trainingOptions
Opzioni per l’addestramento della rete neurale di Deep Learning
Descrizione
options = trainingOptions(solverName)solverName. Per addestrare una rete neurale, utilizzare le opzioni di addestramento come un argomento di input nella funzione trainnet.
options = trainingOptions(solverName,Name=Value)
Esempi
Creare un set di opzioni per l’addestramento di una rete usando la discesa stocastica del gradiente con momento. Ridurre la velocità di apprendimento di un fattore di 0,2 ogni 5 epoche. Impostare il numero massimo di epoche per l’addestramento su 20 e utilizzare un mini-batch con 64 osservazioni a ogni iterazione. Attivare il grafico dei progressi dell’addestramento.
options = trainingOptions("sgdm", ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.2, ... LearnRateDropPeriod=5, ... MaxEpochs=20, ... MiniBatchSize=64, ... Plots="training-progress")
options =
TrainingOptionsSGDM with properties:
Momentum: 0.9000
MaxEpochs: 20
InitialLearnRate: 0.0100
LearnRateSchedule: 'piecewise'
LearnRateDropFactor: 0.2000
LearnRateDropPeriod: 5
MiniBatchSize: 64
Shuffle: 'once'
CheckpointFrequencyUnit: 'epoch'
PreprocessingEnvironment: 'serial'
Verbose: 1
VerboseFrequency: 50
ValidationData: []
ValidationFrequency: 50
ValidationPatience: Inf
Metrics: []
ObjectiveMetricName: 'loss'
ExecutionEnvironment: 'auto'
Plots: 'training-progress'
OutputFcn: []
SequenceLength: 'longest'
SequencePaddingValue: 0
SequencePaddingDirection: 'right'
InputDataFormats: "auto"
TargetDataFormats: "auto"
ResetInputNormalization: 1
ResetInverseNormalization: 1
NormalizeTargets: 0
BatchNormalizationStatistics: 'auto'
OutputNetwork: 'auto'
Acceleration: "auto"
CheckpointPath: ''
CheckpointFrequency: 1
CategoricalInputEncoding: 'integer'
CategoricalTargetEncoding: 'auto'
L2Regularization: 1.0000e-04
GradientThresholdMethod: 'l2norm'
GradientThreshold: Inf
Questo esempio mostra come monitorare i progressi dell'addestramento delle reti di Deep Learning.
Quando si addestrano le reti per il Deep Learning, il plottaggio di varie metriche durante l'addestramento consente di comprendere come progredisce l'addestramento stesso. Ad esempio, è possibile determinare se e quanto velocemente la precisione della rete stia migliorando e se la rete stia iniziando a sovradimensionare i dati di addestramento.
Questo esempio mostra come monitorare i progressi dell’addestramento delle reti addestrate utilizzando la funzione trainnet. Se si sta addestrando una rete utilizzando un loop di addestramento personalizzato, utilizzare invece un oggetto trainingProgressMonitor per tracciare le metriche durante l'addestramento. Per ulteriori informazioni, vedere Monitor Custom Training Loop Progress.
Quando si imposta l'opzione di addestramento Plots su "training-progress" in trainingOptions e si avvia l'addestramento della rete, la funzione trainnet crea una figura e visualizza le metriche di addestramento a ciascuna iterazione. Ogni iterazione è una stima del gradiente e un aggiornamento dei parametri della rete. Se si specificano i dati di convalida in trainingOptions, la figura mostrerà le metriche di convalida ogni volta che trainnet convalida la rete. La figura traccia la perdita e qualsiasi metrica specificata dall'opzione nome-valore Metrics. Per impostazione predefinita, il software utilizza una scala lineare per i grafici. Per specificare una scala logaritmica per l'asse y, selezionare il pulsante scala log nella barra degli strumenti degli assi.

Durante l'addestramento è possibile interromperlo e ripristinare lo stato attuale della rete facendo clic sul pulsante di stop, situato nell'angolo in alto a destra. Dopo aver fatto clic sul pulsante di stop, l'addestramento può richiedere un certo tempo per essere completato. Al termine dell'addestramento, trainnet restituisce la rete addestrata.
Specificare l'opzione di addestramento OutputNetwork come "best-validation" per ottenere valori finalizzati che corrispondano all'iterazione con il miglior valore della metrica di convalida, dove la metrica ottimizzata è specificata dalle opzioni di addestramento ObjectiveMetricName. Specificare l'opzione di addestramento OutputNetwork come "last-iteration" per ottenere metriche finalizzate che corrispondano all'ultima iterazione di addestramento.
Le informazioni relative al tempo di addestramento e alle impostazioni possono essere visualizzate a destra del pannello. Per saperne di più sulle opzioni di addestramento, vedere Set Up Parameters and Train Convolutional Neural Network.
