Train Policy Deployed on Raspberry Pi
This example shows how to train an agent in MATLAB® on a desktop computer using data generated by a policy deployed on a Raspberry Pi® board. The policy controls a simulated environment, also running on the board.
Introduction
When an agent needs to interact with a physical system, in theory, you could use a few different architectures to allocate the required computations. Three different architectures, with their advantages and disadvantaged are discussed in Examine Approaches to Fine Tune a Deployed Policy. This example implement the third discussed architecture.
Here, the learning algorithm runs in a MATLAB process running on a desktop computer, while the policy (that is, the control process) runs on a Raspberry Pi board. The policy collects experiences by interacting with the physical system, and periodically sends these experiences to the learning process. The learning process then uses the experiences received from the policy process to update the actor and critic parameters of the agent, and then periodically sends the updated actor parameters to the control process. The control process then updates the policy parameters with the new parameters received by the learning process.
The figure illustrates this architecture.
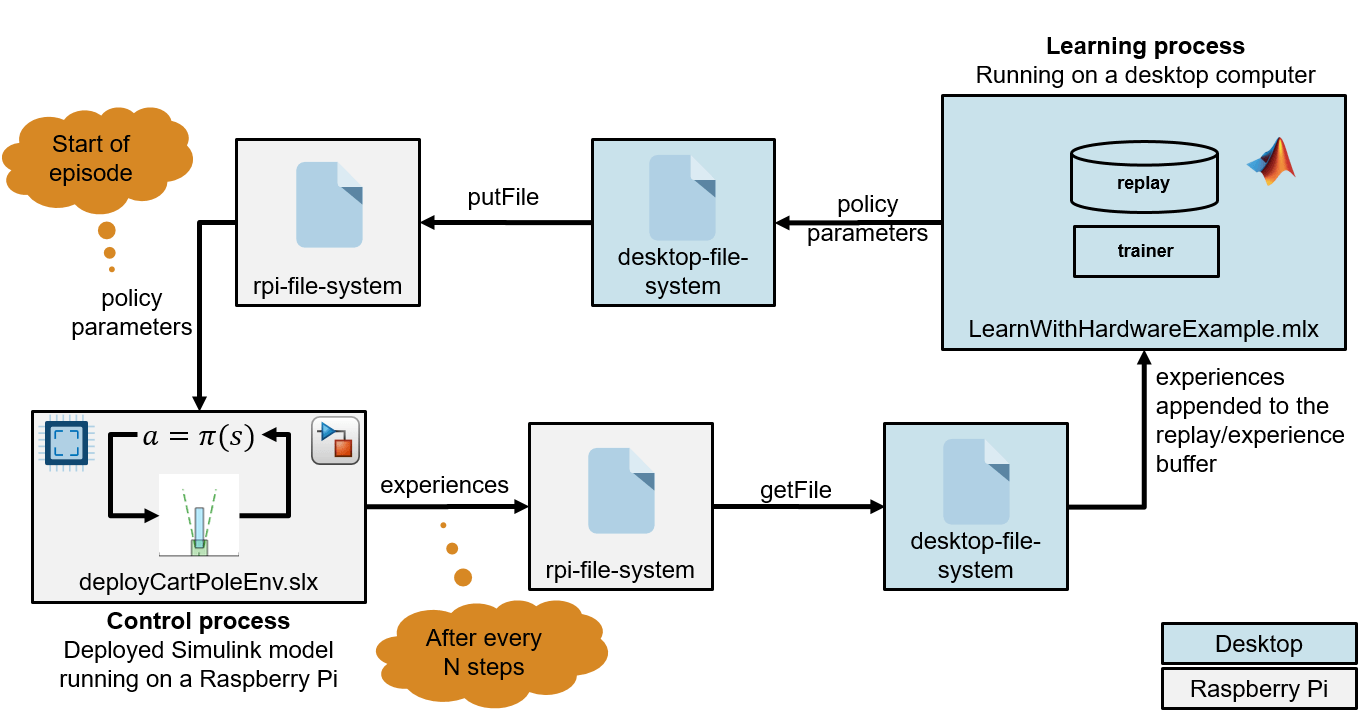
In this figure, the control process is deployed (from a Simulink® model) on an Raspberry Pi board. The control process runs the agent policy, which collects experiences by controlling a simulated cart-pole environment. The process regularly updates its policy parameters with new policy parameters read from a parameter file that the learning process regularly writes on the RPI board. The control process also periodically saves the collected experiences to experience files in the Raspberry Pi board file system.
The learning process runs (in MATLAB) on a desktop computer. This process reads the files on the Raspberry Pi board that contain the new collected experiences, uses the experiences to train the agent, and periodically writes on the Raspberry Pi board a file that contains new policy parameters for the control board to read.
Create Cart-Pole Environment Specifications
Within the control process, the policy interacts with a simulated continuous action space cart-pole environment. In this environment, the goal of the agent is to balance a pole in an upright position on a moving cart by applying a horizontal force to the cart.
