974.378482.172092.514132.438561.897813.279913.415875.648724.072633.611244.724717.301022.696322.746784.426383.89472.534974.733063.241314.133842.646882.442330.889671.519181.458941.612132.854781.571712.325032.15933.76761.06813.353431.085264.871233.935892.697852.955311.566992.421531.331792.126571.121152.591592.476291.079673.813861.357062.856981.336592.617471.469792.846445.400326.266552.010324.869181.624674.274263.272334.068951.366133.987062.402827.719572.692591.583231.749414.244762.257793.045331.817942.349951.317742.891512.062391.841353.024056.257353.894233.212662.465583.087333.196456.468895.055881.578383.829412.847735.021947.242854.409553.820693.416131.554374.686762.595072.783435.921083.788213.724522.426563.828561.592593.265851.944974.448221.95850.9445461.232322.978152.227741.720342.340593.055992.181499.579881.994862.509331.870951.987523.21696.594761.659552.606422.473987.124972.289892.748422.446481.12951.429993.671496.682094.405384.846433.293162.569161.408522.538991.540382.621443.226881.920264.184716.529713.003374.678543.481483.064462.715841.659710.9387373.506092.938463.032764.07842.657391.917551.084711.106861.646881.738072.408962.648344.708161.962381.584132.784682.658662.196151.742543.057584.544321.912966.369282.025393.620832.473078.119852.777695.412343.839512.721947.815977.179422.498363.133023.285953.74731.820992.728011.361990.6393582.672034.091260.4179691.313392.391852.316683.997772.559691.197613.353634.67533.033611.457463.264262.664382.631491.961743.814224.559184.85071.360175.614292.240360.9252582.510027.339464.378881.410641.843071.581768.06994.3271.549832.156392.0560711.4684.877343.317424.404175.41372.68355.98524.31145.771061.7823.212070.7895271.566050.8960050.8237532.029282.394037.482272.452491.482361.439633.161657.241693.713111.716943.88781.82882.153020.7559152.278651.775941.904381.940057.790912.939282.76151.287571.350781.908722.989626.64685.114381.006133.104413.374742.077854.384055.943314.825132.209022.641492.752341.695022.271252.857155.354553.38673.082581.976442.223762.384852.428861.488053.723231.095351.284660.9963563.438844.080466.869754.623022.283610.9271254.202585.386221.366061.416912.002551.048373.202663.209162.189823.510192.407591.283672.672333.175362.010030.9807961.285861.807994.076452.22081.401492.096131.753161.968262.254311.701282.178785.98852.34414.011612.227452.221181.382243.405892.549572.381752.225781.893572.221592.650542.7251.050031.341120.9917621.977671.360772.458681.564041.611624.038272.727351.99951.556441.899361.843232.179222.980962.377042.535683.058452.271191.823351.926543.087941.815814.60142.387962.480351.882441.164322.775911.876632.365053.379222.355162.825632.246963.238772.601041.337372.357123.095481.783881.680042.23070.8111371.702991.769941.672442.557753.01253.995942.144082.720221.88283.159272.265721.548461.388491.636432.110223.750972.333974.14752.164662.509511.093361.412262.118772.059681.436743.037834.00541.851642.508552.605254.032922.142125.78491.385293.218570.8601453.652472.814322.246780.3586292.750123.660821.904853.064961.920912.456592.3188. Best total sum of distances = 1647.26
[silh5,h] = silhouette(X,idx5,'cityblock'); xlabel('Silhouette Value') ylabel('Cluster')
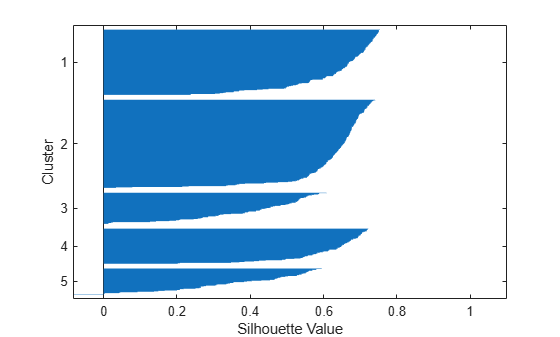
mean(silh5)
ans = 0.5721
The silhouette plot indicates that five is probably not the right number of clusters, because two clusters contain points with mostly low silhouette values, and the fifth cluster contains a few points with negative values. Also, the average silhouette value for the five clusters is lower than the value for the four clusters. Without knowing how many clusters are in the data, it is a good idea to experiment with a range of values for k, the number of clusters.
