Reti neurali con memoria a breve e lungo termine
Questo argomento spiega come lavorare con dati sequenziali e delle serie temporali per le attività di classificazione e regressione, utilizzando reti neurali con memoria a breve e lungo termine (LSTM). Per un esempio che mostra come classificare i dati sequenziali utilizzando una rete neurale LSTM, vedere Classificazione di sequenze utilizzando il Deep Learning.
Una rete neurale LSTM è un tipo di rete neurale ricorrente (RNN) in grado di apprendere le dipendenze a lungo termine tra le fasi temporali dei dati sequenziali.
Architettura della rete neurale LSTM
I componenti di base di una rete neurale LSTM sono un livello di input di sequenza e un livello LSTM. Un livello di input di sequenza immette nella rete neurale dati sequenziali o delle serie temporali. Un livello LSTM apprende le dipendenze a lungo termine tra le fasi temporali dei dati sequenziali.
Questo diagramma illustra l'architettura di una rete neurale LSTM semplice per la classificazione. La rete neurale inizia con un livello di input di sequenza seguito da un livello LSTM. Per prevedere le etichette delle classi, la rete neurale termina con un livello completamente connesso e un livello softmax.

Questo diagramma illustra l'architettura di una rete neurale LSTM semplice per la regressione. La rete neurale inizia con un livello di input di sequenza seguito da un livello LSTM. La rete neurale termina con un livello completamente connesso.