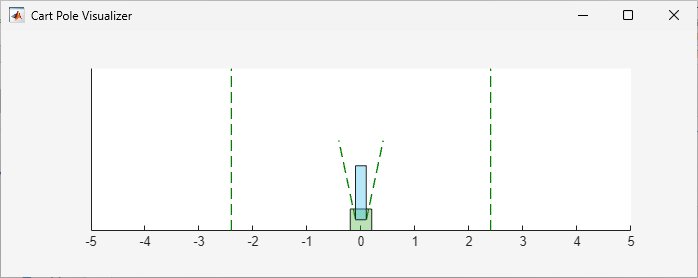
For this environment:
The upward balanced pendulum position is zero radians and the downward hanging position is
piradians.The pendulum starts upright with an initial angle of zero radians.
The force action signal from the agent to the environment is from –10 N to 10 N. A positive force value pushes the cart to the right, while a negative force value pushes it to the left.
The observations from the environment are the position and velocity of the cart, the pendulum angle (clockwise-positive), and the pendulum angle derivative.
The episode terminates if the pole is more than 12 degrees from vertical or if the cart moves more than 2.4 m from the original position.
A reward of +0.5 is provided for every time-step that the pole remains upright. An additional reward is provided based on the distance between the cart and the origin. A penalty of –50 is applied when the pendulum falls.
The sample time for the environment and the agent is 0.02 seconds.
Define the observation specification obsInfo and the action specification actInfo.
obsInfo = rlNumericSpec([4 1]); obsInfo.Name = "CartPole States"; obsInfo.Description = "x, dx, theta, dtheta"; actInfo = rlNumericSpec([1 1]); actInfo.LowerLimit = -10; actInfo.UpperLimit = 10; actInfo.Name = "CartPole Action";
Define the sample time.
sampleTime = 0.02;
Review Control Process Simulink Model and Define Environment Parameters
The control process code is generated from a Simulink model and deployed on the Raspberry Pi board. This process runs indefinitely, because the stop time of the Simulink models used to generate the process executable is set to Inf.
Open the model.
mdl = 'deployCartPoleEnv';
open_system(mdl);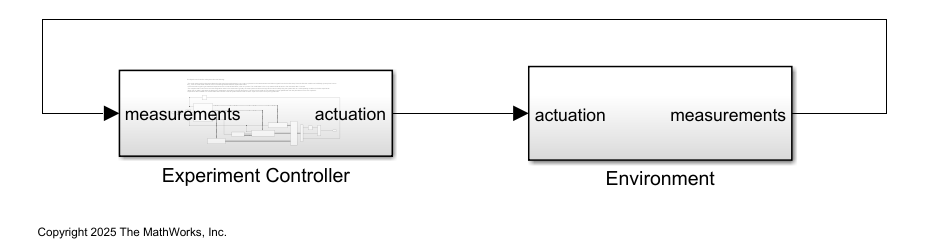
This model consists of two main subsystems:
The
Environmentsubsystem models the continuous action space cart-pole environment.The
ExperimentControllersubsystem contains the reinforcement learning policy, the experiment mode state switching control module, the policy parameter update module, and the experience saving module.
The Environment subsystem implements the cart-pole system. Specifically, the CartPole block takes actuation u (the horizontal force applied to the cart), initial state state0, and reset signal as inputs and returns the next state state and the derivative of the state dstate as outputs.
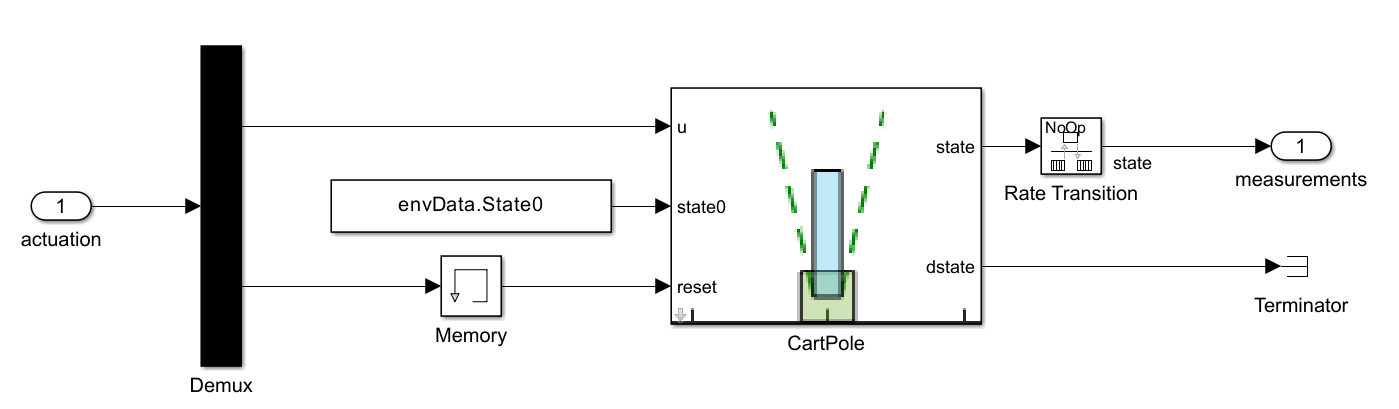
Within the Experiment Controller subsystem:
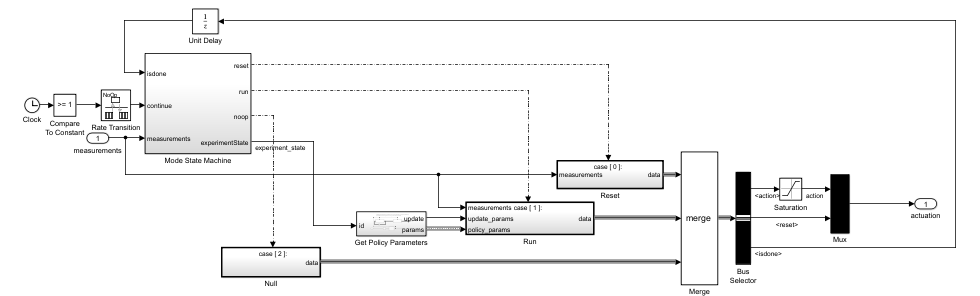
The
ModeStateMachinesubsystem determines the experiment mode states (no-op, reset, run) based on the measurements andisdonesignals from the last time step. Because the Simulink model runs indefinitely (its stop time is set toInf), the mode state machine is the one switching between different experiment states.The subsystem generates a zero actuation signal and does not transmit experiences when in the no-op state. The model starts in the no-op state and will advance to the reset state after one second.
