Voice Activity Detection in Audio Toolbox
Voice activity detection (VAD) is a common building block in many audio systems. Distinguishing speech and non-speech segments enables more efficient processing and transmission of audio data. Applications of VAD include speech and speaker recognition systems, telecommunications, hearing aids, audio conferencing, surveillance and security, speech enhancement, and data set preprocessing for machine learning workflows.
In this example, you compare VAD implementations provided by Audio Toolbox™.
Overview
Audio Toolbox provides the following features:
voiceActivityDetector- Detect probability of speech in frames of streaming audiodetectSpeech- Detect boundaries of speech in audio signaldetectspeechnn- Detect boundaries of speech in audio signal using AI
Inspect Test File
Load a relatively clean speech file and corresponding speech detection mask. There is no gold standard labeling for speech detection since boundaries of speech are debatable, especially when considering space between words. The mask shown here gives generous boundaries to speech regions. You can use this mask as a reference for VAD performance.
[cleanspeech,fs] = audioread("vadexample-cleanspeech.ogg"); sound(cleanspeech,fs) load("vadexample-cleanspeech-mask.mat","vadmask") plotsigroi(vadmask,cleanspeech,true)

voiceActivityDetector
The voiceActivityDetector object creates a moving estimate of noise over time and then estimates the signal-to-noise ratio (SNR) for each input frame [1] [2] [3]. If the SNR is above a certain threshold, the region may correspond to speech. The SNR estimate is combined with a hidden Markov model (HMM) to determine the probability that the current frame contains speech. The final metric is returned as a number in the range [0,1]. It is up to the user to determine a threshold on the metric to determine whether speech is present.
The voiceActivityDetector is well-suited for streaming applications because it retains state between calls. It performs well for clean speech and under the condition that the background variability is static or slow-moving and is not peaky, such as the channel noise introduced in telecommunications.
fileReader = dsp.AudioFileReader("vadexample-noisyspeech.ogg"); vad = voiceActivityDetector(); scope = timescope( ... NumInputPorts=2, ... SampleRate=fileReader.SampleRate, ... TimeSpanSource="Property",TimeSpan=20, ... BufferLength=20*fileReader.SampleRate, ... YLimits=[-1 1.2], ... ShowLegend=true, ... ChannelNames=["Audio","Probability of speech presence"]); device = audiostreamer(SampleRate=fileReader.SampleRate); while ~isDone(fileReader) x = fileReader(); probability = vad(x); scope(x,probability*ones(fileReader.SamplesPerFrame,1)) drawnow limitrate play(device,x); end release(fileReader) release(vad) release(device) release(scope)
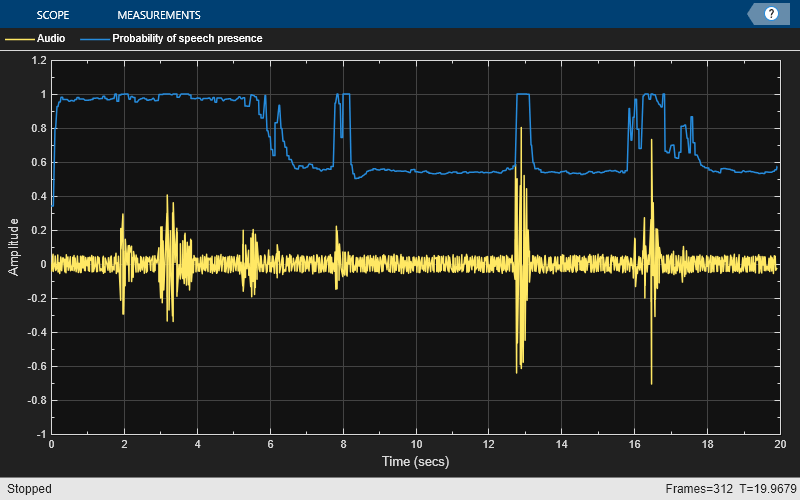
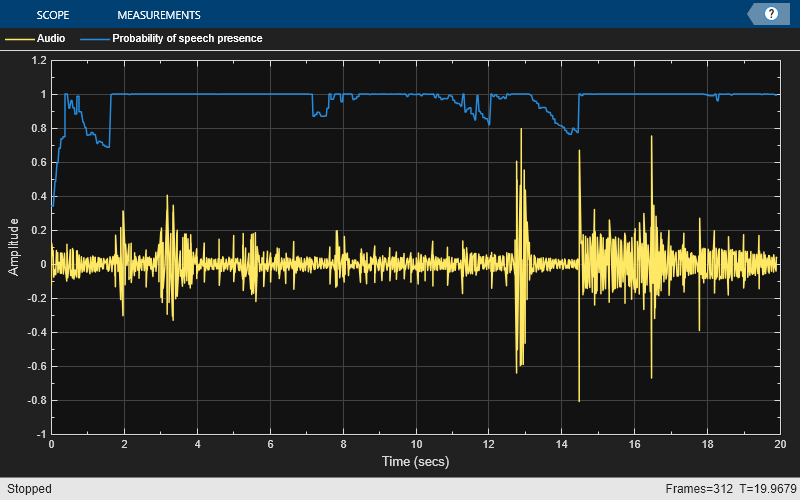
The algorithm has difficulty distinguishing speech from non-speech when the non-speech is particularly peaky, such as music or some real-world ambiance. For example, in the following file containing both speech and music, musical regions without speech are identified with high probability as being speech by the voiceActivityDetector.
