Sfoltimento, proiezione e quantizzazione
Utilizzare Deep Learning Toolbox™ insieme al pacchetto di supporto Deep Learning Toolbox Model Compression Library per ridurre l’ingombro della memoria e i requisiti di calcolo di una rete neurale profonda tramite:
Sfoltire i filtri dai livelli convoluzionali utilizzando l'approssimazione di Taylor del primo ordine.
Proiettare i livelli eseguendo un'analisi dei componenti principali (PCA) sulle attivazioni del livello.
Quantizzare i pesi, i bias e le attivazioni dei livelli in tipi di dato interi scalati a precisione ridotta.
È quindi possibile generare codice dalla rete compressa per la distribuzione sull'hardware desiderato.
Link in evidenza
Categorie
- Come iniziare con la compressione della rete
Imparare le nozioni di base di Deep Learning Toolbox Model Compression Library
- Sfoltimento
Ridurre il numero di parametri apprendibili in una rete neurale tramite lo sfoltimento dei filtri meno importanti nei livelli convoluzionali
- Proiezione
Proiettare i livelli della rete utilizzando l'analisi dei componenti principali (PCA); ridurre il numero di parametri apprendibili
- Quantizzazione
Quantizzare i parametri della rete in tipi di dato a precisione ridotta; preparare la rete di Deep Learning per la generazione di codice in virgola fissa
- Applicazioni di compressione della rete
Scopri la compressione dei modelli di Deep Learning nei workflow end-to-end
Esempi in primo piano

Analyze and Compress 1-D Convolutional Neural Network
Analyze 1-D convolutional network for compression and compress it using Taylor pruning and projection.
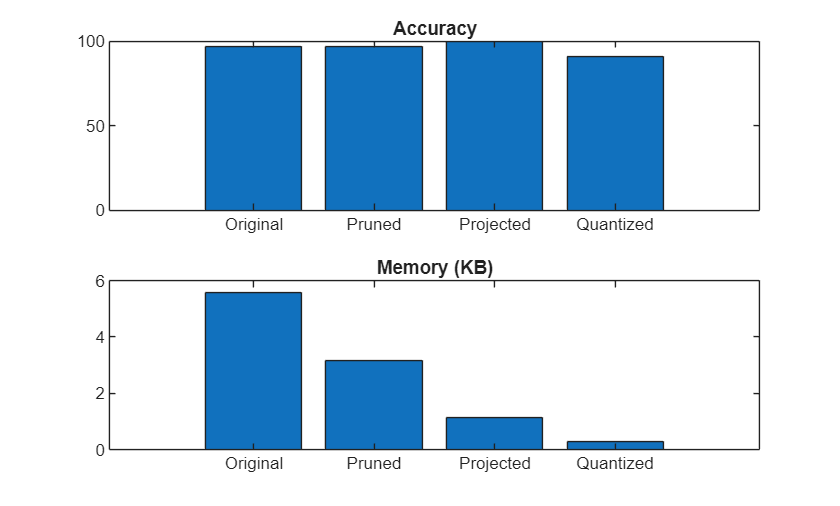
Compress Sequence Classification Network for Road Damage Detection
Compress network to meet memory requirement using pruning, projection, and quantization.
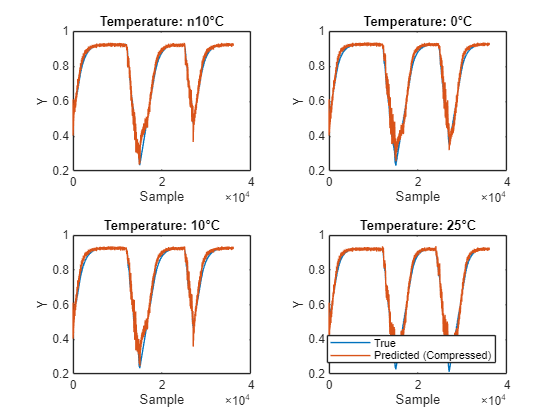
Compress Deep Learning Network for Battery State of Charge Estimation
Compress a neural network for predicting the state of charge of a battery using projection.