The cart-pole state is set back to its initial configuration when in the reset state. Typically, the reset system involves logic and control to safely bring the system back to a valid operating condition for further experiments. This reset system is a critical part of the experiment process.
When the run state is activated, a MATLAB function called by the
GetPolicyParameterssubsystem reads the latest policy parameters from a parameter file in the Raspberry Pi file system. The policy block inside theRunsubsystem is then updated with the new parameters for the next "episode".
The
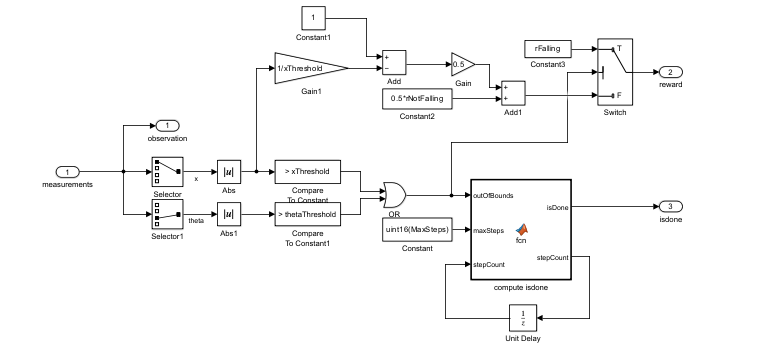
ProcessDatasubsystem (under theRunsubsystem, and shown in the following figure) computes the observation, reward, andisdonesignals given the measurements from theEnvironmentsubsystem. For this example, the observation is identical to the measurements.
The
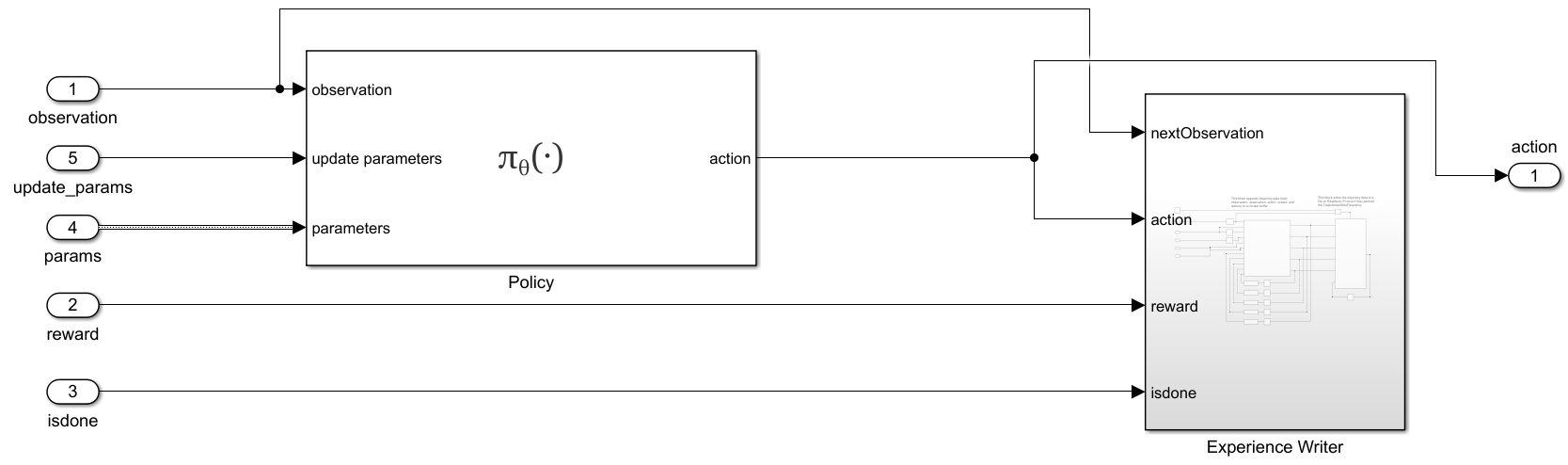
RemoteAgentsubsystem (under theRunsubsystem, and shown in the following figure) maps observations to actions using the updated policy parameters. Additionally, theExperienceWritersubsystem collects experiences in a circular buffer and writes the buffer to experience files in the Raspberry Pi file system, with a frequency given by theenvData.ExperiencesWriteFrequencyparameter.