Per salvare il grafico sui progressi dell'addestramento, fare clic su Export as Image (Esporta come immagine) nella finestra di addestramento. È possibile salvare il grafico come file PNG, JPEG, TIFF o PDF. È inoltre possibile salvare i singoli grafici utilizzando la barra degli strumenti degli assi.
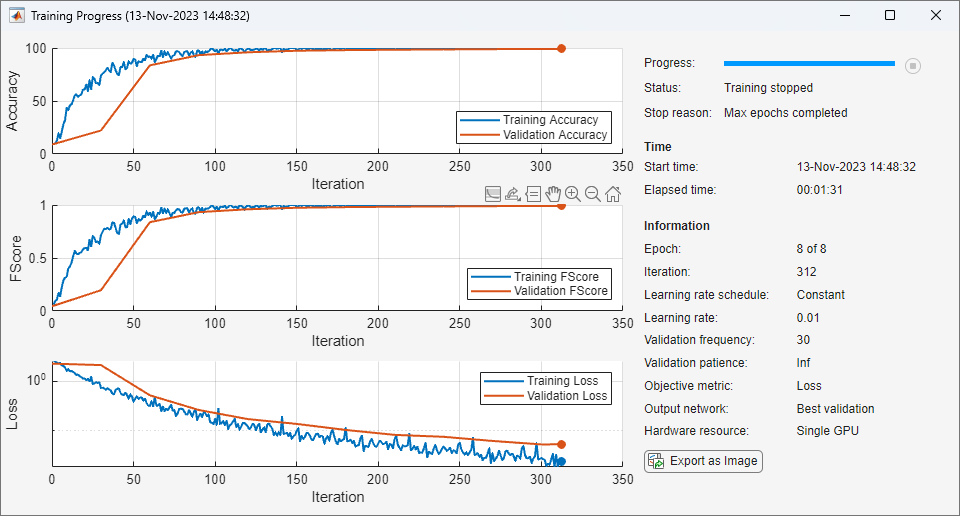
Tracciamento dei progressi dell’addestramento durante l’addestramento
Addestrare una rete e tracciare i progressi dell'addestramento durante l’addestramento.
Caricare i dati di addestramento e di test rispettivamente dai file MAT DigitsDataTrain.mat e DigitsDataTest.mat. Gli insiemi di dati di addestramento e di test contengono ciascuno 5000 immagini.
load DigitsDataTrain.mat load DigitsDataTest.mat
Creare un oggetto dlnetwork.
net = dlnetwork;
Specificare i livelli del ramo di classificazione e aggiungerli alla rete.
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,8,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,Stride=2)
convolution2dLayer(3,16,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,Stride=2)
convolution2dLayer(3,32,Padding="same")
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];
net = addLayers(net,layers);Specificare le opzioni per l'addestramento della rete. Specificare i dati di convalida per convalidare la rete a intervalli regolari durante l’addestramento. Registrare i valori della metrica per la precisione e l'F-score. Per tracciare i progressi dell'addestramento durante l’addestramento, impostare l'opzione di addestramento Plots su "training-progress".
options = trainingOptions("sgdm", ... MaxEpochs=8, ... Metrics = ["accuracy","fscore"], ... ValidationData={XTest,labelsTest}, ... ValidationFrequency=30, ... Verbose=false, ... Plots="training-progress");
Addestrare la rete.
net = trainnet(XTrain,labelsTrain,net,"crossentropy",options);
Utilizzare le metriche per l'arresto anticipato e per la restituzione della rete migliore.
Caricare i dati di addestramento, che contengono 5000 immagini di cifre. Mettere da parte 1000 immagini per la convalida della rete.
[XTrain,YTrain] = digitTrain4DArrayData; idx = randperm(size(XTrain,4),1000); XValidation = XTrain(:,:,:,idx); XTrain(:,:,:,idx) = []; YValidation = YTrain(idx); YTrain(idx) = [];
Costruire una rete per classificare i dati delle immagini di cifre.
net = dlnetwork;
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,8,Padding="same")
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];
net = addLayers(net,layers);Specificare le opzioni di addestramento:
Utilizzare un solver SGDM per l'addestramento.
Monitorare la performance dell'addestramento specificando i dati di convalida e la frequenza di convalida.
Tracciare la precisione e richiamare durante l'addestramento. Per ripristinare la rete con il miglior valore di richiamo, specificare
"recall"come metrica dell'obiettivo e impostare la rete di output su"best-validation".Specificare l'attesa di convalida come 5, in modo che l'addestramento si arresti se il richiamo non è diminuito per cinque iterazioni.
Visualizzare il grafico dei progressi dell'addestramento della rete.
