mnrval
(Not recommended) Multinomial logistic regression values
mnrval is not recommended.
Instead, use fitmnr
to create a MultinomialRegression model object and then use the predict
object function. (since R2023a) For more information see Version History.
Syntax
Description
pihat = mnrval(B,X)X, and the coefficient estimates,
B.
pihat is an
n-by-k matrix of predicted
probabilities for each multinomial category. B is the vector
or matrix that contains the coefficient estimates returned by mnrfit. And X is
an n-by-p matrix which contains
n observations for p
predictors.
Note
mnrval automatically includes a constant term in
all models. Do not enter a column of 1s in X.
[
also returns 95% error bounds on the predicted probabilities,
pihat,dlow,dhi]
= mnrval(B,X,stats)pihat, using the statistics in the structure,
stats, returned by mnrfit.
The lower and upper confidence bounds for pihat are
pihat minus dlow and
pihat plus dhi, respectively.
Confidence bounds are nonsimultaneous and only apply to the fitted curve, not to
new observations.
[
returns the predicted probabilities and 95% error bounds on the predicted
probabilities pihat,dlow,dhi]
= mnrval(B,X,stats,Name,Value)pihat, with additional options specified by one
or more Name,Value pair arguments.
For example, you can specify the model type, link function, and the type of probabilities to return.
[
also computes 95% error bounds on the predicted counts yhat,dlow,dhi]
= mnrval(B,X,ssize,stats)yhat,
using the statistics in the structure, stats, returned by
mnrfit.
The lower and upper confidence bounds for yhat are
yhat minus dlo and
yhat plus dhi, respectively.
Confidence bounds are nonsimultaneous and they apply to the fitted curve, not to
new observations.
[
returns the predicted category counts and 95% error bounds on the predicted
counts yhat,dlow,dhi]
= mnrval(B,X,ssize,stats,Name,Value)yhat, with additional options specified by one or more
Name,Value pair arguments.
For example, you can specify the model type, link function, and the type of predicted counts to return.
Examples
Fit a multinomial regression for nominal outcomes and estimate the category probabilities.
Load the sample data.
load fisheririsThe column vector, species, consists of iris flowers of three different species: setosa, versicolor, virginica. The double matrix meas consists of four types of measurements on the flowers, the length and width of sepals and petals in centimeters, respectively.
Define the nominal response variable.
sp = nominal(species); sp = double(sp);
Now in sp, 1, 2, and 3 indicate the species setosa, versicolor, and virginica, respectively.
Fit a nominal model to estimate the species using the flower measurements as the predictor variables.
[B,dev,stats] = mnrfit(meas,sp);
Estimate the probability of being a certain kind of species for an iris flower having the measurements (6.3, 2.8, 4.9, 1.7).
x = [6.3, 2.8, 4.9, 1.7]; pihat = mnrval(B,x); pihat
pihat = 1×3
0 0.3977 0.6023
The probability of an iris flower having the measurements (6.3, 2.8, 4.9, 1.7) being a setosa is 0, a versicolor is 0.3977, and a virginica is 0.6023.
Fit a multinomial regression model for categorical responses with natural ordering among categories. Then estimate the upper and lower confidence bounds for the category probability estimates.
Load the sample data and define the predictor variables.
load('carbig.mat')
X = [Acceleration Displacement Horsepower Weight];The predictor variables are the acceleration, engine displacement, horsepower, and the weight of the cars. The response variable is miles per gallon (MPG).
Create an ordinal response variable categorizing MPG into four levels from 9 to 48 mpg.
miles = ordinal(MPG,{'1','2','3','4'},[],[9,19,29,39,48]);
miles = double(miles);Now in miles, 1 indicates the cars with miles per gallon from 9 to 19, and 2 indicates the cars with miles per gallon from 20 to 29. Similarly, 3 and 4 indicate the cars with miles per gallon from 30 to 39 and 40 to 48, respectively.
Fit a multinomial regression model for the response variable miles. For an ordinal model, the default 'link' is logit and the default 'interactions' is 'off'.
[B,dev,stats] = mnrfit(X,miles,'model','ordinal');
Compute the probability estimates and 95% error bounds for probability confidence intervals for miles per gallon of a car with = (12, 113, 110, 2670).
x = [12,113,110,2670]; [pihat,dlow,hi] = mnrval(B,x,stats,'model','ordinal'); pihat
pihat = 1×4
0.0615 0.8426 0.0932 0.0027
Calculate the confidence bounds for the category probability estimates.
LL = pihat - dlow; UL = pihat + hi; [LL;UL]
ans = 2×4
0.0073 0.7829 0.0283 -0.0003
0.1157 0.9022 0.1580 0.0057
Fit a multinomial regression for nominal outcomes and estimate the category counts.
Load the sample data.
load fisheririsThe column vector, species, consists of iris flowers of three different species: setosa, versicolor, and virginica. The double matrix meas consists of four types of measurements on the flowers, the length and width of sepals and petals in centimeters, respectively.
Define the nominal response variable.
sp = nominal(species); sp = double(sp);
Now in sp, 1, 2, and 3 indicate the species setosa, versicolor, and virginica, respectively.
Fit a nominal model to estimate the species based on the flower measurements.