You can use the command generatePolicyBlock(agent) to generate a Simulink policy block. For more information, see generatePolicyBlock.
Use the helper function environmentParameters to define the parameters needed by the environment. This function is defined at the end of this example.
envData = environmentParameters(sampleTime);
Create a structure representing a circular buffer to store experiences. The buffer is saved to a file based on the writing frequency specified by envData.ExperiencesWriteFrequency.
tempExperienceBuffer.NextObservation = ... zeros(obsInfo.Dimension(1),envData.ExperiencesWriteFrequency); tempExperienceBuffer.Observation = ... zeros(obsInfo.Dimension(1),envData.ExperiencesWriteFrequency); tempExperienceBuffer.Action = ... zeros(actInfo.Dimension(1),envData.ExperiencesWriteFrequency); tempExperienceBuffer.Reward = ... zeros(1,envData.ExperiencesWriteFrequency); tempExperienceBuffer.IsDone = ... zeros(1,envData.ExperiencesWriteFrequency,"uint8");
You use this structure as a reference when the policy parameters are converted from bytes of data to a structure (deserialization).
agentData.TempExperienceBuffer = tempExperienceBuffer;
Create SAC Agent
Fix the random number stream with the seed 0 and random number algorithm Mersenne Twister to reproduce the same initial learnables used in the agent. For more information on controlling the seed used for random number generation, see rng.
previousRngState = rng(0,"twister");The output previousRngState is a structure that contains information about the previous state of the stream. You restore the state at the end of the example.
Create an agent initialization object to initialize the actor and critic networks with the hidden layer size 128. For more information on agent initialization options, see rlAgentInitializationOptions.
initOptions = rlAgentInitializationOptions("NumHiddenUnit",128);Create a SAC agent using the observation and action input specifications, and initialization options. For more information, see rlSACAgent.
agent = rlSACAgent(obsInfo,actInfo,initOptions);
Specify the agent options for training. For more information, see rlSACAgentOptions. For this training:
Specify the sample time, experience buffer length, and mini-batch size.
Specify the actor and critic learning rates to be
1e-3, and entropy weight learning rate to be3e-4. A large learning rate causes drastic updates that can lead to divergent behaviors, while a low value can require many updates before reaching the optimal point.Use a gradient threshold of
1to clip the gradients. Clipping the gradients can improve training stability.Specify the initial entropy component weight and the target entropy value.
agent.SampleTime = sampleTime; agent.AgentOptions.ExperienceBufferLength = 1e6; agent.AgentOptions.MiniBatchSize = 128; agent.AgentOptions.LearningFrequency = 1; agent.AgentOptions.MaxMiniBatchPerEpoch = 1; agent.AgentOptions.ActorOptimizerOptions.LearnRate = 1e-3; agent.AgentOptions.ActorOptimizerOptions.GradientThreshold = 1; for c = 1:2 agent.AgentOptions.CriticOptimizerOptions(c).LearnRate = 1e-3; agent.AgentOptions.CriticOptimizerOptions(c).GradientThreshold = 1; end agent.AgentOptions.EntropyWeightOptions.LearnRate = 3e-4; agent.AgentOptions.EntropyWeightOptions.EntropyWeight = 0.1; agent.AgentOptions.EntropyWeightOptions.TargetEntropy = -1;
Define offline (train from data) training options using the rlTrainingFromDataOptions object. You use trainFromData to train the agent from the collected experience data appended to the experience buffer. Set the number of steps to 100 and the max epochs to 1 to take 100 learning steps to train the agent when new experiences are collected. The actual training progress (episode rewards) can be obtained from the control process and it is not necessary to plot the progress of offline training.
trainFromDataOptions = rlTrainingFromDataOptions;
trainFromDataOptions.MaxEpochs = 1;
trainFromDataOptions.NumStepsPerEpoch = 100;
trainFromDataOptions.Plots = "none";
agentData.Agent = agent;
agentData.TrainFromDataOptions = trainFromDataOptions;Build, Deploy, and Start the Control Process on Raspberry Pi Board
Connect to the Raspberry Pi board using the IP address, user name, and password. For this example, you need to install the Raspberry Pi® Blockset. See Get Started with Raspberry Pi Blockset (Raspberry Pi Blockset) for more information about how to install the support package and set up your Raspberry Pi hardware.
Replace the information in the code below with the login credentials of your Raspberry Pi board.
ipaddress ="172.31.172.54"; username =
"guestuser"; password =
"guestpasswd";
Create a raspberrypi object and store it in the agentData structure.
agentData.RPi = raspberrypi(ipaddress,username,password)
agentData = struct with fields:
TempExperienceBuffer: [1×1 struct]
Agent: [1×1 rl.agent.rlSACAgent]
TrainFromDataOptions: [1×1 rl.option.rlTrainingFromDataOptions]
RPi: [1×1 raspberrypi]
Create variables that store the folder and file information for parameters and experiences.
