Two-Way ANOVA
Introduction to Two-Way ANOVA
You can use the function anova2 to perform a balanced two-way analysis
of variance (ANOVA). To perform two-way ANOVA for an unbalanced design,
use anovan. For an example, see Two-Way ANOVA for Unbalanced Design.
As in one-way ANOVA, the data for a two-way ANOVA study can be experimental or observational. The difference between one-way and two-way ANOVA is that in two-way ANOVA, the effects of two factors on a response variable are of interest. These two factors can be independent, and have no interaction effect, or the impact of one factor on the response variable can depend on the group (level) of the other factor. If the two factors have no interactions, the model is called an additive model.
Suppose an automobile company has two factories, and each factory makes the same three car models. The gas mileage in the cars can vary from factory to factory and from model to model. These two factors, factory and model, explain the differences in mileage, that is, the response. One measure of interest is the difference in mileage due to the production methods between factories. Another measure of interest is the difference in the mileage of the models (irrespective of the factory) due to different design specifications. The effects of these measures of interest are additive. In addition, suppose only one model has different gas mileage between factories, while the mileage of the other two models is the same between factories. This is called an interaction effect. To measure an interaction effect, there must be multiple observations for some combination of factory and car model. These multiple observations are called replications.
Two-way ANOVA is a special case of the linear model. The two-way ANOVA form of the model is
where,
yijr is an observation of the response variable.
i represents group i of row factor A, i = 1, 2, ..., I.
j represents group j of column factor B, j = 1, 2, ..., J.
r represents the replication number, r = 1, 2, ..., R.
There are a total of N = I*J*R observations.
μ is the overall mean.
αi are the deviations of groups defined by row factor A from the overall mean μ. The values of αi sum to 0.
βj are the deviations of groups defined by column factor B from the overall mean μ. The values of βj sum to 0.
αβij are the interactions. The values in each row and in each column of αβij sum to 0.
εijr are the random disturbances. They are assumed to be independent, normally distributed, and have constant variance.
In the mileage example:
yijr are the gas mileage observations, μ is the overall mean gas mileage.
αi are the deviations of each car's gas mileage from the mean gas mileage μ due to the car's model.
βj are the deviations of each car's gas mileage from the mean gas mileage μ due to the car's factory.
anova2 requires that data be balanced,
so each combination of model and factory must have the same number
of cars.
Two-way ANOVA tests hypotheses about the effects of factors A and B, and their interaction on the response variable y. The hypotheses about the equality of the mean response for groups of row factor A are
The hypotheses about the equality of the mean response for groups of column factor B are
The hypotheses about the interaction of the column and row factors are
Prepare Data for Balanced Two-Way ANOVA
To perform balanced two-way ANOVA using anova2,
you must arrange data in a specific matrix form. The columns of the
matrix must correspond to groups of the column factor, B.
The rows must correspond to the groups of the row factor, A,
with the same number of replications for each combination of the groups
of factors A and B.
Suppose that row factor A has three groups,
and column factor B has two groups (levels). Also
suppose that each combination of factors A and B has
two measurements or observations (reps = 2). Then,
each group of factor A has six observations and
each group of factor B four observations.
The subscripts indicate row, column, and replication, respectively. For example, y221 corresponds to the measurement for the second group of factor A, the second group of factor B, and the first replication for this combination.
Perform Two-Way ANOVA
This example shows how to perform two-way ANOVA to determine the effect of car model and factory on the mileage rating of cars.
Load and display the sample data.
load mileage
mileagemileage = 6×3
33.3000 34.5000 37.4000
33.4000 34.8000 36.8000
32.9000 33.8000 37.6000
32.6000 33.4000 36.6000
32.5000 33.7000 37.0000
33.0000 33.9000 36.7000
There are three car models (columns) and two factories (rows). The data has six mileage rows because each factory provided three cars of each model for the study (i.e., the replication number is three). The data from the first factory is in the first three rows, and the data from the second factory is in the last three rows.
Perform two-way ANOVA. Return the structure of statistics, stats, to use in multiple comparisons.
nmbcars = 3; % Number of cars from each model, i.e., number of replications
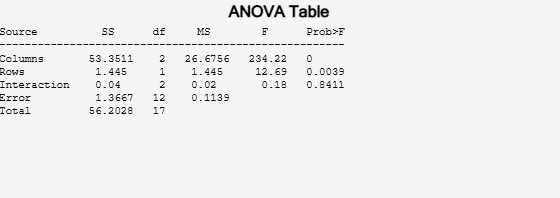
[~,~,stats] = anova2(mileage,nmbcars);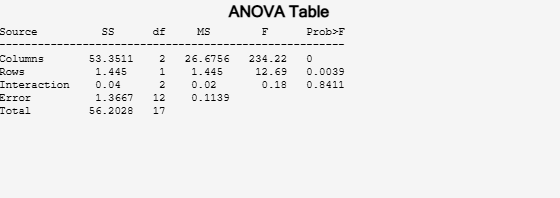
You can use the F-statistics to do hypotheses tests to find out if the mileage is the same across models, factories, and model - factory pairs. Before performing these tests, you must adjust for the additive effects. anova2 returns the p-value from these tests.
The p-value for the model effect (Columns) is zero to four decimal places. This result is a strong indication that the mileage varies from one model to another.