Reti LSTM per la classificazione
Per creare una rete LSTM per la classificazione da sequenza a etichetta, creare un array di livelli contenente un livello di input di sequenza, un livello LSTM, un livello completamente connesso e un livello softmax.
Impostare la grandezza del livello di input di sequenza sul numero di feature dei dati di input. Impostare la grandezza del livello completamente connesso sul numero di classi. Non è necessario specificare la lunghezza della sequenza.
Per il livello LSTM, specificare il numero di unità nascoste e la modalità di output "last".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer];
Per un esempio che mostra come addestrare una rete LSTM per la classificazione da sequenza a etichetta e come classificare nuovi dati, vedere Classificazione di sequenze utilizzando il Deep Learning.
Per creare una rete LSTM per la classificazione da sequenza a sequenza, utilizzare la stessa architettura della classificazione da sequenza a etichetta, ma impostare la modalità di output del livello LSTM su "sequence".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
Reti LSTM per la regressione
Per creare una rete LSTM per la regressione da sequenza a singolo, creare un array di livelli contenente un livello di input di sequenza, un livello LSTM e un livello completamente connesso.
Impostare la grandezza del livello di input di sequenza sul numero di feature dei dati di input. Impostare la grandezza del livello completamente connesso sul numero di risposte. Non è necessario specificare la lunghezza della sequenza.
Quando si addestra la rete neurale, è possibile normalizzare automaticamente i target di addestramento utilizzando l'opzione di addestramento NormalizeTargets (introdotta nella release R2026a). Utilizzare target normalizzati contribuisce a stabilizzare l'addestramento e porta a previsioni di addestramento che corrispondono strettamente ai target normalizzati. Affinché la rete neurale generi previsioni nello spazio dei valori non normalizzati solo al momento della previsione, includere un livello di normalizzazione inversa (introdotto nella release R2026a). Prima della release R2026a: per stabilizzare l'addestramento, normalizzare manualmente i target prima di addestrare la rete neurale.
Per il livello LSTM, specificare il numero di unità nascoste e la modalità di output "last".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
Per creare una rete LSTM per la regressione da sequenza a sequenza, utilizzare la stessa architettura della regressione da sequenza a singolo, ma impostare la modalità di output del livello LSTM su "sequence".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
Per un esempio che mostra come addestrare una rete LSTM per la regressione da sequenza a sequenza e come fare previsioni su nuovi dati, vedere Sequence-to-Sequence Regression Using Deep Learning.
Rete di classificazione video
Per creare una rete di Deep Learning per dati contenenti sequenze di immagini, come dati video e immagini mediche, specificare l'input di sequenza delle immagini utilizzando il livello di input di sequenza.
Specificare i livelli e creare un oggetto dlnetwork.
inputSize = [64 64 3];
filterSize = 5;
numFilters = 20;
numHiddenUnits = 200;
numClasses = 10;
layers = [
sequenceInputLayer(inputSize)
convolution2dLayer(filterSize,numFilters)
batchNormalizationLayer
reluLayer
lstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer];
net = dlnetwork(layers);Per un esempio che mostra come addestrare una rete di Deep Learning per la classificazione dei video, vedere Classify Videos Using Deep Learning.
Reti LSTM più profonde
È possibile rendere le reti LSTM più profonde inserendo, prima del livello LSTM, livelli LSTM aggiuntivi con la modalità di output "sequence". Per evitare l'overfitting, è possibile inserire livelli di dropout dopo i livelli LSTM.
Per le reti di classificazione da sequenza a etichetta, la modalità di output dell'ultimo livello LSTM deve essere "last".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="last") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
Per le reti di classificazione da sequenza a sequenza, la modalità di output dell'ultimo livello LSTM deve essere "sequence".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="sequence") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
Livelli
| Icona | Livello | Descrizione |
|---|---|---|
| Un livello di input di sequenza immette dati sequenziali in una rete neurale e applica la normalizzazione dei dati. | |
| Un livello di incorporazione converte gli indici numerici in vettori numerici, dove gli indici corrispondono a dati discreti. | |
| Un livello LSTM è un livello RNN che apprende le dipendenze a lungo termine tra le fasi temporali dei dati delle serie temporali e dei dati sequenziali. | ||
| Un livello LSTM proiettato è un livello RNN che apprende le dipendenze a lungo termine tra le fasi temporali dei dati delle serie temporali e dei dati sequenziali utilizzando pesi apprendibili proiettati. | ||
| Un livello LSTM bidirezionale (BiLSTM) è un livello RNN che apprende le dipendenze bidirezionali a lungo termine tra le fasi temporali dei dati delle serie temporali o dei dati sequenziali. Queste dipendenze possono essere utili quando si desidera che la RNN apprenda dalle serie temporali complete a ciascun passo temporale. | ||
| Un livello GRU è un livello RNN che apprende le dipendenze tra le fasi temporali dei dati delle serie temporali e dei dati sequenziali. | ||
| Un livello GRU proiettato è un livello RNN che apprende le dipendenze tra le fasi temporali dei dati delle serie temporali e dei dati sequenziali utilizzando pesi apprendibili proiettati. | ||
| Un livello convoluzionale monodimensionale applica filtri convoluzionali a scorrimento a un input monodimensionale. | ||
| Un livello convoluzionale monodimensionale trasposto esegue l'upsampling delle mappe di feature monodimensionali. | ||
| Un livello di pooling massimo monodimensionale effettua il sottocampionamento dividendo l'input in regioni di pooling monodimensionali e calcolando il massimo di ciascuna regione. | ||
| Un livello di pooling medio monodimensionale esegue il sottocampionamento dividendo l'input in regioni di pooling monodimensionali, calcolando poi la media di ciascuna regione. | ||
| Un livello di pooling massimo globale monodimensionale effettua il sottocampionamento producendo il massimo delle dimensioni temporali o spaziali dell'input. | ||
| Un livello di appiattimento comprime le dimensioni spaziali dell'input nella dimensione del canale. | ||
| Un livello di incorporazione delle parole mappa gli indici delle parole ai vettori. | |
| Un livello LSTM peephole è una variante di un livello LSTM in cui i calcoli della porta utilizzano lo stato della cella del livello. |

Classificazione, previsione e analisi previsionale
Per fare previsioni su nuovi dati, utilizzare la funzione minibatchpredict. Per convertire i punteggi di classificazione previsti in etichette, utilizzare scores2label.
Le reti neurali LSTM possono ricordare lo stato della rete neurale tra le previsioni. Lo stato RNN è utile quando non si dispone della serie temporale completa in anticipo o se si desidera effettuare più previsioni su una serie temporale lunga.
Per prevedere e classificare parti di una serie temporale e aggiornare lo stato della RNN, utilizzare la funzione predict e, inoltre, restituire e aggiornare lo stato della rete neurale. Per reimpostare lo stato della RNN tra le previsioni, utilizzare resetState.
Per un esempio che mostra come effettuare un'analisi previsionale delle fasi temporali future di una sequenza, vedere Previsione delle serie temporali tramite il Deep Learning.
Riempimento e troncamento delle sequenze
Le reti neurali LSTM supportano dati di input con sequenze di lunghezza variabile. Quando i dati passano attraverso la rete neurale, il software riempie o tronca le sequenze in modo che tutte le sequenze di ogni mini-batch abbiano la lunghezza specificata. È possibile specificare le lunghezze delle sequenze e il valore utilizzato per riempire le sequenze utilizzando le opzioni di addestramento SequenceLength e SequencePaddingValue.
Dopo l'addestramento della rete neurale, è possibile utilizzare la stessa grandezza del mini-batch e le stesse opzioni di riempimento che si utilizzano con la funzione minibatchpredict.
Ordinamento delle sequenze per lunghezza
Per ridurre la quantità di dati di riempimento o di scarto quando si riempiono o si troncano le sequenze, provare a ordinare i dati in base alla lunghezza della sequenza. Per le sequenze in cui la prima dimensione corrisponde ai passi temporali, per ordinare i dati in base alla lunghezza della sequenza, ricavare innanzitutto il numero di colonne di ogni sequenza applicando size(X,1) a ogni sequenza utilizzando cellfun. Quindi ordinare le lunghezze delle sequenze utilizzando sort e utilizzare il secondo output per riordinare le sequenze originali.
sequenceLengths = cellfun(@(X) size(X,1), XTrain); [sequenceLengthsSorted,idx] = sort(sequenceLengths); XTrain = XTrain(idx);