Sopprimere l'output verboso.
options = trainingOptions("sgdm", ... ValidationData={XValidation,YValidation}, ... ValidationFrequency=35, ... ValidationPatience=5, ... Metrics=["accuracy","recall"], ... ObjectiveMetricName="recall", ... OutputNetwork="best-validation", ... Plots="training-progress", ... Verbose=false);
Addestrare la rete.
net = trainnet(XTrain,YTrain,net,"crossentropy",options);
Argomenti di input
Argomenti nome-valore
Specificare coppie opzionali di argomenti come Name1=Value1,...,NameN=ValueN, dove Name è il nome dell’argomento e Value è il valore corrispondente. Gli argomenti nome-valore devono comparire dopo gli altri argomenti, ma l'ordine delle coppie non ha importanza.
Prima della release R2021a, utilizzare le virgole per separare ciascun nome e valore e racchiudere Name tra virgolette.
Esempio Plots="training-progress",Metrics="accuracy",Verbose=false specifica di disabilitare l'output verboso e di visualizzare i progressi dell'addestramento in un grafico che includa inoltre la metrica di precisione.
Monitoraggio
Grafici da visualizzare durante l'addestramento della rete neurale, specificati come uno di questi valori:
"none": nessuna visualizzazione dei grafici durante l’addestramento."training-progress": grafico dei progressi dell’addestramento.
Il contenuto del grafico dipende dal solver utilizzato.
Quando l'argomento
solverNameè"sgdm","adam"o"rmsprop", il grafico mostra la perdita del mini-batch, la perdita di convalida, le metriche del mini-batch di addestramento e di convalida, specificate dall'opzioneMetrics, nonché ulteriori informazioni sui progressi dell'addestramento.Quando l'argomento
solverNameè"lbfgs"o"lm", il grafico mostra la perdita di addestramento e di validazione, le metriche di addestramento e di validazione, specificate dall'opzioneMetrics, nonché ulteriori informazioni sui progressi dell'addestramento.
Per aprire e chiudere il grafico sui progressi dell'addestramento in modo programmatico, utilizzare le funzioni show e close con il secondo output della funzione trainnet. È possibile utilizzare la funzione show per visualizzare i progressi dell'addestramento anche se l'opzione di addestramento Plots è specificata come "none".
Per commutare la scala dell'asse y in logaritmica, utilizzare la barra degli strumenti degli assi. 
Per ulteriori informazioni sul grafico, vedere Monitoraggio dei progressi dell’addestramento in Deep Learning.
Da R2023b
Metriche da monitorare, specificate come uno di questi valori:
Nome della metrica integrata o della funzione di perdita: specifica delle metriche come scalare di stringa, vettore di carattere, array di celle o array di stringhe, di uno o più di questi nomi:
Metriche:
"accuracy": accuratezza (nota anche come accuratezza top-1)"auc": area sotto la curva ROC (AUC)"fscore": F-score (noto anche come F1-score)"precision": precisione"recall": richiamo"rmse": errore quadratico medio"mape": errore medio assoluto percentuale (MAPE) (da R2024b)"rsquared": R2 (R al quadrato o coefficiente di determinazione) (da R2025a)
Funzioni di perdita:
"crossentropy": perdita di entropia incrociata per le attività di classificazione (da R2024b)"indexcrossentropy": perdita di entropia incrociata basata sugli indici per le attività di classificazione (da R2024b)"binary-crossentropy": perdita di entropia incrociata binaria per le attività di classificazione binaria e a etichetta multipla (da R2024b)"mae"/"mean-absolute-error"/"l1loss": errore assoluto medio per le attività di regressione (da R2024b)"mse"/"mean-squared-error"/"l2loss": errore quadratico medio per le attività di regressione (da R2024b)"huber": perdita di Huber per le attività di regressione (da R2024b)
L'impostazione della funzione di perdita come
"crossentropy"e la specifica di"index-crossentropy"come metrica o l'impostazione della funzione di perdita come"index-crossentropy"e la specifica di"crossentropy"come metrica non è supportata.Per ulteriori informazioni sulle metriche e sulle funzioni di perdita nel Deep Learning, vedere Deep Learning Metrics.
Oggetti metrici integrati: se è necessaria una maggiore flessibilità, è possibile utilizzare gli oggetti metrici integrati. Il software supporta questi oggetti metrici integrati:
MAPEMetric(da R2024b)RSquaredMetric(da R2025a)
Quando si crea un oggetto metrica integrato, è possibile specificare ulteriori opzioni, come il tipo di media e se l'attività è a etichetta singola o multipla.