Note that the sum of distances decreases as the number of clusters increases. For example, the sum of distances decreases from 2459.98 to 1771.1 to 1647.26 as the number of clusters increases from 3 to 4 to 5. Therefore, the sum of distances is not useful for determining the optimal number of clusters.
Avoid Local Minima
By default, kmeans begins the clustering process using a randomly selected set of initial centroid locations. The kmeans algorithm can converge to a solution that is a local (nonglobal) minimum; that is, kmeans can partition the data such that moving any single point to a different cluster increases the total sum of distances. However, as with many other types of numerical minimizations, the solution that kmeans reaches sometimes depends on the starting points. Therefore, other solutions (local minima) that have lower total sums of distances can exist for the data. You can use the 'Replicates' name-value pair argument to test different solutions. When you specify more than one replicate, kmeans repeats the clustering process starting from different randomly selected centroids for each replicate, and returns the solution with the lowest total sum of distances among all the replicates.
Find four clusters in the data and replicate the clustering five times. Also, specify the city block distance metric, and use the 'Display' name-value pair argument to print the final sum of distances for each solution.
[idx4,cent4,sumdist] = kmeans(X,4,'Distance','cityblock', ... 'Display','final','Replicates',5);
Replicate 1, 2 iterations, total sum of distances = 2.507470.8304962.110462.735462.468362.036073.770272.866091.733123.063751.697011.218755.630062.345772.756562.958392.969894.629922.612241.476522.35643.561821.91053.722187.88055.601493.110292.683282.051943.662956.267086.011973.366865.494723.108413.386062.765655.105642.498324.562881.69135.627061.30662.944994.140432.716522.28760.8619243.169949.099832.662264.798411.071152.230032.151263.884083.100841.614053.367668.265723.751010.9444975.453362.618341.20372.351123.856292.856174.639253.351291.401211.637550.7946291.079294.871442.579812.425741.95537.147771.649962.424443.605043.009376.141930.7777841.275414.437837.683983.299182.974482.164524.141572.512513.691782.439292.260422.138720.3402413.059593.563791.504873.504481.640413.24173.071245.230583.621591.815782.63742.231127.019662.391782.75715.896420.6779552.677142.014591.678420.5832696.274682.599293.145995.006793.620742.74974.378482.172092.514132.438561.897813.279913.415875.648724.072633.611244.724717.301022.696322.746784.426383.89472.534974.733063.241314.133842.646882.442330.889671.519181.458941.612132.854781.571712.325032.15933.76761.06813.353431.085264.871233.935892.697852.955311.566992.421531.331792.126571.121152.591592.476291.079673.813861.357062.856981.336592.617471.469792.846445.400326.266552.010324.869181.624674.274263.272334.068951.366133.987062.402827.719572.692591.583231.749414.244762.257793.045331.817942.349951.317742.891512.062391.841353.024056.257353.894233.212662.465583.087333.196456.468895.055881.578383.829412.847735.021947.242854.409553.820693.416131.554374.686762.595072.783435.921083.788213.724522.426563.828561.592593.265851.944974.448221.95850.9445461.232322.978152.227741.720342.340593.055992.181499.579881.994862.509331.870951.987523.21696.594761.659552.606422.473987.124972.289892.748422.446481.12951.429993.671496.682094.405384.846433.293162.569161.408522.538991.540382.621443.226881.920264.184716.529713.003374.678543.481483.064462.715841.659710.9387373.506092.938463.032764.07842.657391.917551.084711.106861.646881.738072.408962.648344.708161.962381.584132