Impute Missing Data in the Credit Scorecard Workflow Using the Random Forest Algorithm
This example shows how to perform imputation of missing data in the credit scorecard workflow using the random forest algorithm.
Random forests are an ensemble learning method for classification or regression that operates by constructing a multitude of decision trees at training time and obtaining the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random forests correct for the tendency of decision trees to overfit to the training set. For more information on the random forest algorithm, see fitrensemble and fitcensemble.
For additional information on alternative approaches for "treating" missing data, see Credit Scorecard Modeling with Missing Values.
Impute Missing Data Using Random Forest Algorithm
Use the dataMissing data set to impute missing values for the CustAge (numeric) and ResStatus (categorical) predictors.
load CreditCardData.mat
disp(head(dataMissing)); CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate status
______ _______ ___________ ___________ _________ __________ _______ _______ _________ ________ ______
1 53 62 <undefined> Unknown 50000 55 Yes 1055.9 0.22 0
2 61 22 Home Owner Employed 52000 25 Yes 1161.6 0.24 0
3 47 30 Tenant Employed 37000 61 No 877.23 0.29 0
4 NaN 75 Home Owner Employed 53000 20 Yes 157.37 0.08 0
5 68 56 Home Owner Employed 53000 14 Yes 561.84 0.11 0
6 65 13 Home Owner Employed 48000 59 Yes 968.18 0.15 0
7 34 32 Home Owner Unknown 32000 26 Yes 717.82 0.02 1
8 50 57 Other Employed 51000 33 No 3041.2 0.13 0
Remove the 'CustID' and 'status' columns in the imputation process as these are the id and response values respectively. Alternatively, you can choose to leave the 'status' column in.
dataToImpute = dataMissing(:,setdiff(dataMissing.Properties.VariableNames,... {'CustID','status'},'stable')); rfImputedData = dataMissing;
Because multiple predictors contain missing data, turn on the 'Surrogate' flag when you create the decision tree template.
rng('default'); tmp = templateTree('Surrogate','on','Reproducible',true);
Next, use the fitrensemble and fitcensemble functions to train regression and classification ensemble models using bagging. The code fits ensembles of 200 decision trees with bootstrap aggregation and random predictor selection at each split, and returns trained model objects that are then used to impute the missing values.
missingCustAge = ismissing(dataToImpute.CustAge); % Fit ensemble of regression learners rfCustAge = fitrensemble(dataToImpute,'CustAge','Method','Bag',... 'NumLearningCycles',200,'Learners',tmp,'CategoricalPredictors',... {'ResStatus','EmpStatus','OtherCC'}); rfImputedData.CustAge(missingCustAge) = predict(rfCustAge,... dataToImpute(missingCustAge,:)); missingResStatus = ismissing(dataToImpute.ResStatus); % Fit ensemble of classification learners rfResStatus = fitcensemble(dataToImpute,'ResStatus','Method','Bag',... 'NumLearningCycles',200,'Learners',tmp,'CategoricalPredictors',... {'EmpStatus','OtherCC'}); rfImputedData.ResStatus(missingResStatus) = predict(rfResStatus,... dataToImpute(missingResStatus,:)); % Optionally, round the age to the nearest integer rfImputedData.CustAge = round(rfImputedData.CustAge);
Compare Imputed Data to Original Data
disp(rfImputedData(5:10,:));
CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate status
______ _______ ___________ __________ _________ __________ _______ _______ _________ ________ ______
5 68 56 Home Owner Employed 53000 14 Yes 561.84 0.11 0
6 65 13 Home Owner Employed 48000 59 Yes 968.18 0.15 0
