Deep Learning INT8 Quantization
Increase throughput, reduce resource utilization, and deploy larger networks onto smaller target boards by quantizing your deep learning networks.
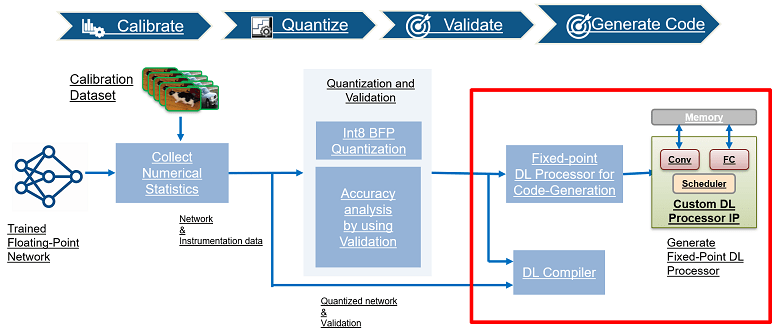
After calibrating your pretrained series network by collecting instrumentation data, quantize your series network and validate the accuracy of your quantized network. Once the quantized network has been validated, generate code for and deploy the quantized network.
Functions
Topics
Get Started
- Supported Networks, Boards, and Tools
Pretrained deep learning networks and network layers for which code can be generated by Deep Learning HDL Toolbox™. - Quantization of Deep Neural Networks
Learn about deep learning quantization tools and workflows.
Quantization Workflow
- Quantization Workflow System Requirements
See what products are required for the quantization of deep neural networks. - Calibration
Simulate your pretrained series network and collect the dynamic range of weights and biases. - Validation
Quantize and validate your pretrained series deep learning network. - Code Generation and Deployment
Generate code and deploy your quantized pretrained series deep learning network.
Featured Examples
Quantize Network for FPGA Deployment
Reduce the memory footprint of a deep neural network by quantizing the weights, biases, and activations of convolution layers to 8-bit scaled integer data types. This example shows how to use Deep Learning Toolbox Model Compression Library and Deep Learning HDL Toolbox to deploy the int8 network to a target FPGA board.

Classify Images on FPGA Using Quantized Neural Network
Use Deep Learning HDL Toolbox™ to deploy a quantized deep convolutional neural network (CNN) to an FPGA. In the example you use the pretrained ResNet-18 CNN to perform transfer learning and quantization. You then deploy the quantized network and use MATLAB® to retrieve the prediction results.

Classify Images on FPGA by Using Quantized GoogLeNet Network
Use the Deep Learning HDL Toolbox™ to deploy a quantized GoogleNet network to classify an image. The example uses the pretrained GoogLeNet network to demonstrate transfer learning, quantization, and deployment for the quantized network. Quantization helps reduce the memory requirement of a deep neural network by quantizing weights, biases and activations of network layers to 8-bit scaled integer data types. Use MATLAB® to retrieve the prediction results.

Semantic Segmentation of Multispectral Images by Using Quantized U-Net on FPGA
Show how to use the Deep Learning HDL Toolbox™ to deploy a quantized U-Net to perform semantic segmentation on multispectral images. The example uses the pretrained U-Net network to demonstrate quantization and deployment of the quantized network. Quantization helps reduce the memory requirement of a deep neural network by quantizing weights, biases, and activations of network layers to 8-bit scaled integer data types. To retrieve the prediction results, use MATLAB®.

Deploy YAMNet Networks to FPGAs with and without Cross-Layer Equalization
Deploy a YAMNet network with and without cross-layer equalization to an FPGA. Cross -layer equalization can improve quantized network performance by reducing the variance of the network learnable parameters in the channels while maintaining the original network mapping. You can compare the accuracies of the network with and without cross-layer equalization.
Deploy Image Recognition Network on FPGA with and Without Pruning
Deploy an image recognition network with and without convolutional filter pruning. Filter pruning is a compression technique that uses some criterion to identify and remove the least important filters in a network, which reduces the overall memory footprint of the network without significantly reducing the network accuracy.