.784682.658662.196151.742543.057584.544321.912966.369282.025393.620832.473078.119852.777695.412343.839512.721947.815977.179422.498363.133023.285953.74731.820992.728011.361990.6393582.672034.091260.4179691.313392.391852.316683.997772.559691.197613.353634.67533.033611.457463.264262.664382.631491.961743.814224.559184.85071.360175.614292.240360.9252582.510027.339464.378881.410641.843071.581768.06994.3271.549832.156392.0560711.4684.877343.317424.404175.41372.68355.98524.31145.771061.7823.212070.7895271.566050.8960050.8237532.029282.394037.482272.452491.482361.439633.161657.241693.713111.716943.88781.82882.153020.7559152.278651.775941.904381.940057.790912.939282.76151.287571.350781.908722.989626.64685.114381.006133.104413.374742.077854.384055.943314.825132.209022.641492.752341.695022.271252.857155.354553.38673.082581.976442.223762.384852.428861.488053.723231.095351.284660.9963563.438844.080466.869754.623022.283610.9271254.202585.386221.366062.007334.605723.703623.590084.298772.212184.713740.5726691.354355.606012.085764.369143.068581.890113.362396.435561.812950.9887282.661981.430561.849125.187982.268592.581138.347614.703215.120271.796523.09512.539756.339574.422951.209313.639751.45033.775992.478185.232392.172164.274792.022223.581611.57952.479824.338543.510856.971945.407124.358612.646052.298192.000382.940812.270231.865042.644893.654283.435651.110323.480931.717531.720616.960522.949342.190054.691632.367864.489013.774124.724166.312891.655021.525552.088916.172443.054261.814462.92755.454591.048054.536614.497123.332434.06214.703622.697030.985782.68313.55112.233714.575533.087092.101063.820121.983812.687882.587511.020626.110081.573396.506611.840683.501351.693941.128043.457414.418792.136122.253446.355611.874011.847474.350985.371562.019098.718571.637972.776732.296533.8775.7482.312733.111542.318025.326574.230952.917532.176052.610513.91796. Replicate 2, 3 iterations, total sum of distances = 2.507470.8304962.110462.735462.468362.036073.770272.866091.733123.063751.697011.218755.630062.345772.756562.958392.969894.629922.612241.476522.35643.561821.91053.722187.88055.601493.110292.683282.051943.662956.267086.011973.366865.494723.108413.386062.765655.105642.498324.562881.69135.627061.30662.944994.140432.716522.28760.8619243.169949.099832.662264.798411.071152.230032.151263.884083.100841.614053.367668.265723.751010.9444975.453362.618341.20372.351123.856292.856174.639253.351291.401211.637550.7946291.079294.871442.579812.425741.95537.147771.649962.424443.605043.009376.141930.7777841.275414.437837.683983.299182.974482.164524.141572.512513.691782.439292.260422.138720.3402413.059593.563791.504873.504481.640413.24173.071245.230583.621591.815782.63742.231127.019662.391782.75715.896420.6779552.677142.014591.678420.5832696.274682.599293.145995.006793.620742.74974.378482.172092.514132.438561.897813.279913.415875.648724.072633.611244.724717.301022.696322.746784.426383.89472.534974.733063.241314.133842.646882.442330.889671.519181.458941.612132.854781.571712.325032.15933.76761.06813.353431.085264.871233.935892.697852.955311.566992.421531.331792.126571.121152.591592.476291.079673.813861.357062.856981.336592.617471.469792.846445.400326.266552.010324.869181.624674.274263.272334.068951.366133.987062.402827.719572.692591.583231.749414.244762.257793.045331.817942.349951.317742.891512.062391.841353.024056.257353.894233.212662.465583.087333.196456.468895.055881.578383.829412.847735.021947.242854.409553.820693.416131.554374.686762.595072.783435.921083.788213.724522.426563.828561.592593.265851.944974.448221.95850.9445461.232322.978152.227741.720342.340593.055992.181499.579881.994862.509331.870951.987523.21696.594