Minimize Memory Copy Events in Generated Code Loops
This example shows how to minimize the number of memory copy events in loops in generated CUDA® code. Copying memory during each iteration of a loop can slow the performance of generated code because each data transfer between the CPU and GPU requires a significant amount of overhead. For loops with many iterations, this overhead can take a significant share of the application runtime.
Examine and Profile the addThreeMatrices Function
The addThreeMatrices function takes three input matrices of the same size, in1, in2, and in3. It loops over the rows of the input matrices to compute an output matrix, out, and computes a sum, a, using out and in3.
type addThreeMatrices.m;function [out, a] = addThreeMatrices(in1, in2, in3)
coder.gpu.kernelfun
out = coder.nullcopy(in1);
a = 0;
for i = 1:size(in1, 1)
for j = 1:size(in1, 2)
out(i, j) = in1(i, j) + in2(i, j);
end
a = a + out(i, 1) + in3(i, 1);
end
end
To generate code that inputs in1 and in2 to the GPU, create two 200-by-200 gpuArray objects named in1 and in2. To pass in3 to the CPU, create a 200-by-200 array named in3. GPU Coder™ passes arrays that are not gpuArray objects to the CPU by default.
in1 = gpuArray(rand(200,200)); in2 = gpuArray(rand(200,200)); in3 = rand(200,200);
Use the gpuPerformanceAnalyzer function to profile the generated code for the addThreeMatrices function.
cfg = coder.gpuConfig("mex"); gpuPerformanceAnalyzer("addThreeMatrices",{in1,in2,in3},Config=cfg);
### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data
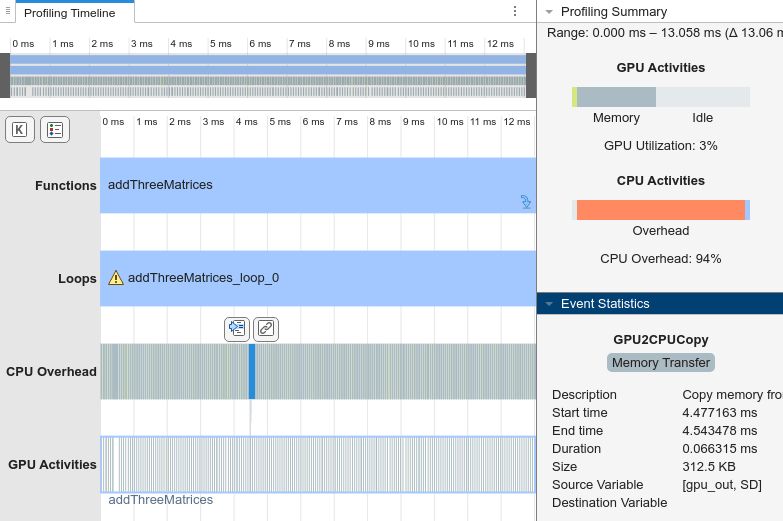
The Profiling Timeline tab shows many gray memory copy events in the CPU Overhead row because the loop is copying memory from the GPU to the CPU every iteration.
Click one of the memory copy events in the Profiling Timeline tab. The Event Statistics pane shows the generated code copies the variable gpu_out to the CPU. Because the input variables in1 and in2 are on the GPU, the loop calculates the output variable, out, on the GPU as gpu_out. The third input, in3, is on the CPU, so each iteration of the loop must copy gpu_out to the CPU or copy in3 to the GPU to calculate a. In this case, the generated code copies gpu_out to the CPU.
Separate CPU and GPU Calculations into Different Loops
To avoid copying memory inside the loop, separate the calculations of out and a into different loops. GPU Coder must generate memory copy operations for any CPU calculations that depend on GPU data and any GPU calculations that depend on CPU data. By separating GPU and CPU calculations into separate loops, you can minimize the number of memory copies in generated code. Create a new function, addThreeMatricesSeparate, that uses two loops to calculate out and a.
type addThreeMatricesSeparate.mfunction [out, a] = addThreeMatricesSeparate(in1, in2, in3)
coder.gpu.kernelfun
out = coder.nullcopy(in1);
a = 0;
for i = 1:size(in1, 1)
for j = 1:size(in1, 2)
out(i, j) = in1(i, j) + in2(i, j);
end
end
for i=1:size(in1,1)
a = a + out(i, 1) + in3(i, 1);
end
end
Profile the addThreeMatricesSeparate function with the GPU Performance Analyzer.
gpuPerformanceAnalyzer("addThreeMatricesSeparate",{in1,in2,in3},Config=cfg);### Starting GPU code generation Code generation successful: View report ### GPU code generation finished ### Starting application profiling ### Application profiling finished ### Starting profiling data processing ### Profiling data processing finished ### Showing profiling data
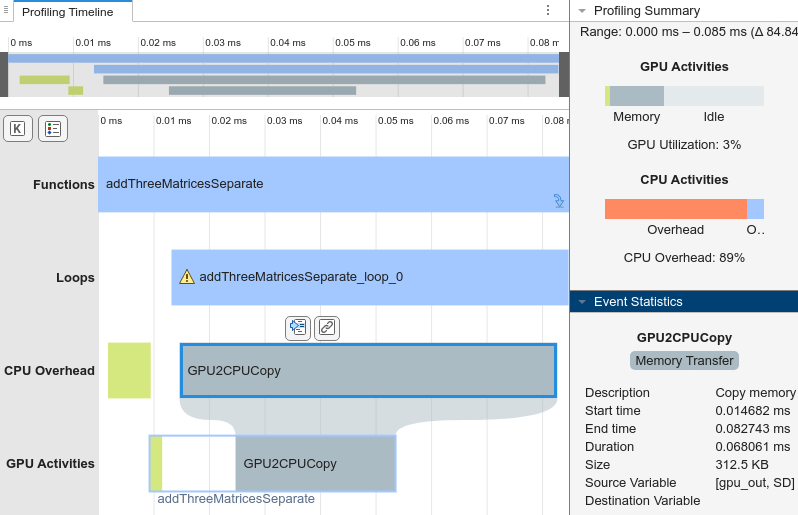
In the Profiling Timeline tab, in the CPU Overhead row, there is only one memory copy event from the GPU to the CPU. Because the loops in the MATLAB function calculate out and a separately, the generated code calculates out and then copies it once to the CPU so the CPU can calculate a. On a machine with an Intel® Xeon® ES-1650 CPU at 3.60Hz x 12 and an NVIDIA® Quadro RTX 6000 GPU, the generated code is more than 100 times faster than the generated code for the original function.