Modeling and Simulation | Designing a Datapath from an FPGA to a Processor with SoC Blockset
From the series: Designing a Datapath from an FPGA to a Processor with SoC Blockset
This video is part of a series that demonstrates a systematic approach to designing the datapath between the hardware logic of an FPGA and an embedded processor using SoC Blockset™. Applications are often partitioned between hardware logic and an embedded processor on a system-on-chip (SoC) device to meet throughput, latency, and processing requirements.
Learn to design and simulate an entire application comprising FPGA and processor algorithms along with memory interfaces. You will see how to use blocks from SoC Blockset to model shared external memory, and how to use SoC Blockset to measure different forms of latency, and data loss from memory buffers.
By performing these analyses using simulation, you have better visibility into your design than when working with just hardware. You can uncover issues like loss of throughput, latency, and dropping of samples before implementing on hardware.
Published: 30 Jul 2019
In this video, we will show how SoC Blockset is used to model and simulate hardware effects when designing a data path from an FPGA to a processor.
By simulating hardware effects while developing an application, you can assess overall performance without all the additional effort of getting the application loaded on a development board. Also, with simulation you can have greater visibility into the application than is possible with a development board, so you can identify issues and test out potential solution more quickly.
Here’s the initial model of the application we are designing. It takes a stream of sinusoidal data from an external source, classifies it as either a low- or high-frequency signal, and illuminates the Low or High frequency detector light.
We will test it by using the toggle switch to choose low- and high-frequency signals. For the purposes of testing, we’ll generate the test signals in the FPGA. The FPGA filters the input stream, then passes the data to the buffer. This initial model uses a simple ideal buffer, which is good enough for checking the algorithm. The processor operates on a frame of data, detects the signal, and turns on the corresponding detector light.
We can see the model running. In simulation we can toggle between the low- and high-frequency test signal, and we see the detector LEDs light up. This simulation proves out the algorithm, but now we want to incorporate hardware effects of buffering in a DDR memory as we would configure it in hardware. SoC Blockset includes blocks and templates that help us.
Consider this diagram of our application. The test signal is sampled by the FPGA at a rate of 100 kHz. The processor operates on a frame of data every 10 milliseconds. Since data is transferred asynchronously from the FPGA to the processor, we insert a FIFO in FPGA memory as well as a DDR memory. The dotted lines shown here represent back-pressure. This occurs as the memory buffers fill up, potentially requiring more data to remain in the FPGA’s FIFO until buffers are flushed.
Here are two of the requirements the design must meet:
- The maximum allowed latency is 100 msec
- And we cannot drop any more than 1 in 10,000 samples
As we attempt to meet these requirements, we will focus on two parameters: frame size and the number of buffers.
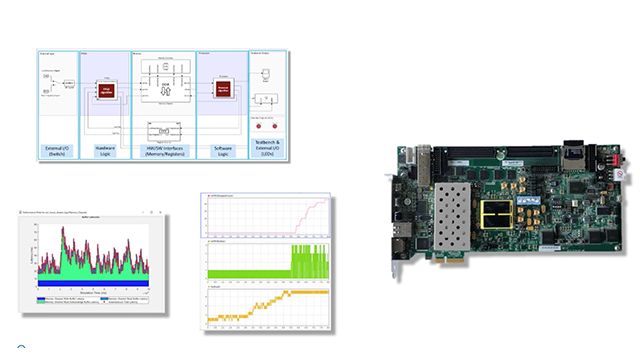
We use blocks from the SoC Blockset to model this design’s architecture more accurately.
- This Memory Channel block models data transfer through this DDR shared memory. In this model, the Memory Channel models implementation of the AXI4-Stream protocol from the FPGA to the processor via DMA.
- The Memory Controller block arbitrates and grants access to memory.
- The Register Channel models the communication from the processor back to the FPGA, and we see that FPGA block driving the LEDs through its output pins.
To start, we use a frame size of 800 samples, with each sample consuming 4 bytes. We also specify that the memory region will consist of 11 buffers. We set up the parameters of the memory channel block and run the simulation.
During the simulation we can toggle the input signal between the low- and high-frequency signals. We can view the dataout signal coming from the processor and see the frequency changing, and we can see the indicator light changing accordingly. We run the simulation for 100 seconds of time, and this model has been run to completion.
We open up the Memory Channel block, which is instrumented to measure latency frame by frame. As shown here, a few seconds into the simulation, latency reaches values in the range of 100 msec. The maximum allowable latency was 100 msec, so this design isn’t too far off of the latency requirement. Since we are close to the requirement, let’s proceed for the moment.
The other requirement was that no more than 1 sample in 10,000 could be dropped. With SoC Blockset, the model is instrumented so we can determine whether samples are being dropped. We can see from the top chart that buffer usage starts increasing around 3 seconds into the simulation, and increases up to around 5.5 seconds. The middle chart plots FIFO usage, and the bottom one plots the number of samples that have been dropped.
At around 5.8 seconds, the FIFO starts dropping samples steadily. By the end of 100 seconds, nearly 900 samples have been dropped, and we can see that for each 10-second period, about 100 samples are dropped. That’s pretty much right at the required limit of 1 in 10,000. Since this design isn’t meeting either of the specs very well, let’s try changing the memory configuration.
We will increase the frame size from 800 to 1,000 samples and reduce the number of buffers from 11 to 9. Then we re-run the simulation with the new parameters.
Once the simulation is complete, we can open up the Memory Channel block. In this case, latency reaches a peak around 23 seconds into the simulation, where it reaches latency of about 78 msec. Remember that the maximum allowable latency was 100 msec, so now we are pretty safely under that limit.
Then we check again to see whether we are within the requirement of dropping fewer than 1 in 10,000 samples. When we look at the same three variables, we can see that there are no samples being dropped whatsoever. This means we now have a design that has met our two requirements.
Now that we’ve used simulation with SoC Blockset to determine frame size and the number of buffers, we are ready to implement the design in hardware on an FPGA board where we can perform further testing with SoC Blockset to validate our simulation results.
To summarize, we used SoC Blockset to augment the model of an algorithm with hardware effects so we could use simulation to see how varying frame size and the number of buffers affected performance.
By simulating an algorithm with its hardware architecture, we were able to uncover issues like latency and dropping of samples before implementing on hardware.