Handle della funzione metrica personalizzata: se la metrica necessaria non è una metrica integrata, è possibile specificare delle metriche personalizzate utilizzando l'handle delle funzioni. La funzione deve presentare la sintassi
metric = metricFunction(Y,T), doveYcorrisponde alle previsioni della rete eTcorrisponde alle risposte target. Per le reti con più output, la sintassi deve esseremetric = metricFunction(Y1,...,YN,T1,...,TM), doveNè il numero di output eMè il numero di target. Per ulteriori informazioni, vedere Define Custom Metric Function.Nota
Quando si dispone di dati suddivisi in mini-batch, il software calcola la metrica per ciascun mini-batch e restituisce la media di tali valori. Per alcune metriche, questo comportamento può portare a un valore di metrica diverso rispetto a quello che si otterrebbe calcolando la metrica utilizzando l'intero set di dati in una sola volta. Nella maggior parte dei casi, i valori sono comunque simili. Per utilizzare una metrica personalizzata non mediata dal batch per i dati, è necessario creare un oggetto metrica personalizzato. Per ulteriori informazioni, vedere Define Custom Deep Learning Metric Object.
Oggetto
deep.DifferentiableFunction(da R2024a): oggetto funzione con funzione di retropropagazione personalizzata. Per i target categorici, il software converte automaticamente i valori categorici in vettori codificati one-hot e li passa alla funzione metrica. Per ulteriori informazioni, vedere Define Custom Deep Learning Operations.Oggetto metrica personalizzato: se è necessaria una maggiore personalizzazione, è possibile definire un oggetto metrica personalizzato. Per un esempio che mostra come creare una metrica personalizzata, vedere Define Custom Metric Object. Per informazioni generali sulla creazione di metriche personalizzate, vedere Define Custom Deep Learning Metric Object.
Se si specifica una metrica come handle della funzione, oggetto deep.DifferentiableFunction o oggetto metrica personalizzato e si addestra la rete neurale utilizzando la funzione trainnet, il layout dei target che il software passa alla metrica dipende dal tipo di dato dei target. La funzione di perdita specificata nella funzione trainnet e le altre metriche specificate hanno i seguenti effetti sul software:
Se i target sono array numerici, il software passa direttamente i target alla metrica.
Se la funzione di perdita è
"index-crossentropy"e i target sono array categorici, il software li converte automaticamente in indici di classe numerici e li passa alla metrica.Per le altre funzioni di perdita, se i target sono array categorici, il software li converte automaticamente in vettori codificati one-hot e li passa alla metrica.
Questa opzione supporta solo le funzioni trainnet e trainBERTDocumentClassifier (Text Analytics Toolbox).
Esempio Metrics=["accuracy","fscore"]
Esempio Metrics={"accuracy",@myFunction,precisionObj}
Da R2024a
Nome della metrica dell'obiettivo da utilizzare per l'arresto anticipato e la restituzione della rete migliore, specificata come scalare di stringa o vettore di carattere.
Il nome della metrica deve essere "loss" o deve corrispondere al nome di una metrica specificata dall'argomento Metrics. Le metriche specificate utilizzando gli handle delle funzioni non sono supportate. Per specificare il valore ObjectiveMetricName come nome di una metrica personalizzata, il valore della proprietà Maximize dell'oggetto metrica personalizzato non deve essere vuoto. Per ulteriori informazioni, vedere Define Custom Deep Learning Metric Object.
Per ulteriori informazioni sulla definizione della metrica dell'obiettivo per l'arresto anticipato, vedere ValidationPatience. Per ulteriori informazioni sulla restituzione della rete migliore utilizzando la metrica dell'obiettivo, vedere OutputNetwork.
Tipi di dati: char | string
Contrassegno per visualizzare le informazioni sui progressi dell'addestramento nella finestra di comando, specificato come 1 (true) o 0 (false).
Il contenuto dell'output verboso dipende dal tipo di solver.
Per i solver stocastici (SGDM, Adam e RMSProp), la tabella contiene queste variabili:
| Variabile | Descrizione |
|---|---|
Iteration | Numero di iterazioni. |
Epoch | Numero di epoche. |
TimeElapsed | Tempo trascorso in ore, minuti e secondi. |
LearnRate | Velocità di apprendimento. |
TrainingLoss | Perdita di addestramento. |
ValidationLoss | Perdita di convalida. Se non si specificano i dati di convalida, il software non visualizza questa informazione. |
Per i solver batch (L-BFGS e LM), la tabella contiene queste variabili:
| Variabile | Descrizione |
|---|---|
Iteration | Numero di iterazioni |
TimeElapsed | Tempo trascorso in ore, minuti e secondi |
TrainingLoss | Perdita di addestramento |
ValidationLoss | Perdita di convalida. Se non si specificano i dati di convalida, il software non visualizza questa informazione. |
GradientNorm | Norma dei gradienti |
StepNorm | Norma delle fasi |
Se si specificano ulteriori metriche nelle opzioni di addestramento, le stesse sono inoltre visualizzate nell'output verboso. Ad esempio, se si imposta l'opzione di addestramento Metrics su "accuracy", le informazioni includono le variabili TrainingAccuracy e ValidationAccuracy.
