Feature Extraction for Identifying Condition Indicators | Predictive Maintenance, Part 2
From the series: Predictive Maintenance
Melda Ulusoy, MathWorks
Condition indicators help you better understand your data by distinguishing healthy and faulty states of a machine. You can derive condition indicators from data using time-domain, frequency-domain, and time-frequency domain features.
This video uses a triplex pump example to walk through the predictive maintenance workflow and identify condition indicators. The first step of the algorithm is to collect pressure data representing both healthy and faulty states. The raw measurements are then preprocessed by cleaning up the noise. Preprocessing helps to convert the raw data to a form from which condition indicators can be extracted. Next, different features are investigated to see if they uniquely set apart the differences between different fault types. After extracting condition indicators, a machine learning model is trained with the selected set of features and the performance of the trained model is evaluated using a confusion matrix.
Published: 10 Jan 2019
Predictive Maintenance, Part 2: Feature Extraction for Identifying Condition Indicators
In this video, we’re going to talk about condition indicators, what they are, why they are important, and how to select them. Let’s start with a visual exercise. What is the difference between these two shapes? It looks like there isn’t any significant difference because both circles look almost the same. However, if we look at them from a different angle, we clearly see the differences and can identify them as a cylinder and a cone. Similarly, when you look at raw measurement data from your machine, it’s hard to tell apart healthy operation from faulty. But, using condition indicators, we’re able to look at the data from a different perspective that helps us discriminate between healthy and faulty operation.
You can derive condition indicators from data by using time, frequency, and time-frequency domain features. Time-domain features include the mean, standard deviation, skewness, and other features listed here. Frequency-domain features can also serve as condition indicators and help diagnose faults. For example, if we look at the vibration data from this machine in time-domain, we see the combined effect of all the vibrations from different rotating components. By analyzing the data in frequency domain, we can isolate different sources of vibration. The peak values and how much they change from nominal values can indicate the severity of the faults. Here are some of the other frequency-domain features that can serve as condition indicators. Another way to extract features is to look at the data in time-frequency domain, which helps characterize changes in the spectral content of a signal over time. For additional features, please check out the links given in the video description.
This is the predictive maintenance workflow that we discussed in the previous video. Now, we’re going to use a triplex pump example and follow these steps to identify condition indicators that are also referred to as features. Before we continue, let’s clarify why we really need these features. Once we identify some useful features, we use them to train a machine learning model. If the selected set of features are good, meaning they uniquely define healthy operation and different fault types, when we feed new data from the machine to the model, the model can correctly estimate the machine’s current condition. However, if the features are not distinctive, the trained model may estimate inaccurately.
Let’s see how we can extract some useful features for the pump. This animation shows how the pump works. A motor turns the crankshaft that drives three plungers. The fluid gets sucked here and discharged here where the pressure is measured by a sensor. Some of the faults that can develop in such a pump include seal leakage, blocked inlet, and worn bearing. This plot shows the pressure data that has been collected for one second at steady state. It includes measurements from normal operation, all three fault types, and also their combinations. We first need to preprocess this data and bring it to a form from which we can extract condition indicators. The raw data is noisy and has spikes up to the sensor’s maximum value. It’s also offset in time even though the durations of the measurements are the same. After cleaning up the noise and removing the offset, this is how the preprocessed data looks like. Now, this data includes all these conditions, but we can show them on separate plots to investigate different fault types and their combinations. The first thing we notice here is the cyclical behavior of the time-domain pressure signal. We can zoom in to better see what’s happening in each cycle. On each plot, the nominal values are shown with black, and the colored lines represent faulty operation. Now the question is: Can we distinguish the black line, the healthy operation, from the rest of the data on each plot, and can we also identify the unique differences between each set of colored lines? As you see here, the pressure data looks very similar for these two faults. Let’s use some of the time-domain features to identify condition indicators. Initially, you don’t know which features will do the best job of revealing the differences between fault types. Therefore, in this part you follow a trial-and-error method until you find some useful features you can work with. The first set of features that we’ll try are shown on the screen. One way to understand if these condition indicators can differentiate different types of faults is to investigate them using a boxplot.
