Train Classification Models in Classification Learner App
You can use Classification Learner to train models of these classifiers: decision trees, discriminant analysis, support vector machines, logistic regression, nearest neighbors, naive Bayes, kernel approximation, ensembles, and neural networks. In addition to training models, you can explore your data, select features, specify validation schemes, and evaluate results. You can export a model to the workspace to use the model with new data or generate MATLAB® code to learn about programmatic classification.
When you train a classification model, the app performs two steps:
Train a full model — The app trains a model on the training data set. The training data set is the portion of the data that you do not set aside as a test data set when you start an app session.
Train validation models — The app trains one or more models using a validation scheme. By default, the app protects against overfitting by applying cross-validation. Alternatively, you can specify holdout validation. Both of these schemes train each validation model using a different subset of the training data set. The app computes the validation metrics and predictions of the final trained model by taking the average of the validation model metrics and predictions. For more information on validation schemes, see Select Validation Scheme in Classification Learner or Regression Learner.
Note
The app does not use the test data set to train the full model or the validation models. For more information on model testing, see Test Trained Models in Classification Learner or Regression Learner.
After you train a model, the app displays the averaged results of the validation models. Diagnostic measures, such as model accuracy, and plots, such as a scatter plot or confusion matrix chart, reflect the validation model results. You can automatically train one or more classifiers, compare validation results, and choose the best model that works for your classification problem. If you use a test data set, the app computes the test data set metrics using the full model (which is trained on the training data set).
When you choose a model to export to the workspace, Classification Learner exports the full model. Because Classification Learner creates a model object of the full model during training, you experience no lag time when you export the model. You can use the exported model to make predictions on new data.
To get started by training a selection of model types, see Automated Classifier Training. If you already know what classifier type you want to train, see Manual Classifier Training.
Automated Classifier Training
You can use Classification Learner to automatically train a selection of different classification models on your data.
Get started by automatically training multiple models at once. You can quickly try a selection of models, then explore promising models interactively.
If you already know what classifier type you want, train individual classifiers instead. See Manual Classifier Training.
On the Apps tab, in the Machine Learning and Deep Learning group, click Classification Learner to open the Classification Learner app.
On the Learn tab, in the File section, click New Session and select From Workspace Data or From Data File. Specify a response variable and variables to use as predictors. Alternatively, click Open to open a previously saved app session. See Start a Classification Learner or Regression Learner Session.
In the Models section, select All Quick-To-Train. This option trains all the model presets available for your data set that are fast to fit.

In the Train section, click Train All and select Train All.
Note
If you have Parallel Computing Toolbox™, the app trains the models in parallel by default. See Parallel Classifier Training.
A selection of model types appears in the Models pane. When the models finish training, the best percentage Accuracy (Validation) score is outlined in a box.

Click models in the Models pane and open the corresponding plots to explore the results.
For next steps, see Manual Classifier Training or Compare and Improve Classification Models.
To try all the nonoptimizable classifier model presets available for your data set, click All in the Models section of the Learn tab.

In the Train section, click Train All and select Train Selected.
Manual Classifier Training
To explore individual classifier types, you can train classifiers one at a time or as a group.
Choose a classifier. On the Learn tab, in the Models section, click a classifier type. To see all available classifier options, click the arrow on the far right of the Models section to expand the list of classifiers. The nonoptimizable model options in the Models gallery are preset starting points with different settings, suitable for a range of different classification problems.
To read a description of each classifier, switch to the details view.

