How Pipeline Generation Works
With the CI Support Package for Simulink, you can define a process for your team and set up your CI system to run the tasks in that process as a pipeline in CI. A pipeline is a collection of automated procedures and tools that execute in a specific order to enable a streamlined software delivery process. CI systems allow you to define and configure a pipeline by using a pipeline file.
Typically, when you configure a CI pipeline, you must manually create and update pipeline
configuration files as you add, remove, and change the artifacts in your project.
However, the example pipeline configuration files use a pipeline generator function,
padv.pipeline.generatePipeline, that can generate the updated
pipeline configuration files for you. After you do the initial setup for the pipeline
generator, you do not need to manually update your pipeline configuration files. When
you trigger your pipeline, the pipeline generator uses the digital thread to analyze the
files in your project and uses your process model to generate pipeline configuration
files for you.
Summary of Support
When you use the support package to integrate a model-based design (MBD) project into CI, there are three main approaches to creating and maintaining your pipeline configuration files:
Manual Authoring — Each time you need to create or update your pipeline, you manually write, update, and check in a pipeline configuration file that uses the
runprocessfunction to run tasks. This approach offers you the most flexibility and customization, but requires you to regularly maintain the pipeline configuration file. For example, as part of your pipeline configuration file you might call:matlab -batch "openProject(pwd);runprocess();"Manual Generation — Each time you commit changes, you manually generate a pipeline configuration file using the
padv.pipeline.generatePipelinefunction in your local MATLAB® installation, and then manually check the pipeline configuration file into your CI system. With this approach, you do not need to manually write the pipeline configuration file, but you do need to manually regenerate the pipeline for each submission. For example, in MATLAB, you might generate a pipeline configuration file for GitHub® by running:op = padv.pipeline.GitHubOptions; padv.pipeline.generatePipeline(op)
Automatic Generation — You perform a one-time setup of a parent pipeline configuration file that automatically calls the
padv.pipeline.generatePipelinefunction and generates an up-to-date, child pipeline configuration file that runs your process in CI. With this approach, you do not have to manually write or generate pipeline configuration files, but setting up a branching workflow can be complex. For example, you might use one of the template pipeline configuration files that the support package provides or as part of your pipeline configuration file you might call:matlab -batch "openProject(pwd);padv.pipeline.generatePipeline(padv.pipeline.GitLabOptions(GeneratorVersion=2,Tags='high_memory'));"
The following table lists which approaches the support package supports on each CI platform.
Approaches \ Platforms | Azure® DevOps | GitHub | GitLab® | Jenkins® | Other MATLAB-Supported CI Platforms |
|---|---|---|---|---|---|
Manual Authoring | ✔ | ✔ | ✔ | ✔ | ✔ |
Manual Generation | ✔ (recommended) | ✔ (recommended) | ✔ | ✔ | |
Automatic Generation | ✔ (recommended) | ✔ (recommended) |
For CI platforms, you typically define your CI pipeline by using a pipeline configuration file. For example, a YAML file on platforms like GitHub and GitLab or a Jenkinsfile on Jenkins.
Typically, when you configure a CI pipeline, you must manually create and update your pipeline
configuration files as you add, remove, and change the artifacts in your project.
However, the support package has a pipeline generator function padv.pipeline.generatePipeline that you can use to generate the
pipeline configuration files for GitHub, GitLab, and Jenkins.
For example, on a CI platform like GitLab, the pipeline generator can automatically generate the pipeline configuration files that you would must create a pipeline that runs each job in your process, generate a report, and collect the artifacts from the pipeline.
Generated Pipelines
After you perform the initial setup and trigger your pipeline, typically the pipeline generator generates a parent pipeline and a child pipeline.
Typically, the parent pipeline contains two stages:
Pipeline generation — This stage analyzes your project and process model to automatically generate the pipeline configuration files to run your process in CI. If you want to view the generated pipeline configuration files, the pipeline generator stores the files under the
derived > pipelinefolder in the project.Pipeline execution — This stage creates and executes a child pipeline that runs the tasks in your process, generates a build report, and collects the job artifacts. You define the number of stages and groupings of tasks in the child pipeline by using the
PipelineArchitctureproperty of the pipeline generator options object.

