loss
Loss of ECOC incremental learning classification model on batch of data
Since R2022a
Description
loss returns the classification loss of a configured
multiclass error-correcting output codes (ECOC) classification model for incremental learning
(incrementalClassificationECOC object).
To measure model performance on a data stream and store the results in the output model,
call updateMetrics or
updateMetricsAndFit.
Examples
The performance of an incremental model on streaming data is measured in three ways:
Cumulative metrics measure the performance since the start of incremental learning.
Window metrics measure the performance on a specified window of observations. The metrics are updated every time the model processes the specified window.
The
lossfunction measures the performance on a specified batch of data only.
Load the human activity data set. Randomly shuffle the data.
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Create an ECOC classification model for incremental learning. Specify the class names and a metrics window size of 1000 observations. Configure the model for loss by fitting it to the first 10 observations.
Mdl = incrementalClassificationECOC(ClassNames=unique(Y),MetricsWindowSize=1000); initobs = 10; Mdl = fit(Mdl,X(1:initobs,:),Y(1:initobs));
Mdl is an incrementalClassificationECOC model. All its properties are read-only.
Simulate a data stream, and perform the following actions on each incoming chunk of 100 observations:
Call
updateMetricsto measure the cumulative performance and the performance within a window of observations. Overwrite the previous incremental model with a new one to track performance metrics.Call
lossto measure the model performance on the incoming chunk.Call
fitto fit the model to the incoming chunk. Overwrite the previous incremental model with a new one fitted to the incoming observations.Store all performance metrics to see how they evolve during incremental learning.
% Preallocation numObsPerChunk = 100; nchunk = floor((n - initobs)/numObsPerChunk); mc = array2table(zeros(nchunk,3),VariableNames=["Cumulative","Window","Chunk"]); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1 + initobs); iend = min(n,numObsPerChunk*j + initobs); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); mc{j,["Cumulative","Window"]} = Mdl.Metrics{"ClassificationError",:}; mc{j,"Chunk"} = loss(Mdl,X(idx,:),Y(idx)); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl is an incrementalClassificationECOC model object trained on all the data in the stream. During incremental learning and after the model is warmed up, updateMetrics checks the performance of the model on the incoming observations, and then the fit function fits the model to those observations. loss is agnostic of the metrics warm-up period, so it measures the classification error for every chunk.
To see how the performance metrics evolve during training, plot them.
plot(mc.Variables) xlim([0 nchunk]) ylabel("Classification Error") xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,"--") grid on legend(mc.Properties.VariableNames) xlabel("Iteration")
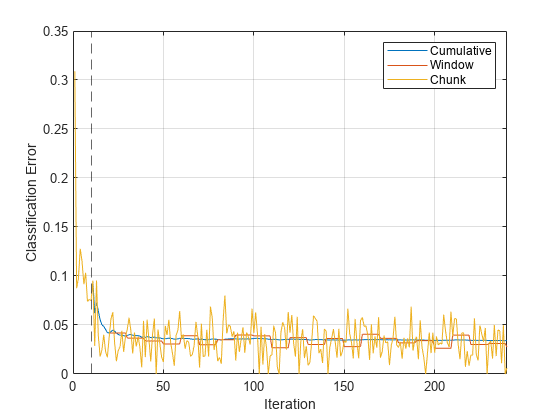
The yellow line represents the classification error on each incoming chunk of data. After the metrics warm-up period, Mdl tracks the cumulative and window metrics.
Fit an ECOC classification model for incremental learning to streaming data, and compute the minimum average binary loss on the incoming chunks of data.
Load the human activity data set. Randomly shuffle the data.
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Create an ECOC classification model for incremental learning. Configure the model as follows:
Specify the class names.
Specify a metrics warm-up period of 1000 observations.
Specify a metrics window size of 2000 observations.
Track the minimal average binary loss to measure the performance of the model. Create an anonymous function that measures the minimal average binary loss of each new observation. Create a structure array containing the name
MinimalLossand its corresponding function handle.Compute the classification loss by fitting the model to the first 10 observations.
tolerance = 1e-10; minimalBinaryLoss = @(~,S,~)min(-S,[],2); ce = struct("MinimalLoss",minimalBinaryLoss); Mdl = incrementalClassificationECOC(ClassNames=unique(Y), ... MetricsWarmupPeriod=1000,MetricsWindowSize=2000, ... Metrics=ce); initobs = 10; Mdl = fit(Mdl,X(1:initobs,:),Y(1:initobs));
Mdl is an incrementalClassificationECOC model object configured for incremental learning.
Perform incremental learning. At each iteration:
Simulate a data stream by processing a chunk of 100 observations.
Call
updateMetricsto compute cumulative and window metrics on the incoming chunk of data. Overwrite the previous incremental model with a new one fitted to overwrite the previous metrics.Call
lossto compute the minimum average binary loss on the incoming chunk of data. Whereas the cumulative and window metrics require that custom losses return the loss for each observation,lossrequires the loss for the entire chunk. Compute the mean of the losses within a chunk.Call
fitto fit the incremental model to the incoming chunk of data.Store the cumulative, window, and chunk metrics to see how they evolve during incremental learning.
% Preallocation numObsPerChunk = 100; nchunk = floor((n - initobs)/numObsPerChunk); tanloss = array2table(zeros(nchunk,3), ... VariableNames=["Cumulative","Window","Chunk"]); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1 + initobs); iend = min(n,numObsPerChunk*j + initobs); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); tanloss{j,1:2} = Mdl.Metrics{"MinimalLoss",:}; tanloss{j,3} = loss(Mdl,X(idx,:),Y(idx), ... LossFun=@(z,zfit,w)mean(minimalBinaryLoss(z,zfit,w))); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl is an incrementalClassificationECOC model object trained on all the data in the stream. During incremental learning and after the model is warmed up, updateMetrics checks the performance of the model on the incoming observations, and then the fit function fits the model to those observations.
Plot the performance metrics to see how they evolve during incremental learning.
semilogy(tanloss.Variables) xlim([0 nchunk]) ylabel("Minimal Average Binary Loss") xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,"-.") xlabel("Iteration") legend(tanloss.Properties.VariableNames)
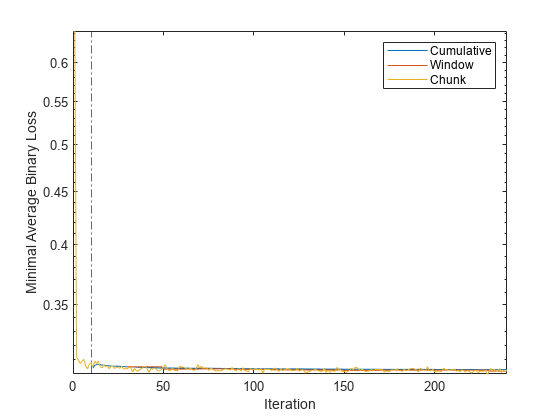
The plot suggests the following:
updateMetricscomputes the performance metrics after the metrics warm-up period only.updateMetricscomputes the cumulative metrics during each iteration.updateMetricscomputes the window metrics after processing 2000 observations (20 iterations).Because
Mdlis configured to predict observations from the beginning of incremental learning,losscan compute the minimum average binary loss on each incoming chunk of data.