fileReader = dsp.AudioFileReader("vadexample-speechplusmusic.ogg"); while ~isDone(fileReader) x = fileReader(); probability = vad(x); scope(x,probability*ones(fileReader.SamplesPerFrame,1)) drawnow limitrate play(device,x); end release(fileReader) release(vad) release(device) release(scope)
detectSpeech
The detectSpeech function works by extracting, creating statistical models, and then thresholding short-term features of the signal to create decision masks [4]. By default, it assumes that both speech and non-speech are present in a signal to determine the thresholds. You can specify the thresholds to the function directly for streaming applications or to save time when processing large data sets.
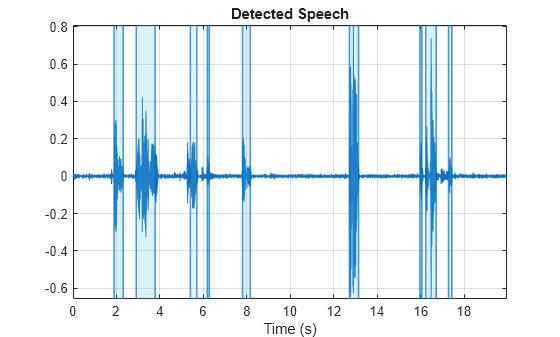
The detectSpeech function is well-suited to isolate relatively clean speech. It operates best on complete audio segments. It does not require a startup time to build a statistical noise estimate.
detectSpeech(cleanspeech,fs)
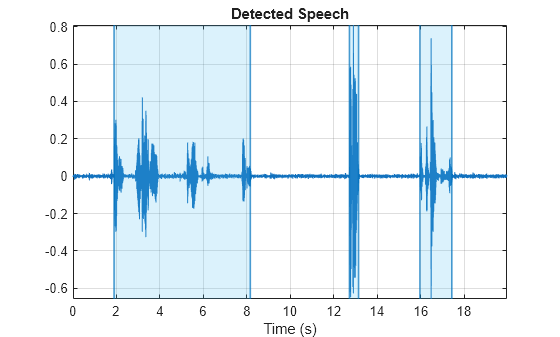
Because it operates in a batch-fashion, the detectSpeech function additionally offers the post-processing ability to merge speech decisions.
detectSpeech(cleanspeech,fs,MergeDistance=2*fs)
The detectSpeech algorithm has difficulty distinguishing speech from non-speech under low SNR or when the non-speech is particularly peaky, such as music or ambiance. The algorithm fails under both the low SNR and background music scenarios.
[noisyspeech,fs] = audioread("vadexample-noisyspeech.ogg");
detectSpeech(noisyspeech,fs)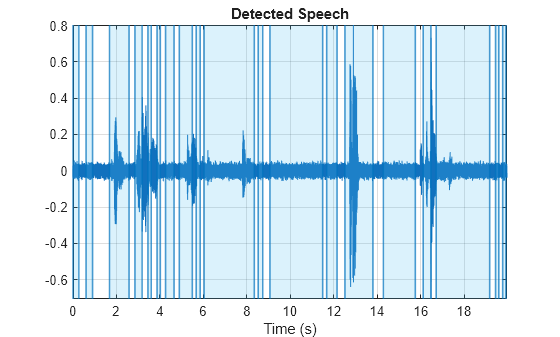
[speechplusmusic,fs] = audioread("vadexample-speechplusmusic.ogg");
detectSpeech(speechplusmusic,fs)
detectspeechnn
The detectspeechnn function leverages an AI model to detect the probability of speech, then performs postprocessing logic to smooth detected regions and optionally includes an energy-based VAD on the backend [5]. The model combines convolutional, recurrent, and fully-connected layers. It was trained on the LibriParty data set [6], which is a synthetic cocktail-party/meeting scenario dataset derived from LibriSpeech [7].
