Speech Transcription and Synthesis
Audio Toolbox™ provides examples for small-vocabulary recognition and
sound synthesis. Use pretrained models to perform general speech-to-text
transcription and text-to-speech synthesis with speech2text and text2speech. You can download Audio Toolbox extended functionality from File Exchange for text-to-speech and speech-to-text through interfaces to popular third-party
APIs. Supported APIs include Google®, IBM® Watson, Microsoft® Azure, and Amazon®.
You can interact with speech-to-text functionality graphically in the Signal Labeler app to quickly label regions of speech.
Apps
| Signal Labeler | Label signal attributes, regions, and points of interest |
Functions
speech2text | Transcribe speech signal to text (Since R2022b) |
text2speech | Synthesize speech from text (Since R2022b) |
speechClient | Interface with pretrained model or third-party speech service (Since R2022b) |
identifyLanguage | Identify languages in speech signals (Since R2024b) |
Topics
- Label Spoken Words in Audio Signals
Use Signal Labeler to label spoken words in an audio signal.
- Speaker Diarization Using Pretrained AI Models
Use the
speakerEmbeddingsfunction to extract compact speaker representations and perform speaker diarization. (Since R2024b)
Featured Examples
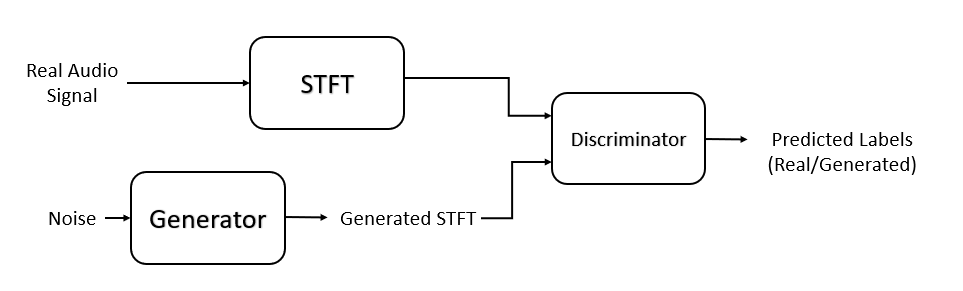
Train Generative Adversarial Network (GAN) for Sound Synthesis
Train and use a generative adversarial network (GAN) to generate sounds.
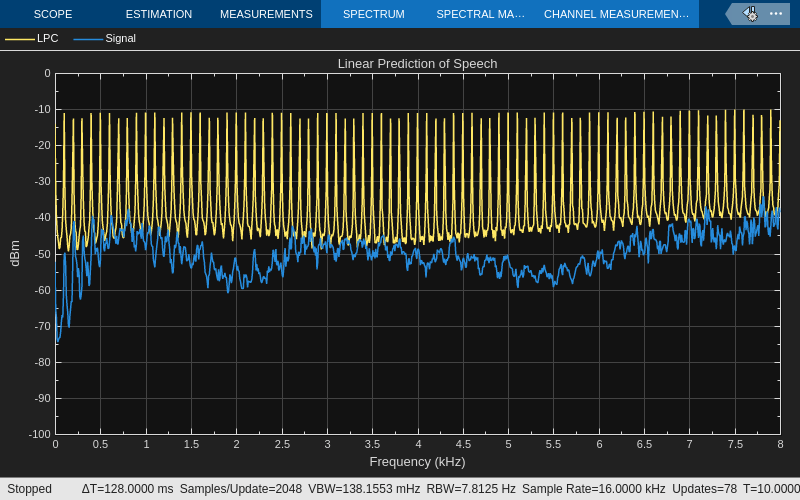
LPC Analysis and Synthesis of Speech
Use the Levinson-Durbin and Time-Varying Lattice Filter blocks for low-bandwidth transmission of speech using linear predictive coding.