How to Use Diagnostic Feature Designer for Feature Extraction | Predictive Maintenance, Part 4
From the series: Predictive Maintenance
Melda Ulusoy, MathWorks
Learn how you can extract time-domain and spectral features using Diagnostic Feature Designer for developing your predictive maintenance algorithm.
There are hundreds of features you can extract from your data. How do you know which features are useful for training a machine learning model? Although these models can work with a high-dimensional set of features, these features need to be distinctive so the model can make accurate predictions and effectively separate different types of groups. In this video, we’ll discuss how you can extract useful features with the Diagnostic Feature Designer for a triplex pump, and train machine learning models with Classification Learner for fault classification.
Published: 5 Apr 2019
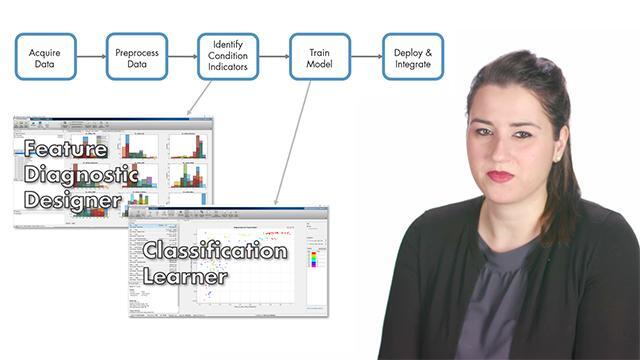
In this video, we’ll design a predictive maintenance algorithm for a triplex pump. We’ll demonstrate feature extraction using the Diagnostic Feature Designer and train machine learning models with Classification Learner.
Let’s use the triplex pump example that we’ve introduced in the Part 2 video. We want to make sure the pump runs safely and properly. But we know it may develop these faults as it operates over time. So we want to design a predictive maintenance algorithm to timely detect faults and also identify fault types, as this will help us figure out what parts need to be fixed or replaced and schedule maintenance accordingly.
Where do we start? We first collect data from the pump and preprocess it to clean up the noise. In the next steps of the algorithm, we extract features from the data with which we train machine learning models. These models then help us classify different fault types. This is where things get challenging. Why? Because there are hundreds of features we can extract from our data. So how do we know which features to choose? What we know is that machine learning models aren’t smart by default and they won’t predict different fault types accurately if we fail to train them with useful and distinctive features. So how do we determine if a feature is good or bad? In this video, we’ll try to answer these questions and give you insights into feature extraction.
Let’s start with the first step of the workflow. We collected flow and pressure measurements from the pump under different fault conditions. These are stored in an ensemble. In every row, there are 1.2 seconds long flow and pressure measurements and fault codes corresponding to different fault types. This data has already been preprocessed. So, we’ll continue with feature extraction using Diagnostic Feature Designer by following these steps. We start by importing the data into the app. Once imported, we can visualize the signals. Here’s how all the measurements look like for the flow signal. On these plots, different colors correspond to different fault types. As you see here, there are no clear differences between different types of faults. That’s why we need to extract features which will help us set different fault types apart. This app lets us compute commonly used time- and frequency-domain features. We select the flow data and compute statistical time-domain features. These are features such as the mean, standard deviation, skewness, and kurtosis. Once the app computes the feature values, they are displayed on the feature table. The app also plots histograms for each feature. Before we discuss how we can interpret these histograms, we will extract some additional features by analyzing our data in frequency-domain.
Why do we need more features? We know that machine learning models can work with a large set of features, and when trained with many features, they can do better predictions. However, this is only true if we have useful and distinctive features that can uniquely set different fault types apart. To understand this better, let’s look at the example my colleague Loren Shure uses in her “What is Machine Learning?” video. There are cards labeled with three categories: a dog, a cat, or a bird. You need to determine features that help distinguish between the different animals. Then you use these features to train a model that determines whether something gets labeled as a dog, a cat, or a bird. A good feature to have would be ears. Why? Because it immediately separates the group of dogs and cats from the group of birds. However, by itself this feature is not enough, as there may be dogs and cats whose ears may look similar in size and shape. Therefore, we add additional features such as mouth, nose, and whiskers. These are useful and distinctive features that will help us distinguish different animals. But imagine what would happen if we picked eye color as a feature. Dogs, cats, and birds can all share the same eye color and therefore this feature is not distinctive for separating different animals. These kinds of features will act as noise to our machine learning model and can even hurt the model’s performance and lead to inaccurate predictions. Because of what we just discussed, we’ll now extract some additional features and then we’ll rank all the extracted features to determine the most useful ones for training a machine learning model.