761.659552.606422.473987.124972.289892.748422.446481.12951.429993.671496.682094.405384.846433.293162.569161.408522.538991.540382.621443.226881.920264.184716.529713.003374.678543.481483.064462.715841.659710.9387373.506092.938463.032764.07842.657391.917551.084711.106861.646881.738072.408962.648344.708161.962381.584132.784682.658662.196151.742543.057584.544321.912966.369282.025393.620832.473078.119852.777695.412343.839512.721947.815977.179422.498363.133023.285953.74731.820992.728011.361990.6393582.672034.091260.4179691.313392.391852.316683.997772.559691.197613.353634.67533.033611.457463.264262.664382.631491.961743.814224.559184.85071.360175.614292.240360.9252582.510027.339464.378881.410641.843071.581768.06994.3271.549832.156392.0560711.4684.877343.317424.404175.41372.68355.98524.31145.771061.7823.212070.7895271.566050.8960050.8237532.029282.394037.482272.452491.482361.439633.161657.241693.713111.716943.88781.82882.153020.7559152.278651.775941.904381.940057.790912.939282.76151.287571.350781.908722.989626.64685.114381.006133.104413.374742.077854.384055.943314.825132.209022.641492.752341.695022.271252.857155.354553.38673.082581.976442.223762.384852.428861.488053.723231.095351.284660.9963563.438844.080466.869754.623022.283610.9271254.202585.386221.366062.007334.605723.703623.590084.298772.212184.713740.5726691.354355.606012.085764.369143.068581.890113.362396.435561.812950.9887282.661981.430561.849125.187982.268592.581138.347614.703215.120271.796523.09512.539756.339574.422951.209313.639751.45033.775992.478185.232392.172164.274792.022223.581611.57952.479824.338543.510856.971945.407124.358612.646052.298192.000382.940812.270231.865042.644893.654283.435651.110323.480931.717531.720616.960522.949342.190054.691632.367864.489013.774124.724166.312891.655021.525552.088916.172443.054261.814462.92755.454591.048054.536614.497123.332434.06214.703622.697030.985782.68313.55112.233714.575533.087092.101063.820121.983812.687882.587511.020626.110081.573396.506611.840683.501351.693941.128043.457414.418792.136122.253446.355611.874011.847474.350985.371562.019098.718571.637972.776732.296533.8775.7482.312733.111542.318025.326574.230952.917532.176052.610513.91796. Replicate 3, 3 iterations, total sum of distances = 2.507470.8304962.110462.735462.468362.036073.770272.866091.733123.063751.697011.218755.630062.345772.756562.958392.969894.629922.612241.476522.35643.561821.91053.722187.88055.601493.110292.683282.051943.662956.267086.011973.366865.494723.108413.386062.765655.105642.498324.562881.69135.627061.30662.944994.140432.716522.28760.8619243.169949.099832.662264.798411.071152.230032.151263.884083.100841.614053.367668.265723.751010.9444975.453362.618341.20372.351123.856292.856174.639253.351291.401211.637550.7946291.079294.871442.579812.425741.95537.147771.649962.424443.605043.009376.141930.7777841.275414.437837.683983.299182.974482.164524.141572.512513.691782.439292.260422.138720.3402413.059593.563791.504873.504481.640413.24173.071245.230583.621591.815782.63742.231127.019662.391782.75715.896420.6779552.677142.014591.678420.5832696.274682.599293.145995.006793.620742.74974.378482.172092.514132.438561.897813.279913.415875.648724.072633.611244.724717.301022.696322.746784.426383.89472.534974.733063.241314.133842.646882.442330.889671.519181.458941.612132.854781.571712.325032.15933.76761.06813.353431.085264.871233.935892.697852.955311.566992.421531.331792.126571.121152.591592.476291.079673.813861.357062.856981.336592.617471.469792.846445.400326.266552.010324.869181.624674.274263.272334.068951.366133.987062.402827.719572.692591.583231.749414.244762.257793.045331.817942.349951.317742.891512.062391.841353.024