% Folder for storing experiences on Raspberry experiencesFolderRPi = "~/cartPoleExperiments/experiences/"; % Folder for storing parameters on Raspberry parametersFolderRPi = "~/cartPoleExperiments/parameters/"; % Folder for storing experiences on desktop computer experiencesFolderDesktop = ... fullfile(".","cartPoleExperiments","experiences/"); % Folder for storing parameters on desktop computer parametersFolderDesktop = ... fullfile(".","cartPoleExperiments","parameters/"); parametersFile = "parametersFile.dat";
Use the structure agentData to store information related to the agent.
agentData.ExperiencesFolderRPi = experiencesFolderRPi; agentData.ExperiencesFolderDesktop = experiencesFolderDesktop; agentData.ParametersFolderRPi = parametersFolderRPi; agentData.ParametersFolderDesktop = parametersFolderDesktop; agentData.ParametersFile = parametersFile;
Create a local folder to save the parameters and experiences if it doesn't already exist.
if ~exist(fullfile(".","cartPoleExperiments/"),'dir') % Create the experiences folder. mkdir(fullfile(".","cartPoleExperiments/")); end
Remove files containing variables that store old experience information if the experiences folder exists.
if exist(experiencesFolderDesktop,'dir') % If the experiences folder exists, % remove the folder to delete any old files rmdir(experiencesFolderDesktop,'s'); end
Create the folder to collect the experiences.
mkdir(experiencesFolderDesktop);
Remove files containing variables that store old parameter information if the parameters folder exists.
if exist(parametersFolderDesktop,'dir') % If the parameter folder exists, % remove the folder to delete any old files. rmdir(parametersFolderDesktop,'s'); end
Make the parameters folder.
mkdir(parametersFolderDesktop);
Check if the folder where experience files are stored exists on the RPi. If the folder does not exist, create one. To create the folder, use the supporting function createFolderOnRPi, which is defined at the end of this example. This function uses the system command, with the Raspberry Pi object as a first input argument, to send a command to the Raspberry Pi Linux® operating system. For more information, see Run Linux Shell Commands on Raspberry Pi Hardware (Raspberry Pi Blockset).
createFolderOnRPi(agentData.RPi,agentData.ExperiencesFolderRPi);
Check if the parameters folder exists on the RPi. If not, create one.
createFolderOnRPi(agentData.RPi,agentData.ParametersFolderRPi);
Read the current state of the experiences folder using the listFolderContentsOnRPi function. This function is defined at the end of this example.
dirContent = listFolderContentsOnRPi( ...
agentData.RPi,agentData.ExperiencesFolderRPi);Check for and remove all the old experience files from the RPi.
if ~isempty(dirContent) system(agentData.RPi,convertStringsToChars("rm -f " + ... agentData.ExperiencesFolderRPi + "*.*")); end
The deployed policy uses an exploratory policy to collect data.
agentData.UseExplorationPolicy = true;
Use the writePolicyParameters function to save the initial policy parameters to a file on the desktop computer and to send the parameters in the agentData structure to the Raspberry Pi. This function is defined at the end of this example.
writePolicyParameters(agentData);
Store the policy parameter structure to envData. This structure is used as a reference to convert the serialized data to a structure in the Get Policy Parameters subsystem mentioned earlier.
envData.ParametersStruct = policyParameters( ...
getExplorationPolicy(agentData.Agent));Use the slbuild (Simulink) command to build and deploy the model on the Raspberry Pi board.
Use the evalc function to capture the text output from code generation, for possible later inspection.
buildLog = evalc("slbuild(mdl)");The model is configured only to build and deploy. You can also specify the build directory.
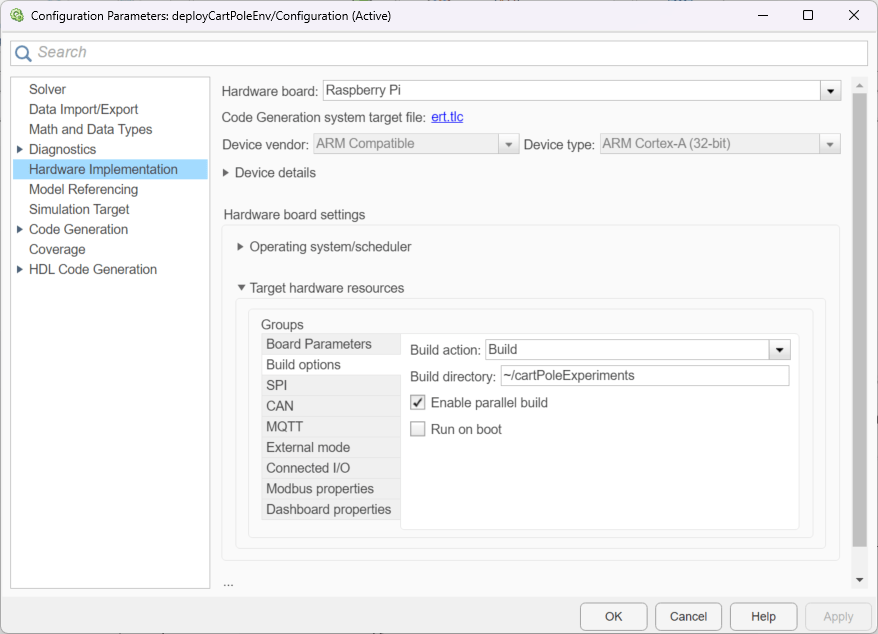
Start the model deployed to the Raspberry Pi Board.