Quando l’apprendimento si arresta, l’output verboso visualizza il motivo dell’arresto.
Per specificare i dati di convalida, utilizzare l’opzione di addestramento ValidationData.
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | logical
Frequenza di stampa del verboso, ossia il numero di iterazioni tra le stampe nella finestra di comando, specificato come numero intero positivo.
Se si valida la rete neurale durante l'addestramento, il software stampa anche nella finestra di comando ogni volta che avviene una validazione.
Per abilitare questa proprietà, impostare l'opzione di addestramento Verbose su 1 (true).
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Funzioni di output da chiamare durante l'addestramento, specificate come handle della funzione o array di celle degli handle delle funzioni. Il software chiama le funzioni una volta prima dell'inizio dell'addestramento, dopo ciascuna iterazione e una volta al termine dell'addestramento.
Le funzioni devono presentare la sintassi stopFlag = f(info), dove info è una struttura contenente informazioni sui progressi dell'addestramento e stopFlag è uno scalare che indica l'arresto anticipato dell'addestramento. Se stopFlag è 1 (true), il software arresta l'addestramento. In caso contrario, il software continua l'addestramento.
La funzione trainnet trasferisce la struttura info alla funzione di output.
Per i solver stocastici (SGDM, Adam e RMSProp), info contiene questi campi:
| Campo | Descrizione |
|---|---|
Epoch | Numero di epoche |
Iteration | Numero di iterazioni |
TimeElapsed | Tempo trascorso dall'inizio dell'addestramento |
LearnRate | Velocità di apprendimento dell'iterazione |
TrainingLoss | Perdita di addestramento dell'iterazione |
ValidationLoss | Perdita di convalida, se specificata e valutata all'iterazione. |
State | Stato di addestramento dell'iterazione, specificato come "start", "iteration" o "done". |
Per i solver batch (L-BFGS e LM), info contiene questi campi:
| Campo | Descrizione |
|---|---|
Iteration | Numero di iterazioni |
TimeElapsed | Tempo trascorso in ore, minuti e secondi |
TrainingLoss | Perdita di addestramento |
ValidationLoss | Perdita di convalida. Se non si specificano i dati di convalida, il software non visualizza questa informazione. |
GradientNorm | Norma dei gradienti |
StepNorm | Norma delle fasi |
State | Stato di addestramento dell'iterazione, specificato come "start", "iteration" o "done" |
Se si specificano ulteriori metriche nelle opzioni di addestramento, le stesse sono inoltre visualizzate nelle informazioni sull'addestramento. Ad esempio, se si imposta l'opzione di addestramento Metrics su "accuracy", le informazioni includono i campi TrainingAccuracy e ValidationAccuracy.
Se un campo non viene calcolato o non è pertinente per una certa chiamata delle funzioni di output, tale campo contiene un array vuoto.
Per un esempio di utilizzo delle funzioni di output, vedere Custom Stopping Criteria for Deep Learning Training.
Tipi di dati: function_handle | cell
Layout dei dati
Opzioni del solver stocastico
Numero massimo di epoche (passaggi completi dei dati) da utilizzare per l'addestramento, specificato come numero intero positivo.
Questa opzione supporta solo i solver stocastici (quando l'argomento solverName è "sgdm", "adam" o "rmsprop").
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Dimensione del mini-batch da utilizzare per ogni iterazione di addestramento, specificata come un numero intero positivo. Un mini-batch è un sottoinsieme del set di addestramento, utilizzato per valutare il gradiente della funzione di perdita e per aggiornare i pesi.
Se la dimensione del mini-batch non suddivide in modo uniforme il numero di campioni di addestramento, il software scarta i dati di addestramento che non si adattano al mini-batch finale completo di ciascuna epoca. Se la dimensione del mini-batch è inferiore al numero di campioni di addestramento, il software non scarta alcun dato.
Questa opzione supporta solo i solver stocastici (quando l'argomento solverName è "sgdm", "adam" o "rmsprop").
Suggerimento
Per ottenere prestazioni ottimali, se si sta addestrando una rete utilizzando un datastore con una proprietà ReadSize, ad esempio imageDatastore, impostare la proprietà ReadSize e l'opzione di addestramento MiniBatchSize sullo stesso valore. Se si sta addestrando una rete utilizzando un datastore con una proprietà MiniBatchSize, ad esempio augmentedImageDatastore, impostare la proprietà MiniBatchSize del datastore e l'opzione di addestramento MiniBatchSize sullo stesso valore.