Incremental Builds and Artifact Management
To support incremental builds in CI, the build system needs access to the:
task outputs
digital thread file (
derived/artifacts.dmr)
The build system uses these files to determine whether tasks are up-to-date and can be skipped, or outdated and need to be rerun. The pipeline generator automatically manages these files for you. The way the pipeline generator manages these files depends on which pipeline generator version you are using:
Pipeline generator version 1 uses the built-in caching features of the different CI platforms.
Pipeline generator version 2 archives and caches task outputs and the digital thread in external storage. Then, for each job, the pipeline generator downloads only the necessary files for new jobs to avoid rerunning tasks that are already up-to-date.
Pipeline generator version 2 attempts to restore the cache from the last successful run on the same branch. If no cache is available, the pipeline checks for cached build artifacts on the branches that you specify in the
CacheFallbackBranchesproperty of the pipeline generator options object. By default, the fallback branch is set tomain, but you can specify multiple fallback branches and the pipeline checks each one in order. If the pipeline generator does not find a cache on the specified branches, the pipeline runs a full build, executing each task in the process without skipping tasks.
The pipeline generator supports Azure DevOps, GitHub, GitLab, and Jenkins integrations.
To enable incremental builds on other CI platforms, make sure your jobs have
access to both the task outputs and the digital thread file
(derived/artifacts.dmr). Archive these files and make them
available to future jobs so the build system can identify which tasks are
up-to-date.
Optional Pipeline Customization
You can run the pipeline generator using the default options or you can edit the example pipeline configuration file to customize how the pipeline generator creates and executes pipelines in CI.
The call to the pipeline generator function (padv.pipeline.generatePipeline) is in the example pipeline configuration file. The function padv.pipeline.generatePipeline requires you to specify a CI options object as an input.
The CI options object allows you to specify several properties of the generated CI pipeline, including:
the pipeline architecture
whether the pipeline generates a build report
if and when the pipeline collects artifacts from the build
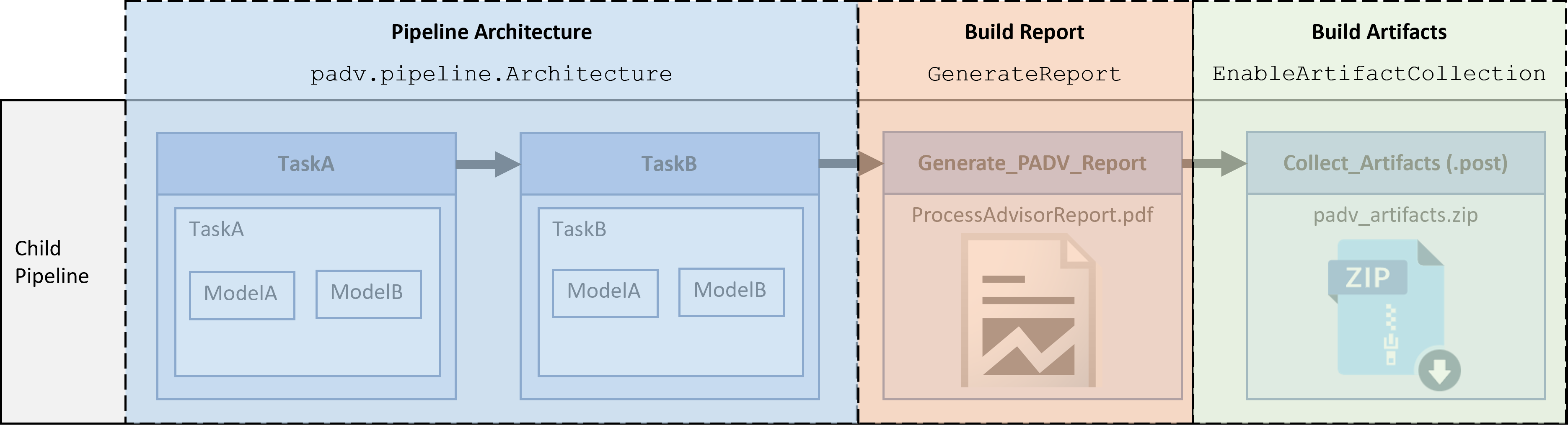
Pipeline Architecture
The pipeline architecture defines the number of stages and the grouping of tasks in the child pipeline. You can specify the pipeline architecture by using a padv.pipeline.Architecture object.