Riempimento delle sequenze
Se l'opzione di addestramento o di previsione SequenceLength è "longest", il software riempie le sequenze in modo che tutte le sequenze di un mini-batch abbiano la stessa lunghezza della sequenza più lunga del mini-batch stesso. Questa opzione è l'impostazione predefinita.

Troncamento delle sequenze
Se l'opzione di addestramento o di previsione SequenceLength è "shortest", il software tronca le sequenze in modo che tutte le sequenze di un mini-batch abbiano la stessa lunghezza della sequenza più corta di quel mini-batch. I dati rimanenti nelle sequenze vengono scartati.

Specifica della direzione di riempimento
La posizione del riempimento e del troncamento può avere un impatto sull'addestramento, sulla classificazione e sulla precisione della previsione. Provare a impostare le opzioni di addestramento SequencePaddingDirection su "left" o "right" per verificare quale sia la posizione migliore per i dati.
I livelli ricorrenti elaborano i dati sequenziali una fase temporale alla volta, quindi quando la proprietà OutputMode del livello ricorrente è "last", qualsiasi riempimento nelle fasi temporali finali può influire negativamente sull'output del livello. Per riempire o troncare i dati sequenziali a sinistra, impostare l'argomento nome-valore SequencePaddingDirection su "left".
Per le reti neurali sequenza-sequenza (quando la proprietà OutputMode è "sequence" per ogni livello ricorrente), qualsiasi riempimento nelle fasi temporali iniziali può influire negativamente sulle previsioni per le fasi temporali precedenti. Per riempire o troncare i dati sequenziali a destra, impostare l'argomento nome-valore SequencePaddingDirection su "right".


