fsrftest
Univariate feature ranking for regression using F-tests
Syntax
Description
idx = fsrftest(Tbl,ResponseVarName)Tbl contains predictor variables and a response variable, and ResponseVarName is the name of the response variable in Tbl. The function returns idx, which contains the indices of predictors ordered by predictor importance, meaning idx(1) is the index of the most important predictor. You can use idx to select important predictors for regression problems.
idx = fsrftest(___,Name,Value)
Examples
Rank predictors in a numeric matrix and create a bar plot of predictor importance scores.
Load the sample data.
load robotarm.matThe robotarm data set contains 7168 training observations (Xtrain and ytrain) and 1024 test observations (Xtest and ytest) with 32 features [1][2].
Rank the predictors using the training observations.
[idx,scores] = fsrftest(Xtrain,ytrain);
The values in scores are the negative logs of the p-values. If a p-value is smaller than eps(0), then the corresponding score value is Inf. Before creating a bar plot, determine whether scores includes Inf values.
find(isinf(scores))
ans = 1×0 empty double row vector
scores does not include Inf values. If scores includes Inf values, you can replace Inf by a large numeric number before creating a bar plot for visualization purposes. For details, see Rank Predictors in Table.
Create a bar plot of the predictor importance scores.
bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score')
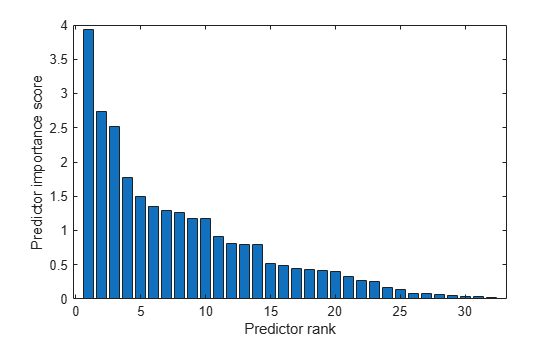
Select the top five most important predictors. Find the columns of these predictors in Xtrain.
idx(1:5)
ans = 1×5
30 24 10 4 5
The 30th column of Xtrain is the most important predictor of ytrain.
Rank predictors in a table and create a bar plot of predictor importance scores.
If your data is in a table and fsrftest ranks a subset of the variables in the table, then the function indexes the variables using only the subset. Therefore, a good practice is to move the predictors that you do not want to rank to the end of the table. Move the response variable and observation weight vector as well. Then, the indexes of the output arguments are consistent with the indexes of the table. You can move variables in a table using the movevars function.
This example uses the Abalone data [3][4] from the UCI Machine Learning Repository [5].
Download the data and save it in your current folder with the name 'abalone.csv'.
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data'; websave('abalone.csv',url);
Read the data in a table.
tbl = readtable('abalone.csv','Filetype','text','ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height', ... 'WWeight','SWeight','VWeight','ShWeight','NoShellRings'};
Preview the first few rows of the table.
head(tbl)
ans=8×9 table
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
_____ ______ ________ ______ _______ _______ _______ ________ ____________
{'M'} 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
{'M'} 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
{'F'} 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
{'M'} 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
{'I'} 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
{'I'} 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
{'F'} 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20
{'F'} 0.545 0.425 0.125 0.768 0.294 0.1495 0.26 16
The last variable in the table is a response variable.
Rank the predictors in tbl. Specify the last column NoShellRings as a response variable.
[idx,scores] = fsrftest(tbl,'NoShellRings')idx = 1×8
3 4 5 7 8 2 6 1
scores = 1×8
447.6891 736.9619 Inf Inf Inf 604.6692 Inf Inf
The values in scores are the negative logs of the p-values. If a p-value is smaller than eps(0), then the corresponding score value is Inf. Before creating a bar plot, determine whether scores includes Inf values.
idxInf = find(isinf(scores))
idxInf = 1×5
3 4 5 7 8
scores includes five Inf values.
Create a bar plot of predictor importance scores. Use the predictor names for the x-axis tick labels.
bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score') xticklabels(strrep(tbl.Properties.VariableNames(idx),'_','\_')) xtickangle(45)
The bar function does not plot any bars for the Inf values. For the Inf values, plot bars that have the same length as the largest finite score.
hold on bar(scores(idx(length(idxInf)+1))*ones(length(idxInf),1)) legend('Finite Scores','Inf Scores') hold off
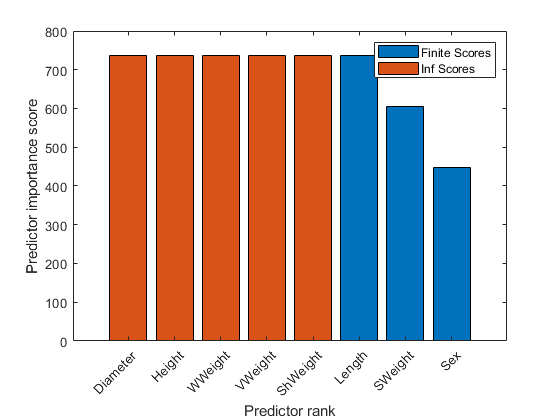
The bar graph displays finite scores and Inf scores using different colors.
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
References
[1] Rasmussen, C. E., R. M. Neal, G. E. Hinton, D. van Camp, M. Revow, Z. Ghahramani, R. Kustra, and R. Tibshirani. The DELVE Manual, 1996.
[2] University of Toronto, Computer Science Department. Delve Datasets.
[3] Nash, W.J., T. L. Sellers, S. R. Talbot, A. J. Cawthorn, and W. B. Ford. "The Population Biology of Abalone (Haliotis species) in Tasmania. I. Blacklip Abalone (H. rubra) from the North Coast and Islands of Bass Strait." Sea Fisheries Division, Technical Report No. 48, 1994.
[4] Waugh, S. "Extending and Benchmarking Cascade-Correlation: Extensions to the Cascade-Correlation Architecture and Benchmarking of Feed-forward Supervised Artificial Neural Networks." University of Tasmania Department of Computer Science thesis, 1995.
[5] Lichman, M. UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science, 2013. http://archive.ics.uci.edu/ml.
Version History
Introduced in R2020a