056.257353.894233.212662.465583.087333.196456.468895.055881.578383.829412.847735.021947.242854.409553.820693.416131.554374.686762.595072.783435.921083.788213.724522.426563.828561.592593.265851.944974.448221.95850.9445461.232322.978152.227741.720342.340593.055992.181499.579881.994862.509331.870951.987523.21696.594761.659552.606422.473987.124972.289892.748422.446481.12951.429993.671496.682094.405384.846433.293162.569161.408522.538991.540382.621443.226881.920264.184716.529713.003374.678543.481483.064462.715841.659710.9387373.506092.938463.032764.07842.657391.917551.084711.106861.646881.738072.408962.648344.708161.962381.584132.784682.658662.196151.742543.057584.544321.912966.369282.025393.620832.473078.119852.777695.412343.839512.721947.815977.179422.498363.133023.285953.74731.820992.728011.361990.6393582.672034.091260.4179691.313392.391852.316683.997772.559691.197613.353634.67533.033611.457463.264262.664382.631491.961743.814224.559184.85071.360175.614292.240360.9252582.510027.339464.378881.410641.843071.581768.06994.3271.549832.156392.0560711.4684.877343.317424.404175.41372.68355.98524.31145.771061.7823.212070.7895271.566050.8960050.8237532.029282.394037.482272.452491.482361.439633.161657.241693.713111.716943.88781.82882.153020.7559152.278651.775941.904381.940057.790912.939282.76151.287571.350781.908722.989626.64685.114381.006133.104413.374742.077854.384055.943314.825132.209022.641492.752341.695022.271252.857155.354553.38673.082581.976442.223762.384852.428861.488053.723231.095351.284660.9963563.438844.080466.869754.623022.283610.9271254.202585.386221.366062.007334.605723.703623.590084.298772.212184.713740.5726691.354355.606012.085764.369143.068581.890113.362396.435561.812950.9887282.661981.430561.849125.187982.268592.581138.347614.703215.120271.796523.09512.539756.339574.422951.209313.639751.45033.775992.478185.232392.172164.274792.022223.581611.57952.479824.338543.510856.971945.407124.358612.646052.298192.000382.940812.270231.865042.644893.654283.435651.110323.480931.717531.720616.960522.949342.190054.691632.367864.489013.774124.724166.312891.655021.525552.088916.172443.054261.814462.92755.454591.048054.536614.497123.332434.06214.703622.697030.985782.68313.55112.233714.575533.087092.101063.820121.983812.687882.587511.020626.110081.573396.506611.840683.501351.693941.128043.457414.418792.136122.253446.355611.874011.847474.350985.371562.019098.718571.637972.776732.296533.8775.7482.312733.111542.318025.326574.230952.917532.176052.610513.91796. Replicate 4, 6 iterations, total sum of distances = 12.33359.9739211.091610.116811.700510.187913.532612.580711.219112.853510.704410.77138.1630912.171811.45579.8538112.795914.45599.6384511.238811.47769.7562110.123212.32649.889067.9706610.418212.44569.5151813.42537.2736915.41889.27369.8963410.768712.716310.249114.86810.06114.32529.8808910.224410.9798.194249.6843810.12610.37459.6912610.432918.862112.424610.39059.7947712.0569.237947.192279.8355711.795813.549418.02813.513310.538115.215712.89.2484611.52888.301189.2878714.401612.558510.48410.101410.28399.737857.5376310.087512.188111.936816.910110.36531.28121.444461.831823.83261.925682.380063.395055.132271.988752.181191.207142.831132.089161.423251.591542.444650.7232572.150871.090921.695891.466191.581991.559561.409812.256783.603791.069882.374381.208032.467874.467952.604762.102963.644632.244252.350491.438651.624111.685264.006152.598813.160072.738262.371721.146511.826772.26220.7026322.132622.337491.779910.9564373.097012.218471.30473.498485.032492.964442.544744.027841.913471.852372.181351.181191.865312.250652.583972.095372.131282.277832.187932.641352.349061.458941.70354.192652.360892.416141