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Opzione per il mescolamento dei dati, specificata come uno di questi valori:
"once": mescolamento dei dati di addestramento e di convalida una volta prima dell’addestramento."never": nessun mescolamento dei dati."every-epoch": mescolamento dei dati di addestramento prima di ogni epoca di addestramento e mescolamento dei dati di convalida prima di ogni convalida della rete neurale. Se la dimensione del mini-batch non suddivide in modo uniforme il numero di campioni di addestramento, il software scarta i dati di addestramento che non si adattano al mini-batch finale completo di ciascuna epoca. Per evitare di scartare gli stessi dati per ogni epoca, impostare l’opzione di addestramentoShufflesu"every-epoch".
Questa opzione supporta solo i solver stocastici (quando l'argomento solverName è "sgdm", "adam" o "rmsprop").
Velocità di apprendimento iniziale usata per l’addestramento, specificata come uno scalare positivo.
Se la velocità di apprendimento è troppo bassa, l’addestramento può richiedere più tempo. Se la velocità di apprendimento è troppo alta, l’addestramento potrebbe raggiungere un risultato non ottimale o deviare.
Questa opzione supporta solo i solver stocastici (quando l'argomento solverName è "sgdm", "adam" o "rmsprop").
Quando solverName è "sgdm", il valore predefinito è 0.01. Quando solverName è "rmsprop" o "adam", il valore predefinito è 0.001.
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Programma della velocità di apprendimento, specificato come vettore di caratteri o scalare di stringa di un nome di programma della velocità di apprendimento integrato, array di stringhe di nomi, oggetto integrato o personalizzato programma della velocità di apprendimento, handle della funzione o array di celle di nomi, oggetti metrici e handle delle funzioni.
Questa opzione supporta solo i solver stocastici (quando l'argomento solverName è "sgdm", "adam" o "rmsprop").
Nomi del programma della velocità di apprendimento integrato
Specificare i programmi della velocità di apprendimento come scalare di stringa, vettore di carattere o array di stringhe o celle contenente uno o più di questi nomi:
| Nome | Descrizione | Grafico |
|---|---|---|
"none" | Nessun programma della velocità di apprendimento. Questo programma mantiene la velocità di apprendimento costante. |
|
"piecewise" | Programma di velocità di apprendimento a tratti. Ogni 10 epoche, questo programma riduce la velocità di apprendimento di un fattore di 10. |
|
"warmup" (da R2024b) | Programma della velocità di apprendimento con avvio graduale. Per 5 iterazioni, questo programma aumenta la velocità di apprendimento fino alla velocità di base. |
|
"polynomial" (da R2024b) | Programma della velocità di apprendimento polinomiale. Ogni epoca, questo programma riduce la velocità di apprendimento utilizzando una legge esponenziale con un esponente unitario. |
|
"exponential" (da R2024b) | Programma della velocità di apprendimento esponenziale. Ad ogni epoca, questo programma fa decadere la velocità di apprendimento di un fattore di 10. |
|
"cosine" (da R2024b) | Programma della velocità di apprendimento basato sul coseno. Ogni epoca, questo programma riduce la velocità di apprendimento utilizzando una formula del coseno. |
|
"cyclical" (da R2024b) | Programma della velocità di apprendimento ciclico. Per periodi di 10 epoche, questo programma aumenta la velocità di apprendimento rispetto alla velocità di base per 5 epoche e poi la diminuisce per 5 epoche. |
|







Oggetto programma della velocità di apprendimento integrato (da R2024b)
Se si desidera una maggiore flessibilità rispetto a quella offerta dalle opzioni di stringa, è possibile utilizzare gli oggetti integrati programma della velocità di apprendimento:
piecewiseLearnRate: un oggetto programma della velocità di apprendimento a tratti riduce periodicamente la velocità di apprendimento moltiplicandola per un fattore specificato. Utilizzare questo oggetto per personalizzare il fattore di riduzione e il periodo del programma a tratti.Prima di R2024b: Personalizzare il fattore di riduzione e il periodo utilizzando rispettivamente le opzioni di addestramento
LearnRateDropFactoreLearnRateDropPeriod.warmupLearnRate: un oggetto programma della velocità di apprendimento graduale aumenta l'apprendimento per un numero specificato di iterazioni. Utilizzare questo oggetto per personalizzare i fattori della velocità di apprendimento iniziale e finale e il numero di passi del programma graduale.polynomialLearnRate: un programma della velocità di apprendimento polinomiale riduce la velocità di apprendimento utilizzando una legge esponenziale. Utilizzare questo oggetto per personalizzare i fattori della velocità di apprendimento iniziale e finale, l'esponente e il numero di passi del programma polinomiale.exponentialLearnRate: un programma della velocità di apprendimento esponenziale fa decadere la velocità di apprendimento di un fattore specificato. Utilizzare questo oggetto per personalizzare il fattore di riduzione e il periodo del programma esponenziale.cosineLearnRate: un oggetto programma della velocità di apprendimento basato sul coseno riduce la velocità di apprendimento utilizzando una curva del coseno e incorpora i riavvii graduali. Utilizzare questo oggetto per personalizzare i fattori della velocità di apprendimento iniziale e finale, il periodo e il fattore di crescita del periodo del programma basato sul coseno.cyclicalLearnRate: un programma della velocità di apprendimento ciclico aumenta e diminuisce periodicamente la velocità di apprendimento. Utilizzare questa opzione per personalizzare il fattore massimo, il periodo e il rapporto di passo del programma ciclico.
