SilhouetteEvaluation
Silhouette criterion clustering evaluation object
Description
SilhouetteEvaluation is an object consisting of sample data
(X), clustering data (OptimalY), and silhouette criterion
values (CriterionValues) used to
evaluate the optimal number of data clusters (OptimalK). The silhouette value for
each point (observation in X) is a measure of how similar that point is to
other points in the same cluster, compared to points in other clusters. If most points have a
high silhouette value, then the clustering solution is appropriate. If many points have a low
or negative silhouette value, then the clustering solution might have too many or too few
clusters. For more information, see Silhouette Value and Criterion.
Creation
Create a silhouette criterion clustering evaluation object by using the evalclusters function and specifying the criterion as
"silhouette".
You can then use compact to create a compact version of the
silhouette criterion clustering evaluation object. The function removes the contents of the
properties X, OptimalY, and
Missing.
Properties
Object Functions
Examples
Evaluate the optimal number of clusters using the silhouette clustering evaluation criterion.
Generate sample data containing random numbers from three multivariate distributions with different parameter values.
rng("default") % For reproducibility n = 200; mu1 = [2 2]; sigma1 = [0.9 -0.0255; -0.0255 0.9]; mu2 = [5 5]; sigma2 = [0.5 0; 0 0.3]; mu3 = [-2 -2]; sigma3 = [1 0; 0 0.9]; X = [mvnrnd(mu1,sigma1,n); ... mvnrnd(mu2,sigma2,n); ... mvnrnd(mu3,sigma3,n)];
Evaluate the optimal number of clusters using the silhouette criterion. Cluster the data using kmeans.
evaluation = evalclusters(X,"kmeans","silhouette","KList",1:6)
evaluation =
SilhouetteEvaluation with properties:
NumObservations: 600
InspectedK: [1 2 3 4 5 6]
CriterionValues: [NaN 0.8055 0.8551 0.7155 0.6071 0.6232]
OptimalK: 3
Properties, Methods
The OptimalK value indicates that, based on the silhouette criterion, the optimal number of clusters is three.
Plot the silhouette criterion values for each number of clusters tested.
plot(evaluation)
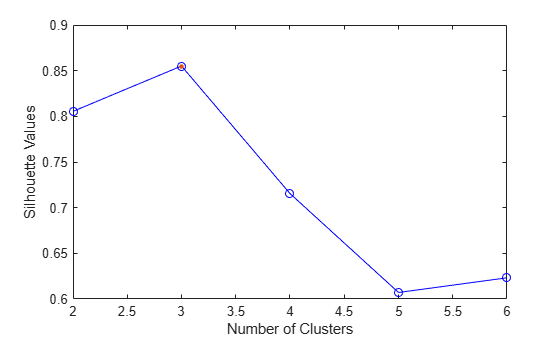
The plot shows that the highest silhouette value occurs at three clusters, suggesting that the optimal number of clusters is three.
Create a grouped scatter plot to visually examine the suggested clusters.
clusters = evaluation.OptimalY;
gscatter(X(:,1),X(:,2),clusters,[],"xod")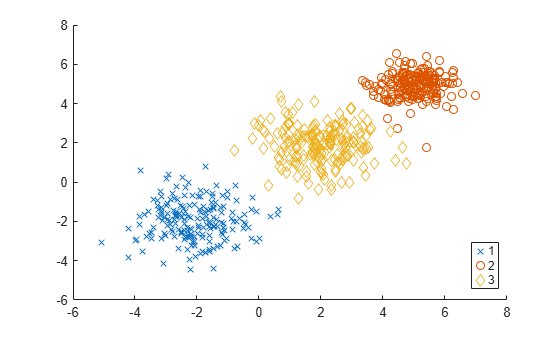
The plot shows three distinct clusters within the data: cluster 1 in the lower-left corner, cluster 2 in the upper-right corner, and cluster 3 near the center of the plot.
More About
References
[1] Kaufman, L., and P. J. Rouseeuw. Finding Groups in Data: An Introduction to Cluster Analysis. Hoboken, NJ: John Wiley & Sons, Inc., 1990.
[2] Rouseeuw, P. J. “Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.” Journal of Computational and Applied Mathematics. Vol. 20, No. 1, 1987, pp. 53–65.
Version History
Introduced in R2013b