cvloss
Classification error by cross-validation for classification tree model
Description
E = cvloss(tree)E for the trained
classification tree model tree. The cvloss function uses
stratified partitioning to create cross-validated sets. That is, for each fold, each
partition of the data has roughly the same class proportions as in the data used to train
tree.
E = cvloss(tree,Name=Value)
Examples
Compute the cross-validation error for a default classification tree.
Load the ionosphere data set.
load ionosphereGrow a classification tree using the entire data set.
Mdl = fitctree(X,Y);
Compute the cross-validation error.
rng(1); % For reproducibility
E = cvloss(Mdl)E = 0.1140
E is the 10-fold misclassification error.
Apply k-fold cross validation to find the best level to prune a classification tree for all of its subtrees.
Load the ionosphere data set.
load ionosphereGrow a classification tree using the entire data set. View the resulting tree.
Mdl = fitctree(X,Y); view(Mdl,'Mode','graph')
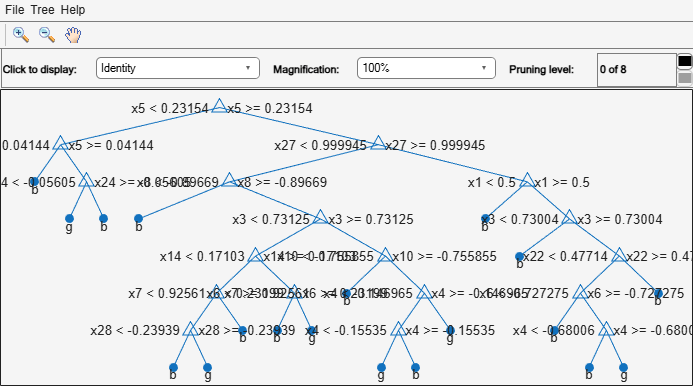
Compute the 5-fold cross-validation error for each subtree except for the highest pruning level. Specify to return the best pruning level over all subtrees.
rng(1); % For reproducibility
m = max(Mdl.PruneList) - 1m = 7
[E,~,~,bestLevel] = cvloss(Mdl,'Subtrees',0:m,'KFold',5)
E = 8×1
0.1282
0.1254
0.1225
0.1282
0.1282
0.1197
0.0997
0.1738
bestLevel = 6
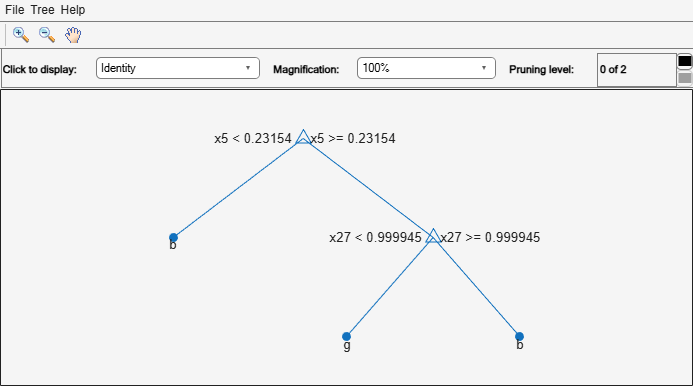
Of the 7 pruning levels, the best pruning level is 6.
Prune the tree to the best level. View the resulting tree.
MdlPrune = prune(Mdl,'Level',bestLevel); view(MdlPrune,'Mode','graph')
Input Arguments
Name-Value Arguments
Output Arguments
Alternatives
You can construct a cross-validated tree model with crossval, and call
kfoldLoss instead of cvloss. If you are going to
examine the cross-validated tree more than once, then the alternative can save time.
However, unlike cvloss, kfoldLoss does not return SE, Nleaf, or
BestLevel. kfoldLoss also does not
allow you to examine any error other than the classification error.
Extended Capabilities
Version History
Introduced in R2011a
See Also
fitctree | crossval | loss | kfoldLoss | ClassificationTree