The p-value for the factory effect (Rows) is 0.0039, which is also highly significant. This value indicates that one factory is out-performing the other in the gas mileage of the cars it produces. The observed p-value indicates that an F-statistic as extreme as the observed F occurs by chance about four out of 1000 times, if the gas mileage were truly equal from factory to factory.
The factories and models appear to have no interaction. The p-value, 0.8411, means that the observed result is likely (84 out of 100 times), given that there is no interaction.
Perform Multiple Comparisons to find out which pair of the three car models is significantly different.
c = multcompare(stats);
Note: Your model includes an interaction term. A test of main effects can be difficult to interpret when the model includes interactions.
In the figure, the blue bar is the comparison interval for the mean mileage of the first car model. The red bars are the comparison intervals for the mean mileage of the second and third car models. None of the second and third comparison intervals overlap with the first comparison interval, indicating that the mean mileage of the first car model is different from the mean mileage of the second and the third car models. If you click on one of the other bars, you can test for the other car models. None of the comparison intervals overlap, indicating that the mean mileage of each car model is significantly different from the other two.
Display the multiple comparison results in a table.
tbl = array2table(c,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl=3×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ _______ ___________ __________
1 2 -1.5865 -1.0667 -0.54686 0.00038574
1 3 -4.5865 -4.0667 -3.5469 1.7898e-10
2 3 -3.5198 -3 -2.4802 7.8407e-09
In the matrix c, the first two columns show the pairs of car models that are compared. The last column shows the p-values for the test. All p-values are small, which indicates that the mean mileage of all car models are significantly different from each other.
Mathematical Details
The two-factor ANOVA partitions the total variation into the following components:
Variation of row factor group means from the overall mean,
Variation of column factor group means from the overall mean,
Variation of overall mean plus the replication mean from the column factor group mean plus row factor group mean,
Variation of observations from the replication means,
ANOVA partitions the total sum of squares (SST) into the sum of squares due to row factor A (SSA), the sum of squares due to column factor B (SSB), the sum of squares due to interaction between A and B (SSAB), and the sum of squares error (SSE).
ANOVA takes the variation due to the factor or interaction and compares it to the variation due to error. If the ratio of the two variations is high, then the effect of the factor or the interaction effect is statistically significant. You can measure the statistical significance using a test statistic that has an F-distribution.
For the null hypothesis that the mean response for groups of the row factor A are equal, the test statistic is
For the null hypothesis that the mean response for groups of the column factor B are equal, the test statistic is
For the null hypothesis that the interaction of the column and row factors are equal to zero, the test statistic is
If the p-value for the F-statistic is smaller than the significance level, then ANOVA rejects the null hypothesis. The most common significance levels are 0.01 and 0.05.
ANOVA Table
The ANOVA table captures the variability in the model by the
source, the F-statistic for testing the significance
of this variability, and the p-value for deciding
on the significance of this variability. The p-value
returned by anova2 depends on assumptions about
the random disturbances, εij,
in the model equation. For the p-value to be correct,
these disturbances need to be independent, normally distributed, and
have constant variance. The standard ANOVA table has this form:
| Source | Sum of Squares (SS) | Degrees of Freedom | Mean Squares (MS) | F-statistic | p-value |
|---|---|---|---|---|---|
| Columns | SSA | k – 1 | MSA | MSA/MSE | P(Fk – 1,mk(R – 1))>F |
| Rows | SSB | m – 1 | MSB | MSB/MSE | P(Fm – 1,mk(R – 1))>F |
| Interaction | SSAB | (m – 1)(k – 1) | MSAB | MSAB/MSE | P(F(m – 1)(k – 1),mk(R – 1))>F |
| Error | SSE | mk(R – 1) | MSE | ||
| Total | SST | mkR – 1 |
anova2 returns the standard ANOVA table as
a cell array with six columns.
| Column | Definition |
|---|---|
Source | The source of the variability. |
SS | The sum of squares due to each source. |
df | The degrees of freedom associated with each source. Suppose J is the number of groups in the column factor, I is the number of groups in the row factor, and R is the number of replications. Then, the total number of observations is IJR and the total degrees of freedom is IJR – 1. I – 1 is the degrees of freedom for the row factor,J – 1 is the degrees of freedom for the column factor, (I – 1)(J – 1) is the interaction degrees of freedom, and IJ(R – 1) is the error degrees of freedom. |
MS | The mean squares for each source, which is the ratio SS/df. |
F | F-statistic, which is the ratio of the mean squares. |
Prob>F | The p-value, which is the probability that
the F-statistic can take a value larger than the
computed test-statistic value. anova2 derives this
probability from the cdf of the F-distribution. |
The rows of the ANOVA table show the variability in the data that is divided by the source.
| Row (Source) | Definition |
|---|---|
Columns | Variability due to the column factor |
Rows | Variability due to the row factor |
Interaction | Variability due to the interaction of the row and column factors |
Error | Variability due to the differences between the data in each group and the group mean (variability within groups) |
Total | Total variability |
References
[1] Wu, C. F. J., and M. Hamada. Experiments: Planning, Analysis, and Parameter Design Optimization, 2000.
[2] Neter, J., M. H. Kutner, C. J. Nachtsheim, and W. Wasserman. 4th ed. Applied Linear Statistical Models. Irwin Press, 1996.
See Also
anova | anova1 | anova2 | anovan | multcompare