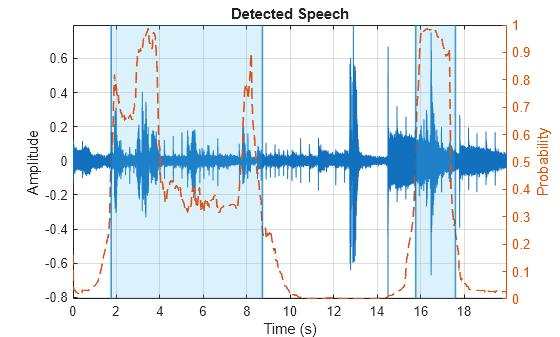
The detectspeechnn function is well-suited to detect continuous speech under difficult noise conditions. It performs well in both the low SNR and music scenarios. It is also the only algorithm that disregards the throat clearing around the 13 second mark.
detectspeechnn(noisyspeech,fs)

detectspeechnn(speechplusmusic,fs)
As a byproduct of the training data, the model performs poorly in detecting very small speech segments, like isolated words. In the following audio file, a female voice says "volume up" several time. The algorithm does not detect the last utterance.
[x,fs] = audioread("FemaleVolumeUp-16-mono-11secs.ogg");
detectspeechnn(x,fs)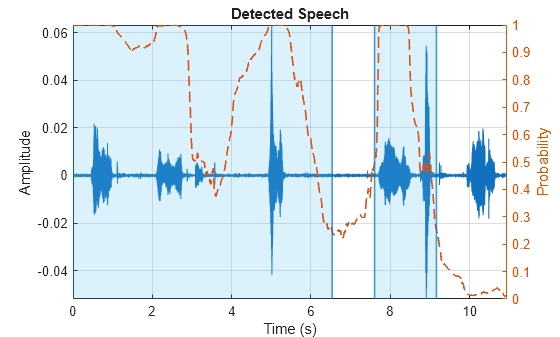
You can access the model underlying detectspeechnn directly and perform transfer learning for specific noise conditions, language or voice conditions, or to detect isolated words. See Train Voice Activity Detection in Noise Model Using Deep Learning for an example.
Comparison
Use the table to determine which feature is suitable for your application.
Use for ... | Data Processing | Speed | Noise Robustness | Simulink® Support | GPU Arrays | C/C++ Code Generation | |
Detection of continuous speech or speech segments in clean and non-tonal noisy environments. | frame-based | slowest (operates on frames independently) | medium | Voice Activity Detector block | no | yes | |
Detection of continuous speech or speech segments in clean or low-level noise environments. | batch to use in streaming, buffering is required | fastest | low | Use in MATLAB Function (Simulink) block | yes | yes | |
Detection of continuous speech in clean or noisy environments. | batch to use in streaming, buffering is required | moderate | high | Use in MATLAB Function (Simulink) block | yes | yes |
References
Sohn, Jongseo., Nam Soo Kim, and Wonyong Sung. "A Statistical Model-Based Voice Activity Detection." Signal Processing Letters IEEE. Vol. 6, No. 1, 1999.
Martin, R. "Noise Power Spectral Density Estimation Based on Optimal Smoothing and Minimum Statistics." IEEE Transactions on Speech and Audio Processing. Vol. 9, No. 5, 2001, pp. 504–512.
Ephraim, Y., and D. Malah. "Speech Enhancement Using a Minimum Mean-Square Error Short-Time Spectral Amplitude Estimator." IEEE Transactions on Acoustics, Speech, and Signal Processing. Vol. 32, No. 6, 1984, pp. 1109–1121.
Giannakopoulos, Theodoros. "A Method for Silence Removal and Segmentation of Speech Signals, Implemented in MATLAB", (University of Athens, Athens, 2009).
Ravanelli, Mirco, et al. SpeechBrain: A General-Purpose Speech Toolkit. arXiv, 8 June 2021. arXiv.org, https://arxiv.org/abs/2106.04624
Speechbrain. "Speechbrain/Recipes/Libriparty/Generate_dataset at Develop · Speechbrain/Speechbrain." GitHub. Accessed November 21, 2024. https://github.com/speechbrain/speechbrain/tree/develop/recipes/LibriParty/generate_dataset.
Panayotov, Vassil, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. "Librispeech: An ASR Corpus Based on Public Domain Audio Books." In