So far, we computed only time-domain features from the pump data. But these features alone may not be enough to distinguish normal from healthy operation. This was the case with the previous example where ears alone were not enough to distinguish between different animals. We know that the pump has rotating components, and its data is periodic. Therefore, frequency-domain analysis can reveal some significant differences between normal and healthy operation which can help us separate fault types better. So, now we’ll continue with extracting additional frequency-domain features. For this, we’ll first need to compute the power spectrum of the flow signal. There are parametric and non-parametric options to compute the spectra. You can try them out to see which one works best for your signal. Here, we’ll go with the autoregressive model as I tried out these options and I know the autoregressive model works well. On the spectrum plot, we notice that different types of faults are more separable when compared to time-domain signal. For example, we can easily set apart the red and green curves corresponding to these faults.
Now we’re ready to compute spectral features. The most commonly used features are listed here. These are features such as spectral peaks, modal coefficients, and band power. Here, we won’t keep the whole frequency band, but we’ll select a smaller range such that it includes the first five peaks. Why? Because the data at higher frequencies is noisy and it’s harder to distinguish the spectral peaks. Therefore, any features extracted from this part of the plot probably won’t contribute to better classification when we train machine learning models. Remember, if we fail to select useful features, we may hurt our machine learning model’s performance in making correct predictions.
So far, we identified time- and frequency-domain features from the flow data. I repeated the same process with the pressure data where I extracted additional features. It’s good to have many features as machine learning models can work a with high-dimensional set of features. All the computed features are now listed on the left and here we also have the histograms. On these plots, different fault types are highlighted with different colors. Ideally, we want to have a plot that looks like this. Here, all different colored distributions are apart from each other. If our histogram plots looked like this, we could easily discriminate between different types of faults. But instead they look similar to this one, where there’s a lot of overlapping between different fault types. Due to this overlapping and a large number of features, it is really hard for us to tell the most useful features just by looking at these plots. However, this app lets you rank these features to determine the ones that will help us effectively separate different types of faults.
When we click “Rank Features,” the app uses one-way ANOVA to calculate ranking scores for all the features. The results of the ANOVA test are displayed on the right-hand side, whereas the bars on the left shows the normalized scores for different features. For training a machine learning model, we will choose features that have a high ANOVA score and leave out the ones with a much smaller score as these won’t contribute to training a model. When you’re extracting features to train a model, you’ll find yourself trying out different sets of features to see which set works best for classifying fault types. Therefore, these steps are likely to be iterative when you’re designing your algorithm.
Now we’re ready to export the extracted features to the Classification Learner to train a machine learning model. The app imports all the features along with the fault codes. We can visualize different features with respect to each other and see how they can classify faults. Different fault codes are shown with different colors. Now, we’re going to train all available classifier types, which are displayed on the left panel. We get the highest accuracy with this classifier. To evaluate the performance of this trained model, we can also look at the confusion matrix that shows us accurate and inaccurate predictions. We see that the trained model estimated most of the fault types with a high accuracy. But there were cases where it estimated poorly. One of the reasons may be that the data for normal and faulty condition for these fault types are very similar and therefore hard to distinguish from each other. But it can be also due to the set of features we selected. As we mentioned before, this part of the algorithm is iterative. If we’re not satisfied with the performance of the trained model, we need to go back and select a different set of features and evaluate the performance of this new model.
In this video, we’ve seen how you can extract features using the Diagnostic Feature Designer for developing your predictive maintenance algorithm. We also discussed how you can train a machine learning model using Classification Learner. Don’t forget to check out our previous videos in this series, and the product page to learn more on how you can develop your predictive maintenance algorithm with MATLAB and Simulink.
Featured Product
Predictive Maintenance Toolbox










Seleziona un sito web
Seleziona un sito web per visualizzare contenuto tradotto dove disponibile e vedere eventi e offerte locali. In base alla tua area geografica, ti consigliamo di selezionare: United States.
Puoi anche selezionare un sito web dal seguente elenco:
Americhe
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)