Normalizzazione dei dati sequenziali
Per ricentrare automaticamente i dati di addestramento al momento dell'addestramento utilizzando la normalizzazione a centro zero, impostare l'opzione Normalization di sequenceInputLayer su "zerocenter". In alternativa, è possibile normalizzare i dati sequenziali calcolando prima la media e la deviazione standard per feature di tutte le sequenze. Quindi, per ogni osservazione di addestramento, sottrarre il valore medio e dividerlo per la deviazione standard.
mu = mean([XTrain{:}],1);
sigma = std([XTrain{:}],0,1);
XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,UniformOutput=false);Dati non allocabili in memoria
Utilizzare i datastore per i dati sequenziali, di serie temporali e di segnale quando i dati sono troppo grandi per adattarsi alla memoria o per eseguire operazioni specifiche durante la lettura di batch di dati.
Per saperne di più, vedere Train Network Using Out-of-Memory Sequence Data e Classify Out-of-Memory Text Data Using Deep Learning.
Visualizzazione
Esaminare e visualizzare le feature apprese dalle reti neurali LSTM da dati sequenziali e serie temporali, estraendo le attivazioni utilizzando la funzione minibatchpredict e impostando l'argomento Outputs. Per saperne di più, vedere Visualizzazione delle attivazioni della rete LSTM.
Architettura del livello LSTM
Questo diagramma illustra il flusso di dati attraverso un livello LSTM con input e output , con T fasi temporali. Nel diagramma, indica l'output (noto anche come stato nascosto) e indica lo stato della cella nella fase temporale t.
Se il livello produce l'intera sequenza, produce quindi , …, che è equivalente a , …, . Se il livello produce solo l'ultima fase temporale, il livello produce quindi che è equivalente a . Il numero di canali in output corrisponde al numero di unità nascoste del livello LSTM.
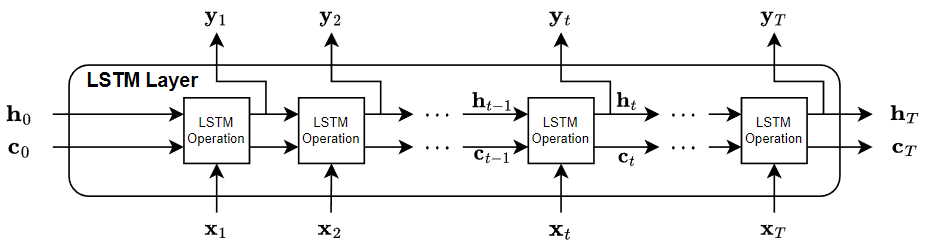
La prima operazione LSTM utilizza lo stato iniziale della RNN e la prima fase temporale della sequenza per calcolare il primo output e lo stato aggiornato della cella. Nella fase temporale t, l'operazione utilizza lo stato corrente della RNN e la fase temporale successiva della sequenza per calcolare l'output e lo stato aggiornato della cella .
Lo stato del livello è costituito dallo stato nascosto (noto anche come stato di output) e dallo stato della cella. Lo stato nascosto nella fase temporale t contiene l'output del livello LSTM per questa fase temporale. Lo stato della cella contiene le informazioni apprese nelle fasi temporali precedenti. A ciascuna fase temporale, il livello aggiunge o rimuove informazioni dallo stato della cella. Il livello controlla questi aggiornamenti utilizzando le porte.
Questi componenti controllano lo stato della cella e lo stato nascosto del livello.
| Componente | Scopo |
|---|---|
| Porta di input (i) | Controllare l'aggiornamento dello stato della cella |
| Porta di dimenticanza (f) | Controllare il livello di ripristino dello stato della cella (dimenticanza) |
| Candidato della cella (g) | Aggiungere informazioni allo stato della cella |
| Porta di output (o) | Controllare il livello dello stato della cella aggiunto allo stato nascosto |
Questo diagramma illustra il flusso di dati nella fase temporale t. Questo diagramma mostra come le porte dimenticano, aggiornano e producono gli stati della cella e gli stati nascosti.

I pesi apprendibili di un livello LSTM sono i pesi di input W (InputWeights), i pesi ricorrenti R (RecurrentWeights) e il bias b (Bias). Le matrici W, R e b sono rispettivamente le concatenazioni dei pesi di input, dei pesi ricorrenti e del bias di ogni componente. Il livello concatena le matrici in base a queste equazioni:
dove i, f, g e o indicano rispettivamente la porta di input, la porta di dimenticanza, il candidato della cella e la porta di output.
Lo stato della cella nella fase temporale t è dato da
, dove indica il prodotto di Hadamard (moltiplicazione di vettori elemento per elemento).
Lo stato nascosto nella fase temporale t è dato da
, dove indica la funzione di attivazione dello stato. Per impostazione predefinita, la funzione lstmLayer utilizza la funzione tangente iperbolica (tanh) per calcolare la funzione di attivazione dello stato.
Queste formule descrivono i componenti nella fase temporale t.
| Componente | Formula |
|---|---|
| Porta di input | |
| Porta di dimenticanza | |
| Candidato della cella | |
| Porta di output |
In questi calcoli, indica la funzione di attivazione della porta. Per impostazione predefinita, la funzione lstmLayer utilizza la funzione sigmoidale data da , per calcolare la funzione di attivazione della porta.
Riferimenti
[1] Hochreiter, S., and J. Schmidhuber. "Long short-term memory." Neural computation. Vol. 9, Number 8, 1997, pp.1735–1780.
Vedi anche
sequenceInputLayer | lstmLayer | bilstmLayer | gruLayer | dlnetwork | minibatchpredict | predict | scores2label | flattenLayer | wordEmbeddingLayer (Text Analytics Toolbox)
Argomenti
- Classificazione di sequenze utilizzando il Deep Learning
- Previsione delle serie temporali tramite il Deep Learning
- Classificazione sequenza-sequenza utilizzando il Deep Learning
- Sequence-to-Sequence Regression Using Deep Learning
- Sequence-to-One Regression Using Deep Learning
- Classify Videos Using Deep Learning
- Visualizzazione delle attivazioni della rete LSTM
- Develop Custom Mini-Batch Datastore
- Example Deep Learning Network Architectures
- Deep Learning in MATLAB