Resize Clusters Automatically
Your cluster can resize automatically based on the amount of work submitted to the cluster.
To enable automatic resizing, select the option Allow cluster to auto-resize on the Create Cluster page. Specify the maximum number of workers that you require in the cluster using the Upper Limit menu next to Workers in Cluster. To ensure that all machines are started with the same number of workers, the Upper Limit menu options are multiples of the Workers per Machine value.
Based on your Upper Limit selection and the Workers per Machine value, the Machines in Cluster field displays the maximum number of machines for your cluster, including the headnode machine. Your cluster will not auto-resize above the number of machines displayed in the Machines in Cluster field or the number of workers specified by Workers in Cluster.
Note
Set the Workers in Cluster field to a maximum cluster size you want to use, ensuring that you are prepared to pay for the corresponding number of machines.
You can view the maximum number of workers and current requested number of workers on the
Cluster Summary page in Cloud Center. You can also view these properties from your cluster
object in MATLAB®, using the properties
MaxNumWorkers and NumWorkersRequested. For more
information, see parallel.Cluster (Parallel Computing Toolbox).
Tip
To avoid your cluster shutting down when all workers become idle and no jobs are in the queue, set the termination policy of your cluster to a After a fixed time period or Never. Your cluster will remain online with only the dedicated headnode machine until more jobs are submitted or the cluster times out.
Cluster Growing and Shrinking
Your cluster starts with the headnode machine and zero worker machines. When you submit jobs to the cluster, the cluster grows to accommodate the next queued job by adding machines, up to the maximum number set when you created the cluster. The cluster continues to grow until it either runs out of queued jobs or the upper limit for the number of workers prevents it from growing to accommodate the next queued job. Workers are added in increments of Workers per Machine.
As workers become available, they can be assigned to the next job in the queue. A queued job is scheduled as soon as there are enough available workers to run the job.
Machines no longer in use are removed from the cluster. If even one worker on a machine is busy, that machine will not be removed until all workers on the machine are idle. Cloud Center checks for idle workers every five minutes and removes machines which are idle for at least five minutes. It can take up to 15 minutes to remove a machine when all workers on that machine become idle. Your cluster can be reduced to zero workers when no jobs are running. In this case, only the headnode remains in the cluster.
Distributing Jobs Across Machines
Workers on a new machine or from a finishing job do not necessarily become available to the cluster at the same time. The cluster schedules jobs to idle workers as soon as the minimum requirements of the job are met. Consequently, as running jobs finish and queued jobs start on the cluster, jobs can be distributed across several machines. In such cases, you can find that even though the number of active workers in your cluster corresponds to a smaller number of machines than your cluster is currently using, the cluster does not shrink as there are active workers on each machine.
The following example shows one of several ways that the cluster can distribute these jobs among workers. The actual distribution depends on the order in which workers become available on new machines and after jobs finish running. Suppose you create a cluster with a maximum of 16 workers, with four workers per machine. The cluster starts with zero workers. You submit four jobs: one six-worker job, two four-worker jobs, and one five-worker job. The jobs finish in the order they are submitted.
First, the cluster grows to six workers on two machines to run the first, six-worker job. To run the second job, the cluster needs two additional workers. A third machine is requested to provide the additional workers. The job is assigned to the two free workers on the existing machine and two workers on the new machine. Similarly, two additional workers are required to run the third job, so the cluster requests a fourth machine. Now, 14 out of 16 workers on four machines are in use. There are not enough workers available to run the final, five-worker job. This job remains in the queue while the first three jobs run.

When the first job finishes, the six workers that ran the job become idle. They do not necessarily become idle at the same time. As soon as three additional workers are available, the cluster assigns workers for the final, five-worker job.
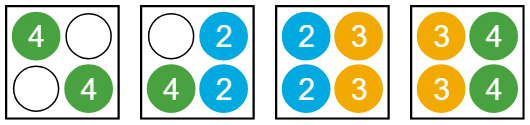
When the second job finishes, there are still active workers across all four machines. The cluster cannot shrink, even though there are seven idle workers.
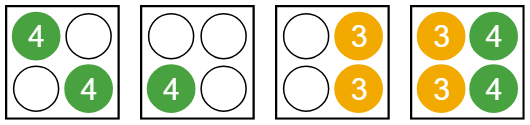
When the third job finishes, all workers on one machine become idle. When they have been idle for over five minutes, that machine is removed. The cluster shrinks to three machines.

When the fourth and final job is finished, all workers on the three remaining machines become idle. If no further jobs are submitted, the cluster is reduced to zero workers. Only the headnode machine remains in the cluster.
AWS Resource Limits
The maximum number of instances that you can start in Cloud Center depends on your AWS® On-Demand Instance limits. On-Demand Instance limits determine the maximum number of virtual central processing units (vCPUs) that you can use. In most cases, a physical core corresponds to 2 vCPUs. For example, a m5.8xlarge instance has 16 physical CPU cores, which corresponds to 32 vCPUs. To determine how many vCPUs you need, use the vCPU limits calculator, which you can find in your AWS EC2 console by selecting Limits>Calculate vCPU limit. For more information on On-Demand Instance limits, see On-Demand Instances.
For machines with GPUs, for optimal performance, use only 1 worker per GPU in the machine.
For more information on how AWS service limits affect the maximum number of instances that you can launch, see Amazon EC2 Service Quotas.
See Also
Topics
- Resolve Scaling Issues in the Cloud (MATLAB Parallel Server)
- Create and Discover Clusters