Profiling Explicit Parallel Communication
This example shows how to profile explicit communication to the nearest neighbor worker. It illustrates the use of spmdSend, spmdReceive, and spmdSendReceive, showing both the slow (incorrect) and the fast (optimal) way of implementing this algorithm. The problem is explored using the parallel profiler. For getting started with parallel profiling, see Profiling Parallel Code.
The figures in this example are produced from a 12-node cluster.
The example code involves explicit communication. In MATLAB® explicit communication is synonymous with directly using Parallel Computing Toolbox™ communication primitives (e.g. spmdSend, spmdReceive, spmdSendReceive, spmdBarrier). Performance problems involving this type of communication, if not related to the underlying hardware, can be difficult to trace. With the parallel profiler many of these problems can be interactively identified. It is important to remember you can separate the various parts of your program into separate functions. This can help when profiling, because some data is collected only for each function.
The Algorithm
The algorithm we are profiling is a nearest neighbor communication pattern. Each MATLAB worker needs data only from itself and one neighboring lab. This type of data parallel pattern lends itself well to many matrix problems, but when done incorrectly, can be needlessly slow. In other words, each lab depends on data that is already available on an adjacent lab. For example, on a four-lab cluster, lab 1 wants to send some data to lab 2 and needs some data from lab 4 so each lab depends on only one other lab:
1 depends on -> 4
2 depends on -> 1
3 depends on -> 2
4 depends on -> 3
It is possible to implement any given communication algorithm using spmdSend and spmdReceive. spmdReceive always blocks your program until the communication is complete, while spmdSend might not if the data is small. Using spmdSend first, though, doesn't help in most cases.
One way to accomplish this algorithm is to have every worker wait for a receive, and only one worker start the communication chain by completing a send and then a receive. Alternatively, we can use spmdSendReceive, and at first glance it may not be apparent that there should be a major difference in performance.
You can view the code for pctdemo_aux_profbadcomm and pctdemo_aux_profcomm to see the complete implementations of this algorithm. Look at the first file and notice that it uses spmdSend and spmdReceive for communication.
It is a common mistake to start thinking in terms of spmdSend and spmdReceive when it is not necessary. Looking at how this pctdemo_aux_profbadcomm implementation performs will give us a better idea of what to expect.
Profiling the spmdSend Implementation
spmd spmdBarrier; % to ensure the workers all start at the same time mpiprofile reset; mpiprofile on; pctdemo_aux_profbadcomm; end
Worker 1: sending to 2 Worker 2: receive from 1 Worker 3: receive from 2 Worker 4: receive from 3 Worker 5: receive from 4 Worker 6: receive from 5 Worker 7: receive from 6 Worker 8: receive from 7 Worker 9: receive from 8 Worker 10: receive from 9 Worker 11: receive from 10 Worker 12: receive from 11 Worker 1: receive from 12 Worker 2: sending to 3 Worker 3: sending to 4 Worker 4: sending to 5 Worker 5: sending to 6 Worker 6: sending to 7 Worker 7: sending to 8 Worker 8: sending to 9 Worker 9: sending to 10 Worker 10: sending to 11 Worker 11: sending to 12 Worker 12: sending to 1
mpiprofile viewerThe Parallel Profile Summary report is displayed. On this page, you can see time spent waiting in communications as an orange bar under the Total Time Plot column. The data below shows that considerable amount of time was spent waiting. Let's see how the parallel profiler helps to identify the causes of these waits.
Quickstart Steps
View the Parallel Profile Summary table and click the Max vs. Min Total Time button in the Compare section of the toolstrip. Observe the large orange waiting time indicated for the
pctdemo_aux_profbadcomm>iRecFromPrevLabentry. This is an early indication that there is something wrong with a corresponding send, either because of network problems or algorithm problems.To view the worker to worker communication plots, expand the Plots section of the Parallel Profile Summary and click the Heatmap button in the Plots section of the toolstrip. The first figure in this view shows all the data received by each worker. In this example each worker is receiving the same amount of data from the previous worker, so it doesn't seem to be a data distribution problem. The second figure shows the various communication times including the time spent waiting for communication. In the third figure, the Comm Waiting Time Per Worker plot shows a stepwise increase in waiting time. An example Comm Waiting Time Per Worker plot can be seen below using a 12-node cluster. It is good to go back and check what is happening on the source worker.
Browse what's happening on worker 1. Click the top-level
pctdemo_aux_profbadcommfunction to go to the function detail report. Scroll down to the Function listing section and see where worker 1 spends time and which lines are covered. For comparison with the last worker, select the last worker using the Go to worker menu in the Compare section of the toolstrip, and examine the Busy lines table.
To see all the profiled lines of code, scroll down to the last item in the page. An example of this annotated code listing can be seen below.