By default, the example pipeline configuration files specify the pipeline architecture as SerialStagesGroupPerTask, which creates one stage for each task in the process model. For example, one stage for TaskA and one stage for TaskB.
The available pipeline architectures are:
SingleStage— A single stage, Runprocess, that runs all the tasks in the process.SerialStages— One stage for each task iteration in the process.SerialStagesGroupPerTask— One stage for each task in the process.IndependentModelPipelines— Parallel, downstream pipelines for each model. Each pipeline independently runs the tasks associated with the model.
Build Report
By default, the pipeline generator creates a stage, Generate_PADV_Report, that generates a build report for your pipeline. The build report is a PDF file ProcessAdvisorReport.pdf.
If you do not want to generate a report, you can specify the GenerateReport argument as false. For example, in a GitLab pipeline configuration file:
padv.pipeline.GitLabOptions(GenerateReport = false)
Build Artifacts
By default, the pipeline generator creates a stage, Collect_Artifacts, that collects and compresses the build artifacts from your pipeline. The ZIP file attached to the Collect_Artifacts stage is called padv_artifacts.zip. You can download these artifacts to locally reproduce issues seen in CI. For more information, see Locally Reproduce Issues Found in CI.
You can specify if and when you want the pipeline to collect artifacts by specifying the argument EnableArtifactCollection:
"never",0, orfalse— Never collect artifacts"on_success"— Only collect artifacts when the pipeline succeeds"on_failure"— Only collect artifacts when the pipeline fails"always",1, ortrue— Always collect artifacts
For example, in a GitLab pipeline configuration file:
padv.pipeline.GitLabOptions(EnableArtifactCollection="on_failure")
Considerations for Parallel Code Generation
If you want to use a parallel pipeline architecture, like
"IndependentModelPipelines", and your process involves code
generation and code analysis tasks, you must either use the template parallel
process model or update your existing process model. These updates allow the tasks
in your pipeline to properly handle shared utilities and code generated across
parallel jobs.
Template Parallel Process Model
To see the template parallel process model, you can either:
Open the Process Advisor example project for parallel pipelines:
processAdvisorParallelExampleStart
Create a parallel process model using the parallel template:
createprocess(Template = "parallel")
Update Existing Process Model
To update your existing process model for a round-trip parallel CI workflow, you must:
Have a task that generates code for your reference models. The task must specify the property
GenerateExternalCodeCacheastrueand specify anExternalCodeCacheDirectory. The external code cache allows your team to generate code in parallel while maintaining up-to-date task status information. For example:% Generate Code for Reference Models codegenTask = pm.addTask(padv.builtin.task.GenerateCode("IterationQuery", ... padv.builtin.query.FindRefModels)); codegenTask.TreatAsRefModel = true; codegenTask.Title = "Reference Model Code Generation"; codegenTask.GenerateExternalCodeCache = true; codegenTask.ExternalCodeCacheDirectory = fullfile( ... '$DEFAULTOUTPUTDIR$', '$ITERATIONARTIFACT$', 'external_code_cache');
