Optimize Kernels That Contain Loops
This example shows how to generate more efficient code by refactoring a MATLAB® function to combine multiple for-loops inside generated code kernels. If a kernel contains a loop, it must execute the loop sequentially instead of computing the result in parallel across several threads. Parallelizing a loop inside a kernel can cause the kernel to launch with more threads and utilize the GPU more efficiently.
Examine and Profile the loopInKernel Function
The function loopInKernel takes two matrices, multiplies each element by two, and returns the two matrices. The input matrices must have an equal number of columns, but can have a different number of rows.
type loopInKernel.mfunction [out1, out2] = loopInKernel(in1, in2)
% Multiply the input matrices by two.
% in1 and in2 must have an equal number of columns.
coder.gpu.kernelfun;
out1 = coder.nullcopy(in1);
out2 = coder.nullcopy(in2);
for i = 1:size(in1,2)
for j1 = 1:size(in1,1) % loop over rows of in1
out1(j1,i) = in1(j1,i)*2;
end
for j2 = 1:size(in2, 1) % loop over rows of in2
out2(j2,i) = in2(j2,i)*2;
end
end
end
Create a coder.MexCodeConfig object, cfg, and two input arrays: in1, a 300-by-400 array, and in2, a 500-by-400 array. Use the gpuPerformanceAnalyzer function to profile the generated code.
cfg = coder.gpuConfig("mex"); in1 = gpuArray(rand(300,400)); in2 = gpuArray(rand(500,400)); gpuPerformanceAnalyzer("loopInKernel.m",{in1,in2},Config=cfg);
### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data
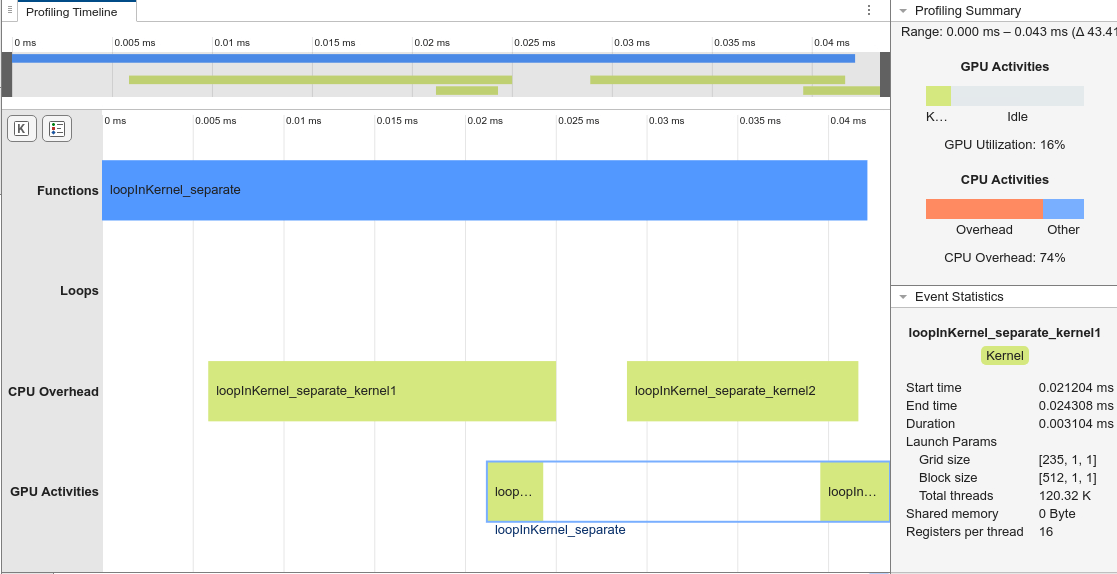
The analysis shows that a single kernel, loopInKernel_kernel1, takes most of the execution time. The Event Statistics pane shows this kernel launches with only 512 total threads.

In the generated code, the kernel contains these two for-loops. These loops correspond to the loops inside the MATLAB function loopInKernel. The first loop iterates 300 times to calculate out1, and the second loop iterates 500 times to calculate out2. The loops contribute to the longer runtime of the kernel.
for (int32_T j2{0}; j2 < 300; j2++) {
out2_tmp = j2 + 300 * i;
out1[out2_tmp] = in1[out2_tmp] * 2.0;
}
for (int32_T j2{0}; j2 < 500; j2++) {
out2_tmp = j2 + 500 * i;
out2[out2_tmp] = in2[out2_tmp] * 2.0;
}
Parallelize the Loop Inside the Kernel
One reason the generated code might contain a loop inside a kernel is because of the loop structure. GPU Coder™ tries to optimize nested loops into a single, larger loop that it can implement as a kernel. To optimize for GPU code generation, structure nested loops without code in between the two loops. This pseudocode demonstrates the structure with a nested for-loop.
for ()
for()
...
end
end
With this structure, there is no code between the outer loop and inner loops, so GPU Coder may flatten the two nested for-loops into a single, larger loop. However, in the function loopInKernel, there are two loops inside the outer for-loop. Because these two inner loops iterate 300 and 500 times, respectively, they cannot be combined into one loop and parallelized.