7 34 32 Home Owner Unknown 32000 26 Yes 717.82 0.02 1
8 50 57 Other Employed 51000 33 No 3041.2 0.13 0
9 50 10 Tenant Unknown 52000 25 Yes 115.56 0.02 1
10 49 30 Home Owner Unknown 53000 23 Yes 718.5 0.17 1
disp(rfImputedData(find(missingCustAge,5),:));
CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate status
______ _______ ___________ __________ _________ __________ _______ _______ _________ ________ ______
4 55 75 Home Owner Employed 53000 20 Yes 157.37 0.08 0
19 54 14 Home Owner Employed 51000 11 Yes 519.46 0.42 1
138 52 31 Other Employed 41000 2 Yes 1101.8 0.32 0
165 46 21 Home Owner Unknown 38000 70 No 1217 0.2 0
207 52 38 Home Owner Employed 48000 12 No 573.9 0.1 0
disp(rfImputedData(find(missingResStatus,5),:));
CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate status
______ _______ ___________ __________ _________ __________ _______ _______ _________ ________ ______
1 53 62 Tenant Unknown 50000 55 Yes 1055.9 0.22 0
22 51 13 Home Owner Employed 35000 33 Yes 468.85 0.01 0
33 46 8 Home Owner Unknown 32000 26 Yes 940.78 0.3 0
47 52 56 Tenant Employed 56000 79 Yes 294.46 0.12 0
103 64 49 Home Owner Employed 50000 35 Yes 118.43 0 0
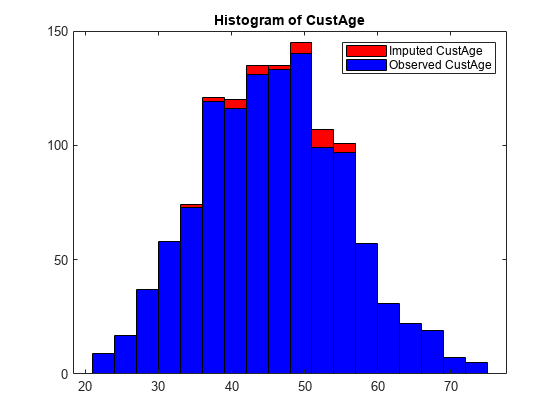
Plot a histogram of the predictor values before and after imputation.
Predictor ="CustAge"; f1 = figure; ax1 = axes(f1); histogram(ax1,rfImputedData.(Predictor),'FaceColor','red','FaceAlpha',1); hold on histogram(ax1,dataMissing.(Predictor),'FaceColor','blue','FaceAlpha',1); legend(strcat("Imputed ", Predictor), strcat("Observed ", Predictor)); title(strcat("Histogram of ", Predictor));
Create Credit Scorecard Model Using New Imputed Data
Use the imputed data to create the creditscorecard object, and then use autobinning, fitmodel, and formatpoints to create a credit scorecard model.
sc = creditscorecard(rfImputedData,'IDVar','CustID'); sc = autobinning(sc); [sc,mdl] = fitmodel(sc,'display','off'); sc = formatpoints(sc,'PointsOddsAndPDO',[500 2 50]); PointsInfo = displaypoints(sc); disp(PointsInfo);
Predictors Bin Points
______________ _____________________ ______
{'CustAge' } {'[-Inf,33)' } 54.313
{'CustAge' } {'[33,37)' } 57.145
{'CustAge' } {'[37,40)' } 59.04
{'CustAge' } {'[40,46)' } 68.806
{'CustAge' } {'[46,51)' } 78.204
{'CustAge' } {'[51,58)' } 81.041
{'CustAge' } {'[58,Inf]' } 96.395
{'CustAge' } {'<missing>' } NaN
{'ResStatus' } {'Tenant' } 62.768
{'ResStatus' } {'Home Owner' } 72.621
{'ResStatus' } {'Other' } 92.228
{'ResStatus' } {'<missing>' } NaN
{'EmpStatus' } {'Unknown' } 58.839
{'EmpStatus' } {'Employed' } 86.897
{'EmpStatus' } {'<missing>' } NaN
{'CustIncome'} {'[-Inf,29000)' } 29.765
{'CustIncome'} {'[29000,33000)' } 56.167
{'CustIncome'} {'[33000,35000)' } 67.926
{'CustIncome'} {'[35000,40000)' } 70.119
{'CustIncome'} {'[40000,42000)' } 70.93
{'CustIncome'} {'[42000,47000)' } 82.337
{'CustIncome'} {'[47000,Inf]' } 96.733
{'CustIncome'} {'<missing>' } NaN
{'TmWBank' } {'[-Inf,12)' } 51.023
{'TmWBank' } {'[12,23)' } 61.005
{'TmWBank' } {'[23,45)' } 61.806
{'TmWBank' } {'[45,71)' } 92.95
{'TmWBank' } {'[71,Inf]' } 133.22
{'TmWBank' } {'<missing>' } NaN
{'OtherCC' } {'No' } 50.796
{'OtherCC' } {'Yes' } 75.644
{'OtherCC' } {'<missing>' } NaN
{'AMBalance' } {'[-Inf,558.88)' } 89.941
{'AMBalance' } {'[558.88,1254.28)' } 63.018
{'AMBalance' } {'[1254.28,1597.44)'} 59.613
{'AMBalance' } {'[1597.44,Inf]' } 48.972
{'AMBalance' } {'<missing>' } NaN
Calculate Scores and Probability of Default for New Customers
Create a data set of 'new customers' and then calculate the scores and probabilities of default.