Have a task that generates code for your top models. The task must iterate over the project file, specify the property
GenerateExternalCodeCacheastrue, and specify anExternalCodeCacheDirectory. The external code cache allows your team to generate code in parallel while maintaining up-to-date task status information. For example:% Generate Code for Top Models (at the project-level) codegenTopTask = pm.addTask(padv.builtin.task.GenerateCode("IterationQuery", ... padv.builtin.query.FindProjectFile,"InputQueries",... {padv.builtin.query.FindTopModels,... padv.builtin.query.GetOutputsOfDependentTask(... "padv.builtin.task.GenerateCode")},... "Name", "Top Model Code Generation")); codegenTopTask.TreatAsRefModel = false; codegenTopTask.Title = "Top Model Code Generation"; codegenTopTask.TrackAllGeneratedCode = true;
Split code analysis tasks into two tasks. One task for reference models and one task for top models. The task for top models must iterate over the project file. The built-in code analysis tasks, like
padv.builtin.task.RunCodeInspection, are able to unpack the code generation target from the external code cache by using the utility functionpadv.util.unpackExternalCodeCache.% Inspect Generated Code for Reference Models slciTask = pm.addTask(padv.builtin.task.RunCodeInspection("IterationQuery", ... padv.builtin.query.FindRefModels)); slciTask.ReportFolder = fullfile(defaultResultPath,'code_inspection'); slciTask.Title = "Ref Model Code Inspection"; % Inspect Generated Code for Top Models (at the project-level) slciTopTask = pm.addTask(padv.builtin.task.RunCodeInspection("IterationQuery", ... padv.builtin.query.FindProjectFile,"InputQueries",... {padv.builtin.query.GetOutputsOfDependentTask("Top Model Code Generation"),... padv.builtin.query.FindTopModels},"Name","Top Model Code Inspection")); slciTopTask.Title = "Top Model Code Inspection"; slciTopTask.ReportFolder = fullfile('$DEFAULTOUTPUTDIR$','code_inspection',... '$INPUTARTIFACT$'); slciTopTask.OutputDirectory = string(fullfile('$DEFAULTOUTPUTDIR$','code_inspection'));
Update the
dependsOnandrunsAfterrelationships in your process model to specify the relationships for these tasks.
Note
There are limitations to the task relationships that the pipeline generator can support. The pipeline generator requires your process model to only generate one parallel section. If tasks, like model tasks, run in parallel, you must define your task relationships so that subsequent tasks iterate over the project file. The pipeline generator only supports a single shift from parallel to serial execution per CI build because the pipeline generator only merges the artifact database files once.

The pipeline generator does not support, for example, a process model that alternates between tasks that execute in parallel, then in serial, then parallel again.
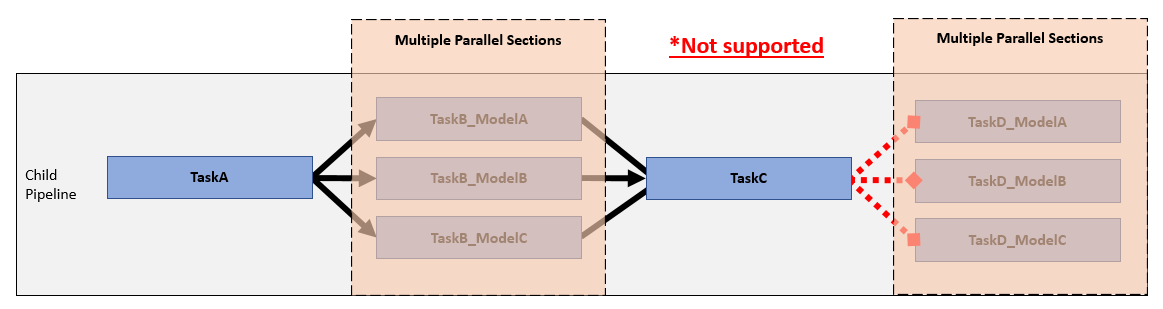
The example parallel process model uses top model code generation and code analysis tasks that iterate over the project file to avoid creating multiple parallel sections.
See Also
padv.pipeline.generatePipeline | padv.pipeline.AzureDevOpsOptions | padv.pipeline.GitHubOptions | padv.pipeline.GitLabOptions | padv.pipeline.JenkinsOptions