runModel(agentData.RPi,mdl);
You can use isModelRunning to determine whether the model is running on the board. The isModelRunning method returns true if the model is running on the Raspberry Pi board.
isModelRunning(agentData.RPi,mdl)
ans = logical
1
Run Training Loop
The example executes the training loop, as a part of the learning process, on the desktop computer.
Create variables to monitor training.
trainingResultData.CumulativeRewardTemp = 0; trainingResultData.CumulativeReward = []; trainingResultData.AverageCumulativeReward = []; trainingResultData.AveragingWindowLength = 10; trainingResultData.NumOfEpisodes = 0;
Stop the training when the agent receives an average cumulative reward greater than 470 or a maximum of 5000 episodes.
rewardStopTrainingValue = 470; maxEpisodes = 5000;
To train the agent, set doTraining to true.
doTraining =  false;
false;Create a figure for training visualization using the buildRemoteTrainingMonitor helper function. This function is defined at the end of this example.
if doTraining [trainingPlot, ... trainingResultData.LineReward, ... trainingResultData.LineAverageReward] = ... buildRemoteTrainingMonitor(); % Enable the training visualization plot. set(trainingPlot,Visible="on"); end
The training repeats these steps:
Check for any new experiences from the deployed control process Simulink model. If new experiences exist, get them from the Raspberry Pi board to the desktop computer.
Read the experiences and append them to the replay buffer using the
readNewExperiencesfunction. This function is defined at the end of this example. After the experiences are read, they are deleted from the Raspberry Pi board.Train the agent from the collected data using the
trainFromDatafunction.Save the updated policy parameters to the Raspberry Pi board using the
writePolicyParametersfunction. This function is defined at the end of this example.
if doTraining while true % Look for any experience files. dirContent = listFolderContentsOnRPi( ... agentData.RPi,agentData.ExperiencesFolderRPi); if ~isempty(dirContent) % Display the newfound experience files. fprintf('%s %4d new experience files found\n', ... datetime('now'),numel(dirContent)); % Use the readNewExperiences function to read % new experience files and append experiences % to the replay buffer. [agentData, trainingResultData] = readNewExperiences( ... dirContent,agentData,trainingResultData); % Perform a learning step for the agent % using data in the experience buffer. offlineTrainStats = trainFromData( ... agentData.Agent,agentData.TrainFromDataOptions); % Save the updated actor parameters to a file on the % desktop computer and send the file to the Raspberry Pi. writePolicyParameters(agentData); end if ~isempty(trainingResultData.AverageCumulativeReward) % Check if at least one experience was read to prevent % AverageCumulativeReward reward from being empty. if trainingResultData.AverageCumulativeReward(end) > ... rewardStopTrainingValue ... || trainingResultData.NumOfEpisodes>=maxEpisodes % Use break to exit the training loop when % the average cumulative reward is greater than % rewardStopTrainingValue or the number of % episodes is more than maxEpisodes. break end end end else % If you did not train the agent, load the agent from a file. load("trainedAgentHardware.mat","agent"); agentData.Agent = agent; end
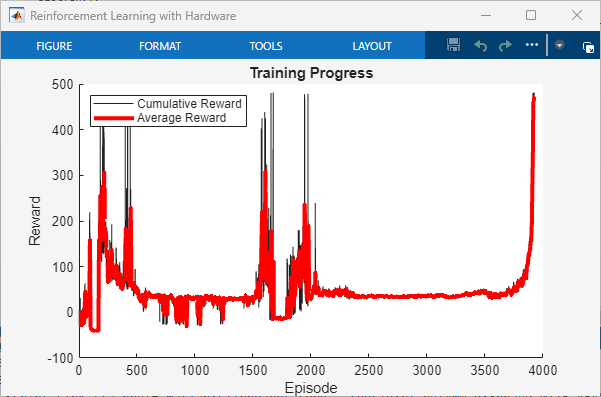
Stop the model deployed to the Raspberry Pi board.
if isModelRunning(agentData.RPi,mdl) stopModel(agentData.RPi,mdl); end
Simulate Trained Policy
Simulate the trained policy on the Raspberry Pi board using greedy actions. Change the policy to act greedily by setting the policy parameter Policy_UseMaxLikelihoodAction = true.
Send the policy parameters to the Raspberry Pi board.
writePolicyParameters(agentData);
Remove all the old experience files on the board.
system(agentData.RPi,convertStringsToChars("rm -f " + ... agentData.ExperiencesFolderRPi + "*.*"));
Create variables to monitor the simulation.
simulationResultData.CumulativeRewardTemp = 0; simulationResultData.CumulativeReward = []; simulationResultData.AverageCumulativeReward = []; simulationResultData.AveragingWindowLength = 10; simulationResultData.NumOfEpisodes = 0; simulationMaxEpisodes = 5;
Start the model deployed to the Raspberry Pi board.
if ~isModelRunning(agentData.RPi,mdl) runModel(agentData.RPi,mdl); end
The simulation repeats these steps:
Check for new experiences from the deployed control process. If new experiences exist, send them from the Raspberry Pi board to the desktop computer.
