run
Syntax
Description
output1 = run(learnedPipe,input1,...,inputN)learnedPipe that are required to return output1.
The function ignores nodes that are not required to return the output.
___ = run(___,
specifies optional run parameters in addition to any of the input or output argument
combinations in previous syntaxes. The software forwards the run parameter values to
individual components during the execution of Name,Value)learnedPipe.
If
learnedPipeis aLearningPipelineobject, then specifyNameas the component name with/as a prefix to the parameter name, to disambiguate between components that have the same parameter name. For example, specifyrun(learnedPipe,X,Y,"ClassificationSVM/LossFun","classifcost").If
learnedPipeis a learning component object, then specifyNameas the parameter name. In this case, you can use theName=Valuesyntax. For example, specifyrun(learnedPipe,X,Y,LossFun="classifcost"). Usehelp(learnedPipe)to see the available run parameters.
Examples
Create a pipeline with two components: one that performs principal component analysis and retains three components, and one that performs ECOC classification.
pca = pcaComponent(NumComponents=3); ecoc = classificationECOCComponent; pipeline = series(pca,ecoc);
Load sample data and partition the data into training and test data.
fisheriris = readtable("fisheriris.csv"); rng("default") cvp = cvpartition(fisheriris.Species,Holdout=0.25,Stratify=true); idxTrain = training(cvp); Xtrain = fisheriris(idxTrain,1:end-1); Ytrain = fisheriris(idxTrain,end); idxTest = test(cvp); Xtest = fisheriris(idxTest,1:end-1); Ytest = fisheriris(idxTest,end);
Evaluate the pipeline using the training data.
learnedPipeline = learn(pipeline,Xtrain,Ytrain);
Compute the predicted response values for the test data, and plot the confusion matrix to compare the results with the actual labels. Provide only the input required for predicting the response values.
Ypredicted = run(learnedPipeline,Xtest);
confusionchart(Ytest{:,:},Ypredicted{:,:})
You can ask for additional outputs in the order specified by the pipeline
Outputs property. Compute the predictions, classification scores,
and loss on the test set.
[predictions,scores,loss] = run(learnedPipeline,Xtest,Ytest);
Create a pipeline that performs principal component analysis and classification using ECOC.
pca = pcaComponent; ecoc = classificationECOCComponent; pipeline = series(pca,ecoc);
Load sample data and define the predictor and response variables.
fisheriris = readtable("fisheriris.csv");
X = fisheriris(:,1:end-1);
Y = fisheriris(:,end);Execute the pipeline for different numbers of principal components, and plot the loss values.
numComponents = 1:4; losses = zeros(1,numel(numComponents)); for j = 1:numel(numComponents) pipeline.Components.PCA.NumComponents = numComponents(j); learnedPipeline = learn(pipeline,X,Y); [~,~,losses(j)] = run(learnedPipeline,X,Y); end plot(numComponents,losses,"o:") xlabel("Number of Components") ylabel("Loss")
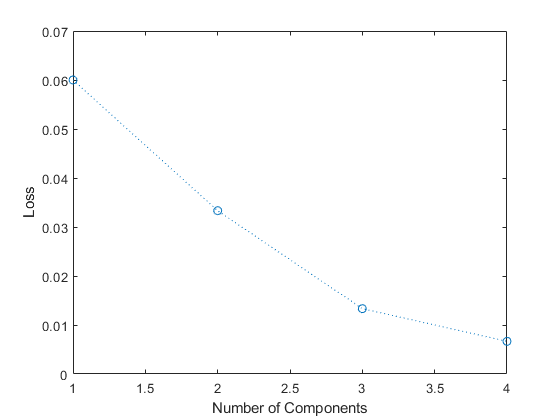
The resubstitution loss value decreases as the number of principal components increases.
Input Arguments
Output Arguments
Version History
Introduced in R2026a