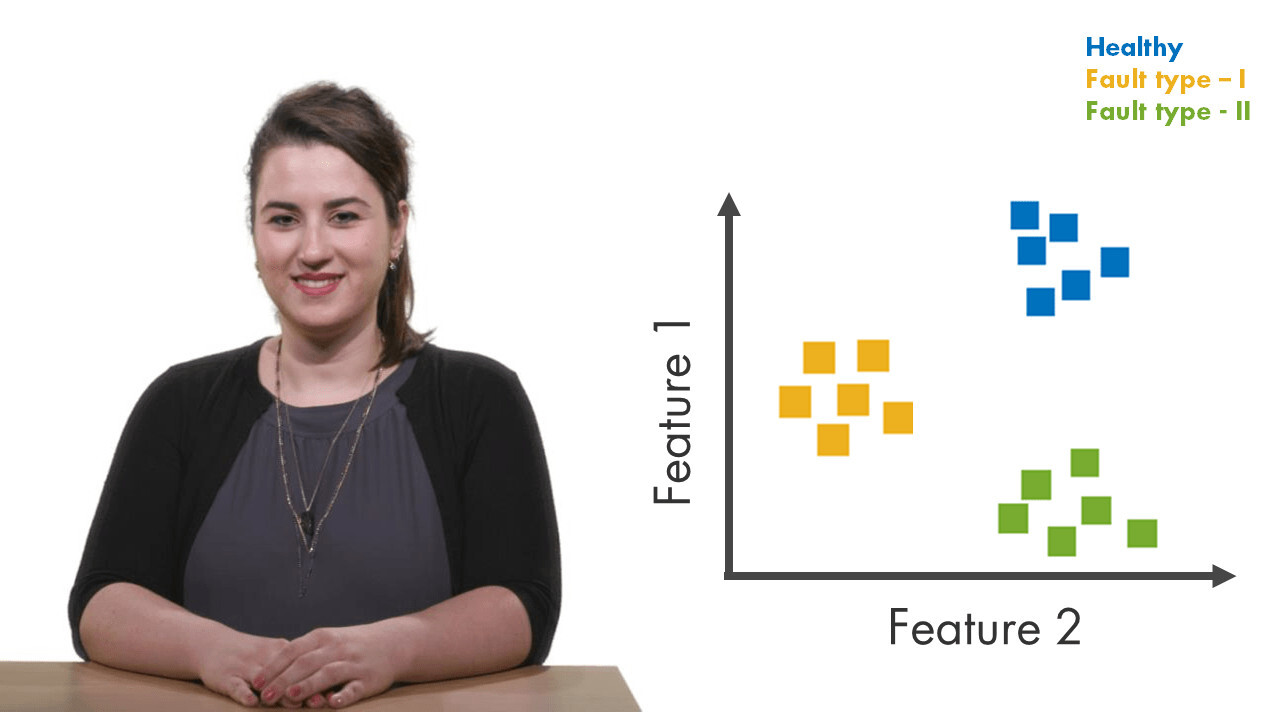
First, we will only look at a single feature, the mean, for the healthy condition and blocked inlet fault. On the plot, the boxes don’t overlap. What this means is that there’s a difference between these data groups. By using the mean, we can easily distinguish the blocked inlet fault from healthy condition. However, things change when we keep adding the data sets for other fault types as well. We’re not able to distinguish between the fault types as some of them overlap. If we try this with other features as well, we end up having the same conclusion: A single condition indicator is not sufficient to classify the faulty behavior, especially when you have multiple faults. Therefore, now we’re going to look at a scatter plot of two features, the mean and the variance. We immediately see that with two condition indicators we can better separate different faults. As we did here, you can try different pairs of features to see which ones are better at classifying faults.
As we discussed earlier, frequency-domain analysis is important in analyzing periodic data and data acquired from a machine with rotating components. Therefore, now we will further investigate our data in frequency-domain to see if we can extract some additional features. What differentiates these plots from each other are the peaks and the peak frequencies and therefore these can serve as condition indicators. Let’s bring back the plots we used for time-domain analysis. It was hard to distinguish these two faults from each other because of the similarity of the data sets. But by looking at the data from a different perspective now, we see that the peak values at this frequency range will help us successfully separate these two faults. After selecting these frequency-domain features, I did a similar analysis as we did with the time-domain features. And I observed that the selected features are distinctive and good candidates for training a machine learning model. Note that when we’re investigating these features, we’re not only looking for different clusters but we also want them to be further away from each other because this way the trained models can better identify which cluster a new data point will belong to.
After extracting the condition indicators, a machine learning model can be trained with the extracted features and the accuracy of the trained model can be checked with a confusion matrix, like this one. On the diagonal entries, the plot shows how many times the fault combinations are correctly predicted. And the off-diagonal values show the incorrect predictions.
Now that we’ve discussed feature extraction, you may be wondering how many features are good enough to train a machine learning model. Unfortunately, there’s no magic number that I can give you. You may have only a few features that are distinctive and you really understand well. But the beauty of machine learning is that it can use a large set of features to classify the data. Therefore, your model can benefit from a high-dimensional set of features.
In this video, we’ve discussed how condition indicators help us distinguish healthy condition from faulty and also different types of faults. We also showed an example where we extracted condition indicators using signal-based methods. In the next video, we’ll talk about remaining useful life estimation. Don’t forget to check out the description below for more resources and links on how to develop predictive maintenance algorithms with MATLAB and Simulink.
Related Products
Learn More











Seleziona un sito web
Seleziona un sito web per visualizzare contenuto tradotto dove disponibile e vedere eventi e offerte locali. In base alla tua area geografica, ti consigliamo di selezionare: United States.
Puoi anche selezionare un sito web dal seguente elenco:
Americhe
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)