timedelaynet
(To be removed) Time delay neural network
timedelaynet will be removed in a future release. For more information,
see Transition Legacy Neural Network Code to dlnetwork Workflows.
For advice on updating your code, see Version History.
Description
timedelaynet(
takes these arguments:inputDelays,hiddenSizes,trainFcn)
Row vector of increasing 0 or positive input delays,
inputDelaysRow vector of one or more hidden layer sizes,
hiddenSizesTraining function,
trainFcn
and returns a time delay neural network.
Time delay networks are similar to feedforward networks, except that the input weight
has a tap delay line associated with it. This allows the network to have a finite dynamic
response to time series input data. This network is also similar to the distributed delay
neural network (distdelaynet), which has delays on the layer
weights in addition to the input weight.
Examples
This example shows how to train a time delay network.
Partition the training set. Use Xnew to do prediction in closed loop mode later.
[X,T] = simpleseries_dataset; Xnew = X(81:100); X = X(1:80); T = T(1:80);
Train a time delay network, and simulate it on the first 80 observations.
net = timedelaynet(1:2,10); [Xs,Xi,Ai,Ts] = preparets(net,X,T); net = train(net,Xs,Ts,Xi,Ai);
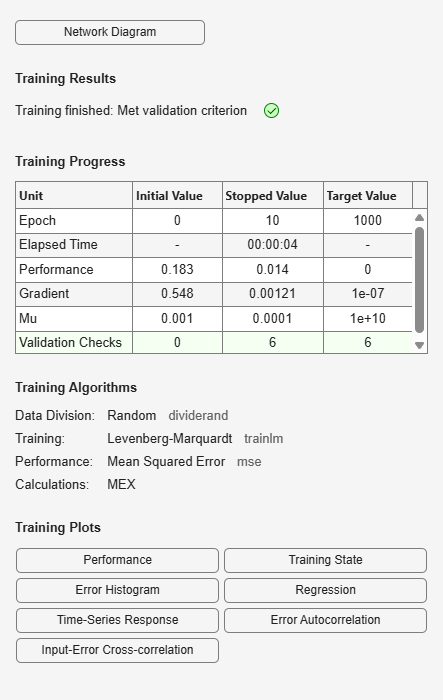
view(net)
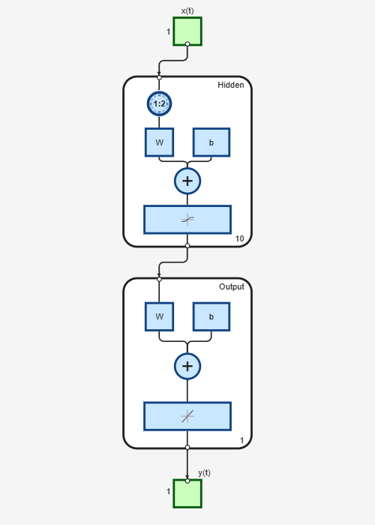
Calculate the network performance.
[Y,Xf,Af] = net(Xs,Xi,Ai); perf = perform(net,Ts,Y);
Run the prediction for 20 timesteps ahead in closed loop mode.
[netc,Xic,Aic] = closeloop(net,Xf,Af); view(netc)
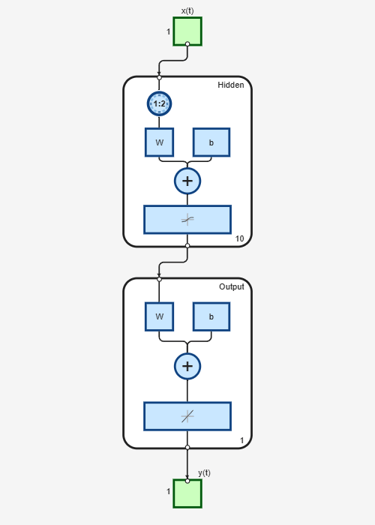
y2 = netc(Xnew,Xic,Aic);