Programma delle velocità di apprendimento personalizzato (da R2024b)
Per una maggiore flessibilità, è possibile definire un programma della velocità di apprendimento personalizzato come handle della funzione o classe personalizzata che eredita da deep.LearnRateSchedule.
Handle della funzione del programma della velocità di apprendimento personalizzato: se il programma della velocità di apprendimento necessario non è un programma integrato, è possibile specificare programmi della velocità di apprendimento personalizzati utilizzando un handle della funzione. Per specificare un programma personalizzato, utilizzare un handle della funzione con la sintassi
learningRate = f(baseLearningRate,epoch), dovebaseLearningRateè la velocità di apprendimento di base eepochè il numero di epoche.Oggetto programma della velocità di apprendimento personalizzato: se si necessita di una maggiore flessibilità rispetto a quella offerta dagli handle della funzione, è possibile definire una classe del programma della velocità di apprendimento personalizzato che eredita da
deep.LearnRateSchedule.
Programmi della velocità di apprendimento multipli (da R2024b)
È possibile combinare programmi della velocità di apprendimento multipli specificando più programmi come array di stringhe o di celle; il software applica poi i programmi in ordine, partendo dal primo elemento. Al massimo uno dei programmi può essere infinito (programmi che continuano all'infinito, come "cyclical" e oggetti con la proprietà NumSteps impostata su Inf); il programma infinito deve essere l'ultimo elemento dell'array.
Contributo della fase di aggiornamento dei parametri dell’iterazione precedente a quella attuale della discesa stocastica del gradiente con momento, specificato come uno scalare da 0 a 1.
Un valore di 0 indica l’assenza di contributo dalla fase precedente, mentre un valore di 1 indica un contributo massimo dalla fase precedente. Il valore predefinito funziona bene per la maggior parte delle attività.
Questo argomento supporta solo il solver SGDM (quando l'argomento solverName è "sgdm").
Per ulteriori informazioni, vedere Discesa stocastica del gradiente con momento.
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Velocità di decadimento della media mobile del gradiente per il solver Adam, specificata come uno scalare non negativo inferiore a 1. La velocità di decadimento del gradiente è indicata da β1 nella sezione Stima adattiva del momento.
Questo argomento supporta solo il solver Adam (quando l'argomento solverName è "adam").
Per ulteriori informazioni, vedere Stima adattiva del momento.
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Velocità di decadimento della media mobile del gradiente quadratico per i solver Adam e RMSProp, specificata come uno scalare non negativo inferiore a 1. La velocità di decadimento del gradiente quadratico è indicata con β2 in [4].
Valori tipici della velocità di decadimento 0.9, 0.99 e 0.999, che corrispondono rispettivamente alle lunghezze medie degli aggiornamenti dei parametri 10, 100 e 1000.
Questa opzione supporta solo i solver Adam e RMSProp (quando l'argomento solverName è "adam" o "rmsprop").
Il valore predefinito per il solver Adam è 0.999. Il valore predefinito per il solver RMSProp è 0.9.
Per ulteriori informazioni, vedere Stima adattiva del momento e Propagazione quadratica media.
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Offset del denominatore per i solver Adam e RMSProp, specificato come uno scalare positivo.
Il solver aggiunge l’offset al denominatore negli aggiornamenti dei parametri della rete neurale per evitare una divisione per zero. Il valore predefinito funziona bene per la maggior parte delle attività.
Questa opzione supporta solo i solver Adam e RMSProp (quando l'argomento solverName è "adam" o "rmsprop").
Per ulteriori informazioni, vedere Stima adattiva del momento e Propagazione quadratica media.
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Fattore per la riduzione della velocità di apprendimento, specificato come uno scalare da 0 a 1. Questo argomento è valido solo quando l'argomento LearnRateSchedule è "piecewise".