To optimize the code, you can either split the nested loop into multiple nested loops or combine the loops using conditional statements.
Split the Nested Loop into Multiple Nested Loops
In the loopInKernel function, the first for-loop contains two other for-loops that compute the output variables out1 and out2, respectively. Create a new function, loopInKernel_separate, that splits the for-loop into two different loops that calculate the outputs separately.
type loopInKernel_separate.mfunction [out1, out2] = loopInKernel_separate(in1, in2)
coder.gpu.kernelfun;
out1 = coder.nullcopy(in1);
out2 = coder.nullcopy(in2);
for i = 1:size(in1, 2)
for j = 1:size(in1, 1)
out1(j, i) = in1(j, i) * 2;
end
end
for i = 1:size(in2, 2)
for j = 1:size(in2, 1)
out2(j, i) = in2(j, i) * 2;
end
end
end
Run the gpuPerformanceAnalyzer function to profile the new function.
gpuPerformanceAnalyzer("loopInKernel_separate.m",{in1,in2},Config=cfg);### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data
GPU Coder generates two kernels, one for each output. Separating the code into two nested loops allows GPU Coder to generate faster, more efficient kernels that have fewer responsibilities.
Combine Multiple Loops with Conditional Statements
Alternatively, you can optimize the code by combining the loops that compute out1 and out2 using conditional logic. Create a new function, loopInKernel_fuse. Use if statements to ensure the generated code assigns values to valid indices of out1 and out2.
type loopInKernel_fuse.mfunction [out1, out2] = loopInKernel_fuse(in1, in2)
coder.gpu.kernelfun;
out1 = coder.nullcopy(in1);
out2 = coder.nullcopy(in2);
dim1 = max(size(in1, 1), size(in2, 1));
for i = 1:size(in1, 2)
for j = 1:dim1
if (j <= size(in1, 1))
out1(j, i) = in1(j, i) * 2;
end
if (j <= size(in2, 1))
out2(j, i) = in2(j, i) * 2;
end
end
end
end
Run the gpuPerformanceAnalyzer function to profile the new function.
gpuPerformanceAnalyzer("loopInKernel_fuse",{in1,in2},Config=cfg)### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data
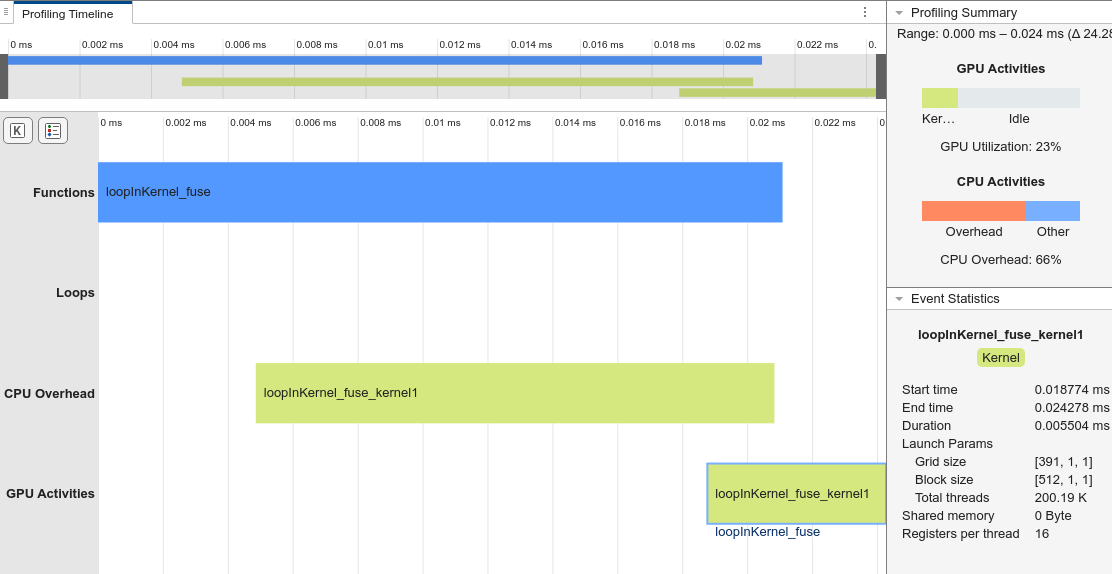
After the refactoring, there is no intermediate code in the loop structure. In the generated kernel, there are no internal loops.
On a machine with an Intel® Xeon® CPU ES-1650 at 3.60Hz x 12 CPU and an NVIDIA® Quadro RTX 6000 GPU, the generated code for loopInKernel_fuse is 10 times faster than the generated code for loopInKernel. After selecting the generated kernel in the Performance Analyzer app, the Event Statistics panel shows the refactored kernel saturates the GPU by launching more than 200,190 threads. The generated kernel for the original function, loopInKernel, only launches 512 threads.