dataNewCustomers = dataMissing(1:20,1:end-1); disp(head(dataNewCustomers));
CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate
______ _______ ___________ ___________ _________ __________ _______ _______ _________ ________
1 53 62 <undefined> Unknown 50000 55 Yes 1055.9 0.22
2 61 22 Home Owner Employed 52000 25 Yes 1161.6 0.24
3 47 30 Tenant Employed 37000 61 No 877.23 0.29
4 NaN 75 Home Owner Employed 53000 20 Yes 157.37 0.08
5 68 56 Home Owner Employed 53000 14 Yes 561.84 0.11
6 65 13 Home Owner Employed 48000 59 Yes 968.18 0.15
7 34 32 Home Owner Unknown 32000 26 Yes 717.82 0.02
8 50 57 Other Employed 51000 33 No 3041.2 0.13
Predict missing data in the scoring data set with the same imputation model as before.
missingCustAgeNewCustomers = isnan(dataNewCustomers.CustAge); missingResStatusNewCustomers = ismissing(dataNewCustomers.ResStatus); imputedCustAgeNewCustomers = round(predict(rfCustAge, dataNewCustomers(missingCustAgeNewCustomers,:))); imputedResStatusNewCustomers = predict(rfResStatus, dataNewCustomers(missingResStatusNewCustomers,:)); dataNewCustomers.CustAge(missingCustAgeNewCustomers) = imputedCustAgeNewCustomers; dataNewCustomers.ResStatus(missingResStatusNewCustomers) = imputedResStatusNewCustomers;
Use score to calculate the scores of the new customers.
[scores, points] = score(sc, dataNewCustomers); disp(scores);
530.9936 553.1144 504.7522 563.8821 552.3131 584.2581 445.2402 515.6361 523.9354 506.8645 497.9661 538.1986 516.3480 493.3467 566.2568 487.2501 477.0996 470.1861 553.9004 510.7086
disp(points);
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ _________ _________ __________ _______ _______ _________
81.041 62.768 58.839 96.733 92.95 75.644 63.018
96.395 72.621 86.897 96.733 61.806 75.644 63.018
78.204 62.768 86.897 70.119 92.95 50.796 63.018
81.041 72.621 86.897 96.733 61.005 75.644 89.941
96.395 72.621 86.897 96.733 61.005 75.644 63.018
96.395 72.621 86.897 96.733 92.95 75.644 63.018
57.145 72.621 58.839 56.167 61.806 75.644 63.018
78.204 92.228 86.897 96.733 61.806 50.796 48.972
78.204 62.768 58.839 96.733 61.806 75.644 89.941
78.204 72.621 58.839 96.733 61.806 75.644 63.018
81.041 62.768 58.839 67.926 61.806 75.644 89.941
78.204 92.228 58.839 82.337 61.005 75.644 89.941
96.395 72.621 58.839 96.733 51.023 50.796 89.941
68.806 92.228 58.839 70.93 61.806 50.796 89.941
78.204 92.228 86.897 82.337 61.005 75.644 89.941
57.145 72.621 86.897 70.119 61.806 75.644 63.018
59.04 62.768 86.897 67.926 61.806 75.644 63.018
54.313 72.621 86.897 29.765 61.005 75.644 89.941
81.041 72.621 86.897 96.733 51.023 75.644 89.941
81.041 92.228 58.839 82.337 61.005 75.644 59.613