.555223.439462.504121.483641.958011.015611.369441.403892.055161.507512.609891.946592.01872.57961.996211.985351.562442.169661.534322.224952.848614.125321.730762.600651.012742.204720.7206213.398822.455232.760842.275185.167862.851322.191711.866622.699762.19061.917081.423951.67311.319272.311811.072962.26642.464313.988821.727231.762212.279623.296512.622174.450763.416632.272631.784932.075882.753415.01392.131751.822361.185990.8665873.376332.113692.954213.369373.228424.064962.851611.5732.433752.020590.9577251.896511.055891.641262.236582.422952.041432.435652.112442.402141.371627.028172.388311.248162.211381.645112.871284.326231.761212.338291.931564.856442.261392.961852.292921.139032.275561.980744.413562.789162.57791.024631.879920.8612971.664762.583162.600082.000652.473681.6334.649411.458382.566771.343312.610781.428492.244142.156612.548462.455032.829382.99012.378763.13991.729052.329211.716221.534693.631311.4264.504781.347640.9666442.715343.752922.991482.456372.344163.321973.001276.299943.210953.82422.618236.897514.000036.634695.061853.944296.593628.401773.720713.118053.489322.658992.872313.632082.225950.8828163.319422.922281.022671.868071.303553.539033.794393.6481.768263.422975.897644.255962.67984.48661.991481.409152.165113.123423.336836.073052.2654.391941.1681.542493.598338.56184.953921.530273.065412.230056.847555.549352.671972.185062.2427911.46754.366762.229123.181826.636053.901067.207545.533744.548713.004341.989721.254471.496712.088621.881631.692231.305738.704622.331792.570672.527942.617058.464034.935452.805255.110151.898143.375360.9778493.264722.864252.684771.436129.013262.44463.983841.704511.420123.131071.901315.424463.892031.229182.825833.444072.051535.60644.720963.602781.873483.863843.974692.436382.067874.07954.13224.609053.285962.745673.44613.607193.481222.576364.811530.891972.507010.4076293.235464.14985.64743.400672.942361.605714.800314.289742.029511.808715.022014.119913.653584.235262.408924.747940.9184210.9380626.022292.149263.952862.65231.473832.904876.019271.437680.9252253.11951.367062.306645.604272.205082.644647.931324.286935.577791.3393.511392.408346.755854.839241.1444.056041.837293.318472.374675.648681.755874.691081.605943.165321.989192.937344.754833.094567.388235.82343.942322.582552.291162.416673.35712.277261.76032.701683.688493.019361.526613.023412.175051.635656.544232.603592.085315.107912.402074.905294.190414.307886.729182.112541.983072.47596.588732.781192.230742.537285.03830.7022944.95294.080833.748713.645825.11992.633530.7536962.921783.544072.691234.159253.544612.066853.36262.018013.104162.199141.084125.693791.636896.090332.29823.84711.348190.6705253.620344.00251.719842.640425.939321.99731.783964.767265.337361.984899.134861.292222.713231.880253.772266.164281.925753.527832.422754.910284.647242.91052.572332.644713.50167. Replicate 5, 2 iterations, total sum of distances = 2.507470.8304962.110462.735462.468362.036073.770272.866091.733123.063751.697011.218755.630062.345772.756562.958392.969894.629922.612241.476522.35643.561821.91053.722187.88055.601493.110292.683282.051943.662956.267086.011973.366865.494723.108413.386062.765655.105642.498324.562881.69135.627061.30662.944994.140432.716522.28760.8619243.169949.099832.662264.798411.071152.230032.151263.884083.100841.614053.367668.265723.751010.9444975.453362.618341.20372.351123.856292.856174.639253.351291.401211.637550.7946291.079294.871442.579812.425741.95537.147771.649962.424443.605043.009376.141930.7777841.275414.437837.683983.299182.974482.164524.141572.512513.691782.439292.260422.138720.3402413.059593.563791.504873.504481.640413.24173.071245.230583.621591.815782.63742.231127.019662.391782.75715.896420.6779