Read the experiences and append them to the replay buffer using the
readNewExperiencesfunction.
while true % Check for new experiences. dirContent = listFolderContentsOnRPi( ... agentData.RPi, agentData.ExperiencesFolderRPi); if ~isempty(dirContent) fprintf('%s %4d new experiences found\n', ... datetime('now'), numel(dirContent));
29-Jan-2025 16:14:40 1 new experiences found 29-Jan-2025 16:14:44 1 new experiences found 29-Jan-2025 16:14:49 1 new experiences found 29-Jan-2025 16:14:53 1 new experiences found 29-Jan-2025 16:14:57 1 new experiences found 29-Jan-2025 16:15:02 1 new experiences found 29-Jan-2025 16:15:06 1 new experiences found 29-Jan-2025 16:15:11 1 new experiences found 29-Jan-2025 16:15:15 1 new experiences found 29-Jan-2025 16:15:19 1 new experiences found 29-Jan-2025 16:15:24 1 new experiences found 29-Jan-2025 16:15:28 1 new experiences found 29-Jan-2025 16:15:33 1 new experiences found
% Read new experience files % and append experiences to the replay buffer. [agentData, simulationResultData] = readNewExperiences( ... dirContent,agentData,simulationResultData); end if simulationResultData.NumOfEpisodes>=simulationMaxEpisodes % Use break to exit the simulation loop when the number of % episodes is more than simulationMaxEpisodes. break end end
Compute the average of episode rewards. This value shows that the policy stabilizes the pole on the cart.
mean(simulationResultData.CumulativeReward)
Stop the model deployed to the Raspberry Pi board.
if isModelRunning(agentData.RPi,mdl)ans = 477.9915
stopModel(agentData.RPi,mdl);
endRestore the random number stream using the information stored in previousRngState.
rng(previousRngState);
Local Functions
Write Policy Parameters
The writePolicyParameters function extracts the policy parameters from the agent, writes them to a file, and sends the file to the Raspberry Pi board.
function writePolicyParameters(agentData) % Open file to save the policy parameters on the desktop computer. filepath = fullfile( ... agentData.ParametersFolderDesktop, agentData.ParametersFile); fid = fopen(filepath,'w+'); cln = onCleanup(@()fclose(fid)); if agentData.UseExplorationPolicy % Get exploration policy parameters. parameters = policyParameters( ... getExplorationPolicy(agentData.Agent)); else % Get greedy policy parameters. parameters = ... policyParameters(getGreedyPolicy(agentData.Agent)); end % Convert the policy parameters into a vector of uint8s % (serialization) and save it to a file. fwrite(fid,structToBytes(parameters),'uint8'); % Send the file from desktop to the Raspberry Pi board. putFile(agentData.RPi, ... convertStringsToChars(fullfile( ... agentData.ParametersFolderDesktop, ... agentData.ParametersFile)), ... convertStringsToChars( ... agentData.ParametersFolderRPi + ... agentData.ParametersFile)); end
Read New Experiences
The readNewExperiences function moves new experience files from the Raspberry Pi board to the desktop computer, reads the experiences, and appends the experiences to the replay buffer.
function [agentData, trainingResultData] = ... readNewExperiences(dirContent,agentData, trainingResultData) for ii=1:length(dirContent) % Move file from the Raspberry Pi board to the desktop computer. getFile(agentData.RPi, ... convertStringsToChars( ... agentData.ExperiencesFolderRPi+dirContent(ii)), ... convertStringsToChars(agentData.ExperiencesFolderDesktop)); % Remove the moved file from the Raspberry Pi board. system(agentData.RPi,convertStringsToChars("rm -f " + ... agentData.ExperiencesFolderRPi+dirContent(ii))); % Open the moved file on the desktop to read the data. fid = fopen(fullfile( ... agentData.ExperiencesFolderDesktop,dirContent(ii)),'r'); cln = onCleanup(@()fclose(fid)); % Read data from the file. experiencesBytes = fread(fid,'*uint8'); % Convert the uint8s to the experience structure. tempExperienceBuffer = bytesToStruct( ... experiencesBytes,agentData.TempExperienceBuffer); % Compute the cumulative reward and update the plots. trainingResultData = computeCumulativeReward( ... trainingResultData,tempExperienceBuffer); % Get the experiences ready to append to the replay buffer. for kk=size(tempExperienceBuffer.Observation,2):-1:1 experiences(kk).NextObservation = ... {tempExperienceBuffer.NextObservation(:,kk)}; experiences(kk).Observation = ... {tempExperienceBuffer.Observation(:,kk)}; experiences(kk).Action = ... {tempExperienceBuffer.Action(:,kk)}; experiences(kk).Reward = ... tempExperienceBuffer.Reward(kk); experiences(kk).IsDone = ... tempExperienceBuffer.IsDone(kk); end % Append the new experiences to the replay buffer. append(agentData.Agent.ExperienceBuffer,experiences); end end
Compute Cumulative Reward from Experiences
The computeCumulativeReward function computes the cumulative reward and updates the learning plot.
