Vorbis Decoder
This example shows how to implement a Vorbis decoder, which is a freeware, open-source alternative to the MP3 standard. This audio decoding format supports the segmentation of encoded data into small packets for network transmission.

Vorbis Basics
The Vorbis encoding format [1] is an open-source lossy audio compression algorithm similar to MPEG-1 Audio Layer 3, more commonly known as MP3. Vorbis has many of the same features as MP3, while adding flexibility and functionality. The Vorbis specification only defines the format of the bitstream and the decoding algorithm. This allows developers to improve the encoding algorithm over time and remain compatible with existing decoders.
Encoding starts by splitting the original signal into overlapping frames. Vorbis allows frames of different lengths so that it can efficiently handle stationary and transient signals. Each frame is multiplied by a window and transformed using the modified discrete cosine transform (mdct). The frames are then split into a rough approximation called the floor, and a remainder called the residue.
The flexibility of the Vorbis format is illustrated by its use of different methods to represent and encode the floor and residue portions of the signal. The algorithm introduces modes as a mechanism to specify these different methods and thereby code various frames differently.
Vorbis uses Huffman coding to compress the data contained in the floor and residue portions. Vorbis uses a dynamic probability model rather than the static probability model of MP3. Specifically, Vorbis builds custom codebooks for audio signals, which can differ for 'floor' and 'residue' and from frame to frame.
After Huffman encoding is complete, the frame data is bitpacked into a logical packet. In Vorbis, a series of such packets is always preceded by a header. The header contains all the information needed for correct decoding. This information includes a complete set of codebooks, descriptions of methods to represent the floor and residue, and the modes and mappings for multichannel support. The header can also include general information such as bit rates, sampling rate, song and artist names, etc.
Vorbis provides its own format, known as 'Ogg', to encapsulate logical packets into transport streams. The Ogg format provides mechanisms such as framing, synchronization, positioning, and error correction, which are necessary for data transfer over networks.
Problem Overview and Design Details
The Vorbis decoder in this example implements the specifications of the Vorbis I format, which is a subset of Vorbis. The example model decodes any raw binary OGG file containing a mono or stereo audio signal. The example model has the capability to decode and play back a wide variety of Vorbis audio files in real time.
You can test this example with any Vorbis audio file, or with the included handel file. To load the file into the model, replace the file name in the annotated code at the top level of the model with the name of the file you want to test. When this step is complete, click the annotated code to load the new audio file. The model is configured to notify you if the output sampling rate has been changed due to a change in the input data. In this case, the simulation needs to be restarted with the new sample rate.
In order to implement a Vorbis decoder in Simulink®, you must address the variable-sized data packets. This example addresses the variable-sized packets by capturing a whole page of the Ogg bitstream using the 'OggS' synchronization pattern. For practical purposes, a page is assumed to be no larger than 5500 bytes. After obtaining a segmentation table at the beginning of the page, the model extracts logical packets from the remainder of the page. Asynchronous control over the decoding sequence is implemented using the Stateflow chart 'Decode All Pages of Data'.
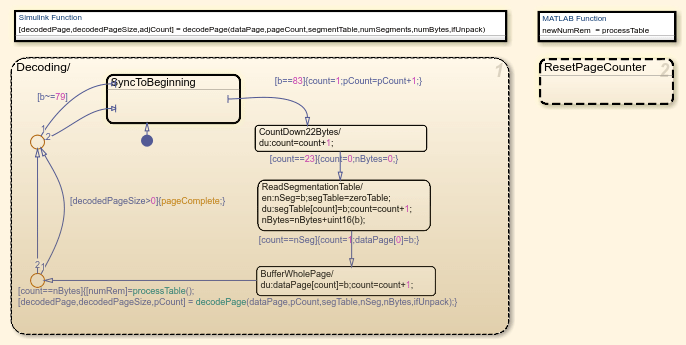
Initially, the chart tries to detect the 'OggS' synchronization pattern and then follow the decoding steps described above. Decoding the page is done with the Simulink function 'decodePage' and then the model immediately goes back to detecting the next 'OggS' sequence. The state 'ResetPageCounter' is added in parallel with the Stateflow algorithm described above to support the looping of the compressed input file for an unlimited number of iterations.
Data pages contain different types of information: header, codebooks, and audio signal data. The 'Read Setup Info', 'Read the Header', and 'Decode Audio' subsystems inside the 'decodePage' Simulink function are responsible for handling each of these different kinds of information.
The decoding process is implemented using MATLAB Function blocks. Most bit-unpacking routines in the example are implemented with MATLAB code.
The recombining of the floor and residue and the subsequent inverse MDCT (IMDCT) are also implemented with a MATLAB Function block that uses the fast imdct function of Audio Toolbox. The variable frame lengths are taken into account using a fixed-size maximum-length frame at the input and output of the Function block, and by using a window length parameter in both the Function block code and a Selector block immediately following the Function block.

The IMDCT transforms the frames back to the time domain, ready to be multiplied by the synthesis window and then combined with an overlap-add operation.
The output block in the top level of the model feeds the output of the decoding block to the audio playback device on your system. The valid portion of the decoded signal is input to the Audio Device Writer block.
References
[1] Complete specification of the Vorbis decoder standard https://xiph.org/vorbis/doc/Vorbis_I_spec.html
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)