552.677142.014591.678420.5832696.274682.599293.145995.006793.620742.74974.378482.172092.514132.438561.897813.279913.415875.648724.072633.611244.724717.301022.696322.746784.426383.89472.534974.733063.241314.133842.646882.442330.889671.519181.458941.612132.854781.571712.325032.15933.76761.06813.353431.085264.871233.935892.697852.955311.566992.421531.331792.126571.121152.591592.476291.079673.813861.357062.856981.336592.617471.469792.846445.400326.266552.010324.869181.624674.274263.272334.068951.366133.987062.402827.719572.692591.583231.749414.244762.257793.045331.817942.349951.317742.891512.062391.841353.024056.257353.894233.212662.465583.087333.196456.468895.055881.578383.829412.847735.021947.242854.409553.820693.416131.554374.686762.595072.783435.921083.788213.724522.426563.828561.592593.265851.944974.448221.95850.9445461.232322.978152.227741.720342.340593.055992.181499.579881.994862.509331.870951.987523.21696.594761.659552.606422.473987.124972.289892.748422.446481.12951.429993.671496.682094.405384.846433.293162.569161.408522.538991.540382.621443.226881.920264.184716.529713.003374.678543.481483.064462.715841.659710.9387373.506092.938463.032764.07842.657391.917551.084711.106861.646881.738072.408962.648344.708161.962381.584132.784682.658662.196151.742543.057584.544321.912966.369282.025393.620832.473078.119852.777695.412343.839512.721947.815977.179422.498363.133023.285953.74731.820992.728011.361990.6393582.672034.091260.4179691.313392.391852.316683.997772.559691.197613.353634.67533.033611.457463.264262.664382.631491.961743.814224.559184.85071.360175.614292.240360.9252582.510027.339464.378881.410641.843071.581768.06994.3271.549832.156392.0560711.4684.877343.317424.404175.41372.68355.98524.31145.771061.7823.212070.7895271.566050.8960050.8237532.029282.394037.482272.452491.482361.439633.161657.241693.713111.716943.88781.82882.153020.7559152.278651.775941.904381.940057.790912.939282.76151.287571.350781.908722.989626.64685.114381.006133.104413.374742.077854.384055.943314.825132.209022.641492.752341.695022.271252.857155.354553.38673.082581.976442.223762.384852.428861.488053.723231.095351.284660.9963563.438844.080466.869754.623022.283610.9271254.202585.386221.366062.007334.605723.703623.590084.298772.212184.713740.5726691.354355.606012.085764.369143.068581.890113.362396.435561.812950.9887282.661981.430561.849125.187982.268592.581138.347614.703215.120271.796523.09512.539756.339574.422951.209313.639751.45033.775992.478185.232392.172164.274792.022223.581611.57952.479824.338543.510856.971945.407124.358612.646052.298192.000382.940812.270231.865042.644893.654283.435651.110323.480931.717531.720616.960522.949342.190054.691632.367864.489013.774124.724166.312891.655021.525552.088916.172443.054261.814462.92755.454591.048054.536614.497123.332434.06214.703622.697030.985782.68313.55112.233714.575533.087092.101063.820121.983812.687882.587511.020626.110081.573396.506611.840683.501351.693941.128043.457414.418792.136122.253446.355611.874011.847474.350985.371562.019098.718571.637972.776732.296533.8775.7482.312733.111542.318025.326574.230952.917532.176052.610513.91796. Best total sum of distances = 1771.1
In replicate 4, kmeans finds a local minimum. Because each replicate begins from a different randomly selected set of initial centroids, kmeans sometimes finds more than one local minimum. However, the final solution that kmeans returns is the one with the lowest total sum of distances over all replicates.
Find the total of the within-cluster sums of point-to-centroid distances for the final solution returned by kmeans.
sum(sumdist)
ans = 1.7711e+03
See Also
Cluster
Data | kmeans | silhouette