function trainingResultData = computeCumulativeReward( ... trainingResultData,tempExperienceBuffer) isDone = tempExperienceBuffer.IsDone; reward = tempExperienceBuffer.Reward; N = length(isDone); while N > 0 if any(isDone) % Check for isDones endOfEpIdx = find(isDone,1); trainingResultData.CumulativeRewardTemp = ... trainingResultData.CumulativeRewardTemp ... + sum(reward(1:endOfEpIdx)); % Append the new episode cumulative reward. trainingResultData.CumulativeReward = ... [trainingResultData.CumulativeReward; ... trainingResultData.CumulativeRewardTemp]; % Initialize temporary variable used to % compute the cumulative reward trainingResultData.CumulativeRewardTemp = 0; % Update the plots. trainingResultData.NumOfEpisodes = ... trainingResultData.NumOfEpisodes+1; trainingResultData.AverageCumulativeReward = ... movmean(trainingResultData.CumulativeReward, ... trainingResultData.AveragingWindowLength,1); % Update the monitor. if isfield(trainingResultData, "LineReward") && ... ~isempty(trainingResultData.LineReward) addpoints( ... trainingResultData.LineReward, ... trainingResultData.NumOfEpisodes, ... trainingResultData.CumulativeReward(end)); addpoints( ... trainingResultData.LineAverageReward, ... trainingResultData.NumOfEpisodes, ... trainingResultData.AverageCumulativeReward(end)); end drawnow; % Truncate the trajectory. isDone(1:endOfEpIdx) = []; reward(1:endOfEpIdx) = []; N = length(isDone); else % If no more isDone exist, compute the cumulative reward % and store it using the temporary variable. trainingResultData.CumulativeRewardTemp = ... trainingResultData.CumulativeRewardTemp ... + sum(reward(1:N)); N = 0; end end end
Create Figure for Training Visualization
The buildRemoteTrainingMonitor function creates a figure for training visualization.
function [trainingPlot, lineReward, lineAverageReward] = ... buildRemoteTrainingMonitor() plotRatio = 16/9; trainingPlot = figure( ... Visible="off", ... HandleVisibility="off", ... NumberTitle="off", ... Name="Reinforcement Learning with Hardware"); trainingPlot.Position(3) = ... plotRatio * trainingPlot.Position(4); ax = gca(trainingPlot); lineReward = animatedline(ax); lineAverageReward = animatedline(ax,Color="r",LineWidth=3); xlabel(ax,"Episode"); ylabel(ax,"Reward"); legend(ax,"Cumulative Reward","Average Reward", ... Location="northwest") title(ax,"Training Progress"); end
Assign Parameter Values Related to Environment
The environmentParameters function assigns several parameter values needed for the environment.
function envData = environmentParameters(sampleTime) % Initial condition of the pendulum envData.State0 = zeros(4,1); envData.G = 9.8; % m/s^2 envData.MCart = 1.0; % kg envData.HCart = 0.4; % m envData.WCart = 0.4; % m envData.MPole = 0.1; % kg envData.LPole = 0.5; % m envData.MaxForce = 10.0; % N envData.ThetaUpper = 0.05; % rad envData.ThetaLower = -0.05; % rad envData.XThreshold = 2.4; % m envData.ThetaThreshold = 12*pi/180; % rad envData.ActGain = 1.0; envData.RewardFall = -50; envData.RewardNoFall = 1; envData.MaxStepsPerSim = uint32(500); envData.Ts = sampleTime; % sec envData.ExperiencesWriteFrequency = 200; end
Create Folder on Raspberry Pi Board
The createFolderOnRPi function creates a folder on the Raspberry Pi board if not exists.
function createFolderOnRPi(RPi, FolderRPi) system(RPi,convertStringsToChars("if [ ! -d " + ... FolderRPi + " ]; then mkdir -p " + ... FolderRPi + "; fi")); end
List Contents of a Folder on a Raspberry Pi Board
The listFolderContentsOnRPi function lists contents of a folder on the Raspberry Pi board.
function dirContent = listFolderContentsOnRPi(RPi,experiencesFolderRPi) dirTemp = system(RPi,convertStringsToChars("ls " + ... experiencesFolderRPi)); dirContent = strsplit(dirTemp); dirContent(end) = []; end
See Also
Functions
Blocks
Objects
rlReplayMemory|rlStochasticActorPolicy|rlSACAgent|rlSACAgentOptions|rlTrainingFromDataOptions
Topics
- Generate Policy Block for Deployment
- Train Reinforcement Learning Policy Using Custom Training Loop
- Train Reinforcement Learning Agent Offline to Control Quanser QUBE Pendulum
- Control a Quanser QUBE Pendulum with a Raspberry Pi using Reinforcement Learning
- Train Reinforcement Learning Agents
- Examine Approaches to Fine Tune a Deployed Policy
- Create Custom Reinforcement Learning Agents
- Use Predefined Control System Environments