For more information on each option, see Choose Classifier Options in Classification Learner.
After selecting a classifier, you can train the model. In the Train section, click Train All and select Train Selected. Repeat the process to try different classifiers.
Alternatively, you can create several draft models and then train the models as a group. In the Train section, click Train All and select Train All.
Tip
Try decision trees and discriminants first. If the models are not accurate enough predicting the response, try other classifiers with higher flexibility. To avoid overfitting, look for a model of lower flexibility that provides sufficient accuracy.
If you want to try all nonoptimizable models of the same or different types, then select one of the All options in the Models gallery.
Alternatively, if you want to automatically tune hyperparameters of a specific model type, select the corresponding Optimizable model and perform hyperparameter optimization. For more information, see Hyperparameter Optimization in Classification Learner App.
For next steps, see Compare and Improve Classification Models
Parallel Classifier Training
You can train models in parallel using Classification Learner if you have Parallel Computing Toolbox. Parallel training allows you to train multiple classifiers at once and continue working.
To control parallel training, toggle the Use Parallel button in the Train section of the Learn tab. To train draft models in parallel, ensure the button is toggled on before clicking Train All. The Use Parallel button is available only if you have Parallel Computing Toolbox.
The Use Parallel button is on by default. The first time you click Train All and select Train All or Train Selected, a dialog box is displayed while the app opens a parallel pool of workers. After the pool opens, you can train multiple classifiers at once.
When classifiers are training in parallel, progress indicators appear on each training and queued model in the Models pane. You can cancel individual models, if you want. During training, you can examine results and plots from models, and initiate training of more classifiers.
If you have Parallel Computing Toolbox, then parallel training is available for nonoptimizable models in
Classification Learner, and you do not need to set the
UseParallel option of the statset
function.
Note
If you do not have Parallel Computing Toolbox, you can still keep the app responsive during model training. Before training draft models, on the Learn tab, in the Train section, click Train All and ensure the Use Background Training check box is selected. Then, select the Train All option. A dialog box is displayed while the app opens a background pool. After the pool opens, you can continue to interact with the app while models train in the background.
Compare and Improve Classification Models
You can compare and improve trained classification models using several different features in the app.
Examine the Accuracy (Validation) score reported in the Models pane for each model. In the Plots and Results section of the Learn tab, click Compare Results. Select a metric to display from the X list under Plot Data.
Click models in the Models pane and open the corresponding plots to explore the results. Compare model performance by inspecting results in the plots. You can rearrange the layout of the plots to compare results across multiple models: use the options in the Layout button, drag plots, or select the options provided by the Document Actions button
 located to the right of the model plot tabs.
located to the right of the model plot tabs.Additionally, you can compare the models by using the Sort by list in the Models pane. Delete any unwanted model by selecting the model and clicking the Delete selected model button in the upper right of the pane or right-clicking the model and selecting Delete.
See Visualize and Assess Classifier Performance in Classification Learner.
Select the best model in the Models pane and then try including and excluding different features in the model.
First, create a copy of the best model by right-clicking the model and selecting Duplicate.
Then, click Feature Selection in the Options section of the Learn tab. Use the available feature ranking algorithms to select features.
Try the parallel coordinates plot to help you identify features to remove. See if you can improve the model by removing features with low predictive power. Specify predictors to include in the model, and train new models using the new options. Compare results among the models in the Models pane.
You can also try transforming features with PCA to reduce dimensionality. Click PCA in the Options section of the Learn tab.
See Feature Selection and Feature Transformation Using Classification Learner App.
To try to improve the model further, you can duplicate it, change the classifier hyperparameter options in the Model Hyperparameters section of the model Summary tab, and then train the model using the new options. To learn how to control model flexibility, see Choose Classifier Options in Classification Learner. For information on how to tune model hyperparameters automatically, see Hyperparameter Optimization in Classification Learner App.
If feature selection, PCA, or new hyperparameter values improve your model, try training All model types with the new settings. See if another model type does better with the new settings.
Tip
To avoid overfitting, look for a model of lower flexibility that provides sufficient accuracy. For example, look for simple models such as decision trees and discriminants that are fast and easy to interpret. If the models are not accurate enough predicting the response, choose other classifiers with higher flexibility, such as ensembles. To learn about the model flexibility, see Choose Classifier Options in Classification Learner.
This figure shows the app with a Models pane containing various classifier types.
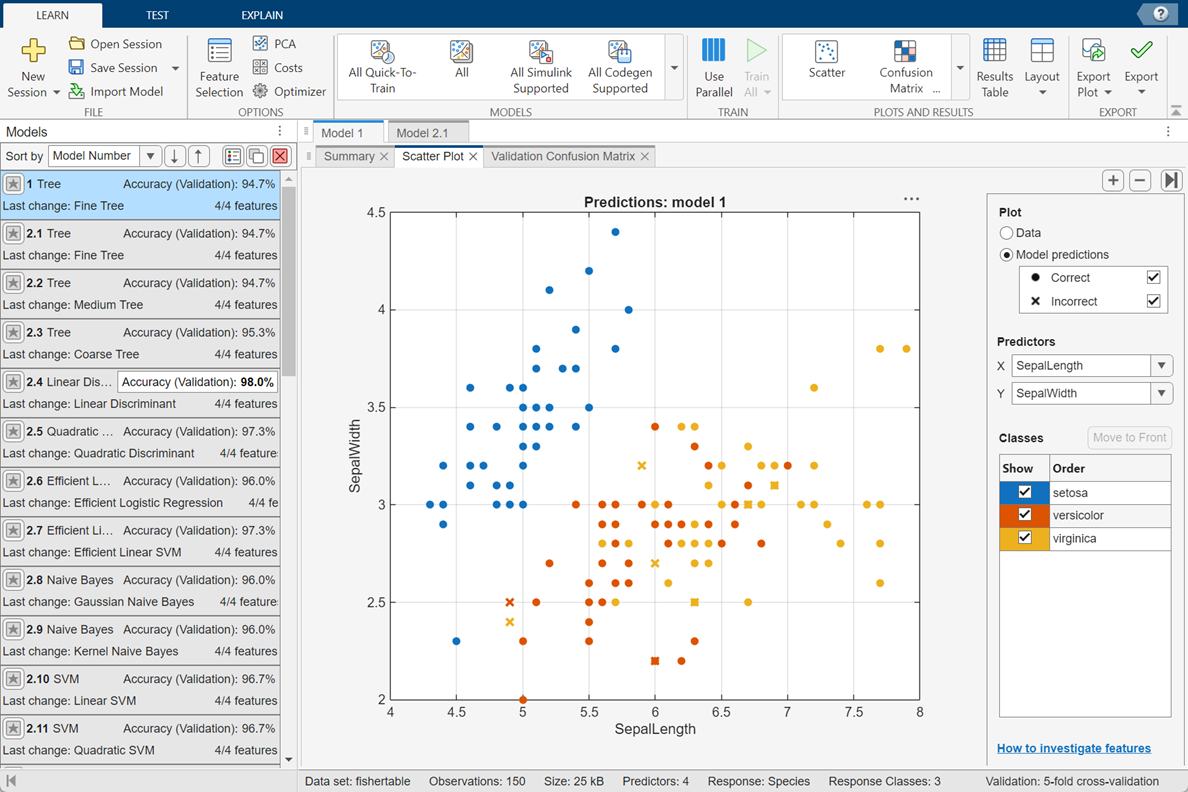
For a step-by-step example comparing different classifiers, see Train Decision Trees Using Classification Learner App.
For next steps, generate code to train the model with different data, or export trained models to the workspace to make predictions using new data. See Export Classification Model to Predict New Data.
See Also
Topics
- Start a Classification Learner or Regression Learner Session
- Choose Classifier Options in Classification Learner
- Feature Selection and Feature Transformation Using Classification Learner App
- Visualize and Assess Classifier Performance in Classification Learner
- Export Classification Model to Predict New Data
- Train Decision Trees Using Classification Learner App
- Machine Learning in MATLAB