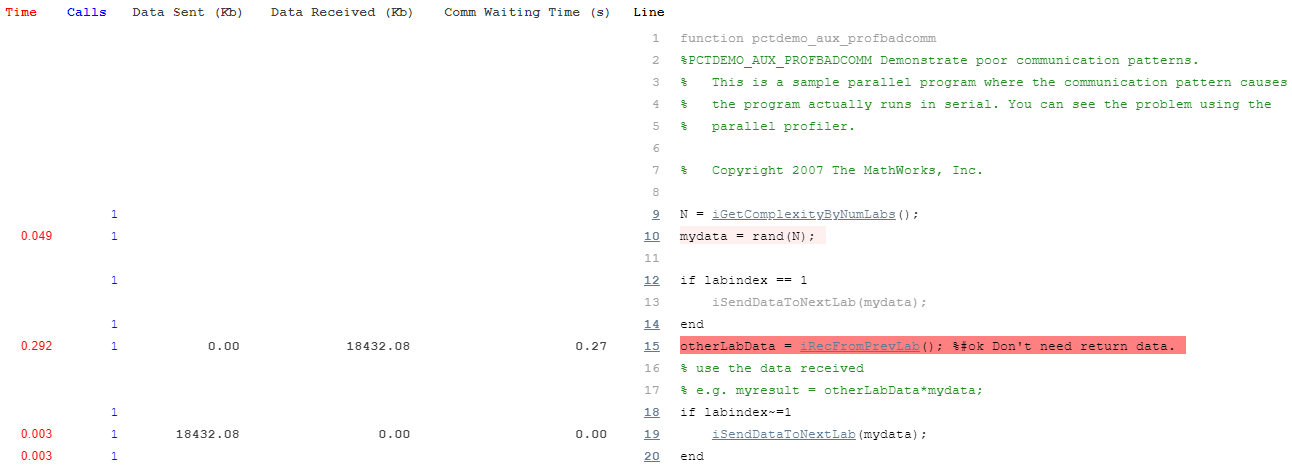
Communication Plots Using a Larger Non-local Cluster
To clearly see the problem with our usage of spmdSend and spmdReceive, look at the following Communication Time (Waiting) plot from a 12-node cluster.
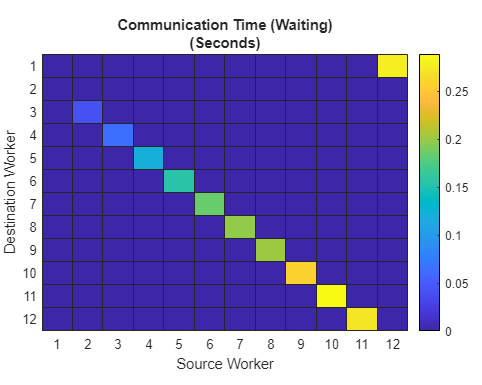
In the plot above, you can see the unnecessary waiting using the plot of worker to worker communication for all functions. The waiting time increases by worker number because spmdReceive blocks until the corresponding paired spmdSend has completed. Hence, you get sequential communication even though subsequent workers only need the data that is originating in the immediate neighbor spmdIndex.
Using spmdSendReceive to Implement This Algorithm
You can use spmdSendReceive to send and receive data simultaneously from the worker that you depend on to get minimal waiting time. You can see this in the corrected version of the communication pattern implemented in pctdemo_aux_profcomm. Clearly, using spmdSendReceive is not possible if you need to receive data before you can send it. In such cases, use spmdSend and spmdReceive to ensure chronological order. However, in cases like this example, when there is no need to receive data before sending, use spmdSendReceive. Profile this version without resetting the data collected on the previous version (use mpiprofile resume).
spmd spmdBarrier; mpiprofile resume; pctdemo_aux_profcomm; end
Worker 1: sending to 2 receiving from 12 Worker 2: sending to 3 receiving from 1 Worker 3: sending to 4 receiving from 2 Worker 4: sending to 5 receiving from 3 Worker 5: sending to 6 receiving from 4 Worker 6: sending to 7 receiving from 5 Worker 7: sending to 8 receiving from 6 Worker 8: sending to 9 receiving from 7 Worker 9: sending to 10 receiving from 8 Worker 10: sending to 11 receiving from 9 Worker 11: sending to 12 receiving from 10 Worker 12: sending to 1 receiving from 11
mpiprofile viewerThis corrected version reduces the waiting time to effectively zero. To see this, view the plots of worker to worker communication for the pctdemo_aux_profcomm function. Using spmdSendReceive, the same communication pattern now spends nearly no time waiting, as shown in the following Communication Time (Waiting) plot.

The Plot Color Scheme
For each 2-D image plot, the coloring scheme is normalized to the task at hand. Therefore, do not use the coloring scheme in the plot shown above to compare with other plots, since colors are normalized and are dependent on the maximum value. For this example, using the max value is the best way to compare the huge difference in waiting times when we use pctdemo_aux_profcomm instead of pctdemo_aux_profbadcomm.