FCM Data Clustering
Description
The FCM Data Clustering task clusters data using the fuzzy c-means (FCM) algorithm, where each data point belongs to a cluster to a degree that is specified by a membership grade. For example, a data point that lies close to the center of a cluster will have a high degree of membership in that cluster, and another data point that lies far away from the center of a cluster will have a low degree of membership to that cluster. The FCM Data Clustering task automatically generates MATLAB® code for your live script. For more information about Live Editor tasks, see Add Interactive Tasks to a Live Script.
The task returns these output arguments from the fcm
function:
centers— Cluster centersU— Fuzzy partition matrix indicating the degree of membership of each data point in each clusterobjFcn— Objective function values for each clustering iterationinfo— Detailed clustering results
For more information on the FCM algorithm, see Fuzzy C-Means Clustering.

Open the Task
To add the FCM Data Clustering task to a live script in the MATLAB Editor:
On the Live Editor tab, select Task > FCM Data Clustering.
In a code block in the script, enter a relevant keyword, such as
fcmorclustering. Select FCM Data Clustering from the suggested command completions.
Examples
Use the FCM Data Clustering task in the Live Editor to interactively cluster data using the fuzzy c-means (FCM) algorithm. You can experiment with different clustering configurations, such as the number of clusters or distance metric.
Load the five sample data sets. These data sets have different numbers of clusters and data distributions.
load fcmdataEach data set contains two columns that represent the two features for each data point.
To cluster the data, open the FCM Data Clustering task in the Live Editor. On the Live Editor tab, select Task > FCM Data Clustering.
Select the data to cluster. For this example, under Input data, select fcmdata3.
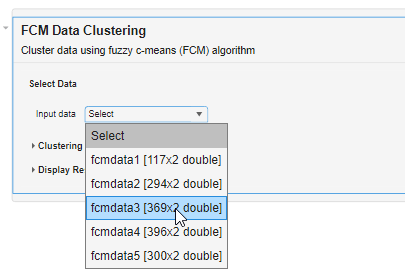
Under Clustering Options, configure the clustering algorithm. For this example, set the Number of clusters to [2 3 4 5]. The task computes clusters for each cluster count in Number of clusters and returns the clustering results for the optimal number of clusters.
Keep the remaining options at their default values.

To cluster the data, click the Run current section button ![]() . The task clusters the data and plots the results. The task also returns the cluster centers, partition matrix, and objective function values as
. The task clusters the data and plots the results. The task also returns the cluster centers, partition matrix, and objective function values as centers, U, and objFcn, respectively.
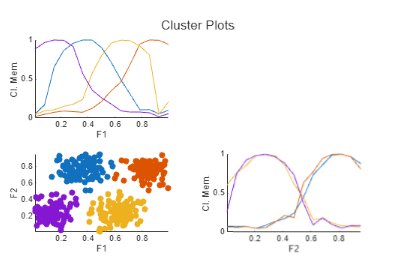
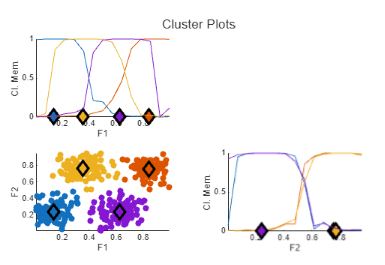
The nondiagonal plot shows each data point classified into the cluster for which it has the highest membership value. The diagonal axes show the marginal cluster membership sets for each feature.
The clustering terminates after around 12 iterations. The output argument objFcn returns the objective function value for each iteration. The final minimum objective function value is around 4.6.
To improve the clustering results and reduce the final objective function value, cluster the data using Mahalanobis distance rather than the default Euclidean distance. The Mahalanobis distance metric generally performs better for nonspherical clusters.
Under Distance metric, select Mahalanobis.
To avoid overwriting the previous clustering results, in the top section of the task, modify the output argument names to centers2, U2, objFcn2, and info2.
Also, since the previous clustering operation found that four clusters was optimal, set Number of clusters to 4.
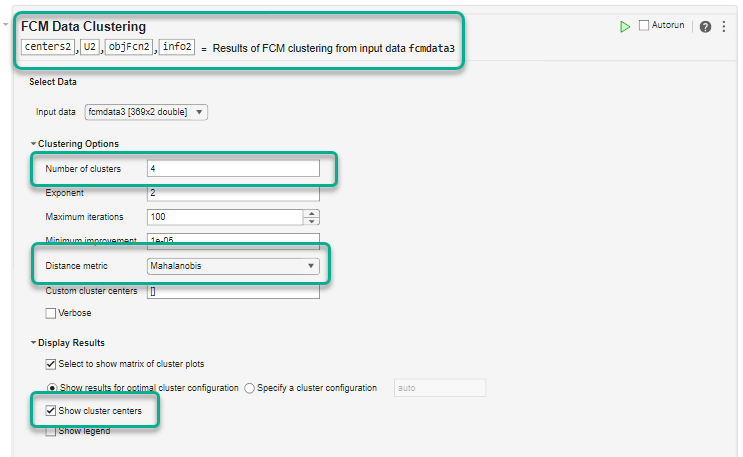
Run the task to cluster the data. The resulting marginal cluster membership values have sharper transitions. Also, the minimum objective function value in objFcn2 is around 0.17, which is significantly lower than the first clustering operation.
To customize the appearance of the cluster plot, specify display options under Display Results. For example:
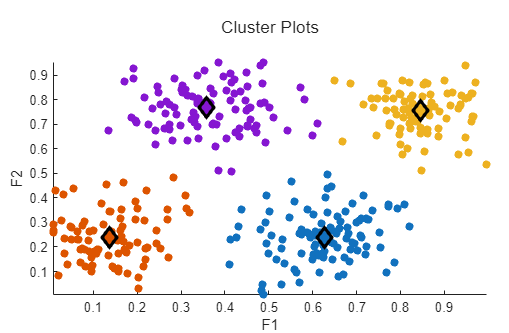
To display the cluster centers, select the Show cluster centers parameter.
To suppress the marginal cluster membership plots, clear the Show membership plots parameter.
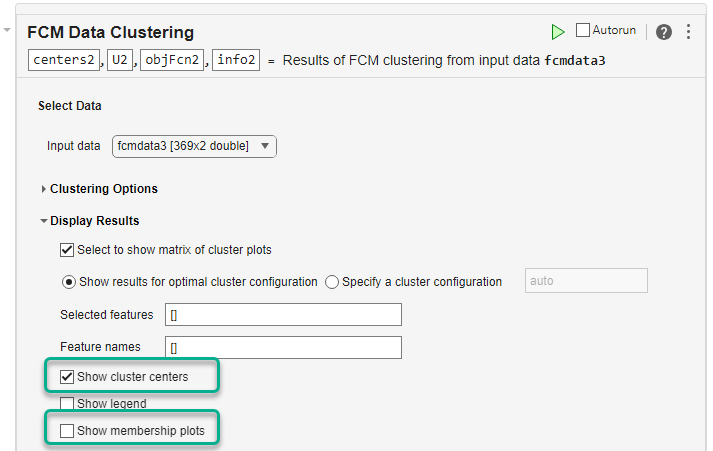
Run the task to cluster the data and display the updated plot. The cluster plot expands to cover the entire plotting area and the cluster centers are displayed as diamonds.