[B,dev,stats] = mnrfit(meas,sp);
Estimate the number in each species category for a sample of 100 iris flowers all with the measurements (6.3, 2.8, 4.9, 1.7).
x = [6.3, 2.8, 4.9, 1.7]; yhat = mnrval(B,x,18)
yhat = 1×3
0 7.1578 10.8422
Estimate the error bounds for the counts.
[yhat,dlow,hi] = mnrval(B,x,18,stats,'model','nominal');
Calculate the confidence bounds for the category probability estimates.
LL = yhat - dlow; UL = yhat + hi; [LL;UL]
ans = 2×3
0 3.3019 6.9863
0 11.0137 14.6981
Create sample data with one predictor variable and a categorical response variable with three categories.
x = [-3 -2 -1 0 1 2 3]';
Y = [1 11 13; 2 9 14; 6 14 5; 5 10 10;...
5 14 6; 7 13 5; 8 11 6];
[Y x]ans = 7×4
1 11 13 -3
2 9 14 -2
6 14 5 -1
5 10 10 0
5 14 6 1
7 13 5 2
8 11 6 3
There are observations on seven different values of the predictor variable x. The response variable Y has three categories and the data shows how many of the 25 individuals are in each category of Y for each observation of x. For example, when x is -3, 1 of 25 individuals is observed in category 1, 11 observed in category 2, and 13 observed in category 3. Similarly, when x is 1, 5 of the individuals are observed in category 1, 14 are observed in category 2, and 6 are observed in category 3.
Plot the number in each category versus the x values, on a stacked bar graph.
bar(x,Y,'stacked');
ylim([0 25]);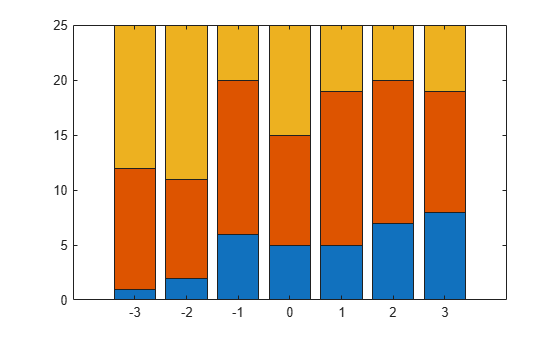
Fit a nominal model for the individual response category probabilities, with separate slopes on the single predictor variable, x, for each category.
betaHatNom = mnrfit(x,Y,'model','nominal',... 'interactions','on')
betaHatNom = 2×2
-0.6028 0.3832
0.4068 0.1948
The first row of betaHatOrd contains the intercept terms for the first two response categories. The second row contains the slopes. mnrfit accepts the third category as the reference category and hence assumes the coefficients for the third category are zero.
Compute the predicted probabilities for the three response categories.
xx = linspace(-4,4)'; piHatNom = mnrval(betaHatNom,xx,'model','nominal',... 'interactions','on');
The probability of being in the third category is simply 1 - P( = 1) - P( = 2).
Plot the estimated cumulative number in each category on the bar graph.
line(xx,cumsum(25*piHatNom,2),'LineWidth',2);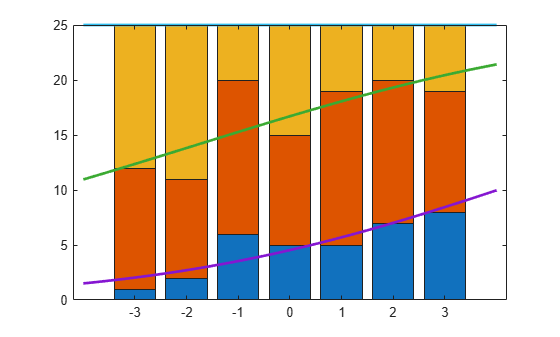
The cumulative probability for the third category is always 1.
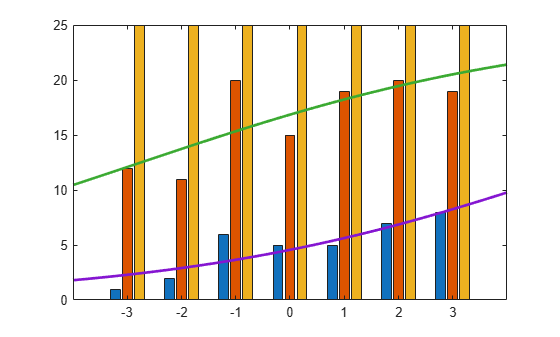
Now, fit a "parallel" ordinal model for the cumulative response category probabilities, with a common slope on the single predictor variable, x, across all categories:
betaHatOrd = mnrfit(x,Y,'model','ordinal',... 'interactions','off')
betaHatOrd = 3×1
-1.5001
0.7266
0.2642
The first two elements of betaHatOrd are the intercept terms for the first two response categories. The last element of betaHatOrd is the common slope.
Compute the predicted cumulative probabilities for the first two response categories. The cumulative probability for the third category is always 1.
piHatOrd = mnrval(betaHatOrd,xx,'type','cumulative',... 'model','ordinal','interactions','off');
Plot the estimated cumulative number on the bar graph of the observed cumulative number.
figure() bar(x,cumsum(Y,2),'grouped'); ylim([0 25]); line(xx,25*piHatOrd,'LineWidth',2);
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.