LearnRateDropFactor è un fattore di moltiplicazione da applicare alla velocità di apprendimento ogni volta che passa un certo numero di epoche. Specificare il numero di epoche utilizzando l'argomento LearnRateDropPeriod.
Questa opzione supporta solo i solver stocastici (quando l'argomento solverName è "sgdm", "adam" o "rmsprop").
Suggerimento
Per personalizzare il programma della velocità di apprendimento a tratti, utilizzare un oggetto piecewiseLearnRate. Un oggetto piecewiseLearnRate è consigliato rispetto alle opzioni di addestramento LearnRateDropFactor e LearnRateDropPeriod poiché fornisce un ulteriore controllo sulla velocità di riduzione. (da R2024b)
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Numero di epoche per la riduzione della velocità di apprendimento, specificata come numero intero positivo. Questo argomento è valido solo quando il valore LearnRateSchedule è "piecewise".
Il software moltiplica la velocità di apprendimento globale per il fattore di riduzione ogni volta che passa il numero di epoche specificato. Specificare il fattore di riduzione utilizzando l'argomento LearnRateDropFactor.
Questa opzione supporta solo i solver stocastici (quando l'argomento solverName è "sgdm", "adam" o "rmsprop").
Suggerimento
Per personalizzare il programma della velocità di apprendimento a tratti, utilizzare un oggetto piecewiseLearnRate. Un oggetto piecewiseLearnRate è consigliato rispetto alle opzioni di addestramento LearnRateDropFactor e LearnRateDropPeriod poiché fornisce un ulteriore controllo sulla velocità di riduzione. (da R2024b)
Tipi di dati: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Opzioni del solver batch
Convalida
Normalizzazione e regolarizzazione
Ridimensionamento del gradiente
Sequenza
Hardware e accelerazione
Checkpoint
Argomenti di output
Suggerimenti
Per la maggior parte delle attività di Deep Learning, è possibile utilizzare una rete neurale preaddestrata e adattarla ai propri dati. Per un esempio su come utilizzare il transfer learning per riaddestrare una rete neurale convoluzionale per classificare un nuovo set di immagini, vedere Retrain Neural Network to Classify New Images. In alternativa, è possibile creare e addestrare reti neurali da zero utilizzando le funzioni
trainnetetrainingOptions.Se la funzione
trainingOptionsnon fornisce le opzioni di addestramento necessarie per l’attività, è possibile creare un loop di addestramento personalizzato usando la differenziazione automatica. Per saperne di più, vedere Train Network Using Custom Training Loop.Se la funzione
trainnetnon fornisce la funzione di perdita necessaria per l'attività, è possibile specificare una funzione di perdita personalizzata sutrainnetcome handle della funzione. Per le funzioni di perdita che richiedono più input rispetto alle previsioni e ai target (ad esempio, le funzioni di perdita che richiedono l'accesso alla rete neurale o ulteriori input), addestrare il modello utilizzando un loop di addestramento personalizzato. Per saperne di più, vedere Train Network Using Custom Training Loop.Se Deep Learning Toolbox™ non fornisce i livelli necessari per l’attività, è possibile creare un livello personalizzato. Per saperne di più, vedere Define Custom Deep Learning Layers. Per i modelli che non possono essere specificati come reti di livelli, è possibile definire il modello come funzione. Per saperne di più, vedere Train Network Using Model Function.
Per ulteriori informazioni sul metodo di addestramento da utilizzare per un determinato compito, vedere Train Deep Learning Model in MATLAB.
Algoritmi
Riferimenti
[1] Bishop, C. M. Pattern Recognition and Machine Learning. Springer, New York, NY, 2006.
[2] Murphy, K. P. Machine Learning: A Probabilistic Perspective. The MIT Press, Cambridge, Massachusetts, 2012.
[3] Pascanu, R., T. Mikolov, and Y. Bengio. "On the difficulty of training recurrent neural networks". Proceedings of the 30th International Conference on Machine Learning. Vol. 28(3), 2013, pp. 1310–1318.
[4] Kingma, Diederik, and Jimmy Ba. "Adam: A method for stochastic optimization." arXiv preprint arXiv:1412.6980 (2014).
[5] Liu, Dong C., and Jorge Nocedal. "On the limited memory BFGS method for large scale optimization." Mathematical programming 45, no. 1 (August 1989): 503-528. https://doi.org/10.1007/BF01589116.
[6] Marquardt, Donald W. “An Algorithm for Least-Squares Estimation of Nonlinear Parameters.” Journal of the Society for Industrial and Applied Mathematics 11, no. 2 (June 1963): 431–41. https://doi.org/10.1137/0111030.
Cronologia versioni
Introdotto in R2016aVedi anche
trainnet | dlnetwork | analyzeNetwork | Deep Network Designer