Run MATLAB Functions on Multiple GPUs
This example shows how to run MATLAB® code on multiple GPUs in parallel, first on your local machine, then scaling up to a cluster. As a sample problem, the example uses the logistic map, an equation that models the growth of a population.
A growing number of features in MATLAB offer automatic parallel support, including multi-GPU support, without requiring any extra coding. For details, see Run MATLAB Functions with Automatic Parallel Support. For example, the trainnet (Deep Learning Toolbox) function offers multi-GPU support for training neural networks. For more information, see Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud (Deep Learning Toolbox).
Use a Single GPU
To run computations on a single GPU, use gpuArray objects as inputs to GPU-enabled MATLAB functions. To learn more about GPU-enabled functions, see Run MATLAB Functions on a GPU.
Create GPU arrays defining the growth rate, r, and the population, x. For more information on creating gpuArray objects, see Establish Arrays on a GPU.
N = 200000;
r = gpuArray.linspace(0,4,N);
x = rand(1,N,"gpuArray");Use a simple algorithm to iterate the logistic map. Because the algorithm uses GPU-enabled operators on gpuArray input data, the computations run on the GPU.
numIterations = 1000; for n=1:numIterations x = r.*x.*(1-x); end
When the computations are done, plot the growth rate against the population.
plot(r,x,".",MarkerSize=1) xlabel("Growth Rate") ylabel("Population")

If you need more performance, GPU arrays supports several options. For a list, see the gpuArray function page. For example, the algorithm in this example only performs element-wise operations on GPU arrays, and so you can use the arrayfun function to precompile them for GPU.
Use Multiple GPUs with parfor
You can use parfor-loops to distribute for-loop iterations among parallel workers. If your computations use GPU-enabled functions, then the computations run on the GPU of the worker. For example, if you use the Monte Carlo method to randomly simulate the evolution of populations, simulations are computed with multiple GPUs in parallel using a parfor-loop.
Create a parallel pool with as many workers as GPUs available using parpool. To determine the number of GPUs available, use the gpuDeviceCount function. By default, MATLAB assigns a different GPU to each worker for best performance. For more information on selecting GPUs in a parallel pool, see Use Multiple GPUs in Parallel Pool.
numGPUs = gpuDeviceCount("available");
parpool(numGPUs);Starting parallel pool (parpool) using the 'Processes' profile ... Connected to parallel pool with 2 workers.
Define the number of simulations, and create an array in the GPU to store the population vector for each simulation.
numSimulations = 100;
X = zeros(numSimulations,N,"gpuArray");Use a parfor loop to distribute simulations to workers in the pool. The code inside the loop creates a random gpuArray for the initial population, and iterates the logistic map on it. Because the code uses GPU-enabled operators on gpuArray input data, the computations automatically run on the GPU of the worker.
parfor i = 1:numSimulations X(i,:) = rand(1,N,"gpuArray"); for n=1:numIterations X(i,:) = r.*X(i,:).*(1-X(i,:)); end end
When the computations are done, plot the results of all simulations. Each color represents a different simulation.
figure plot(r,X,".",MarkerSize=1) xlabel("Growth Rate") ylabel("Population")
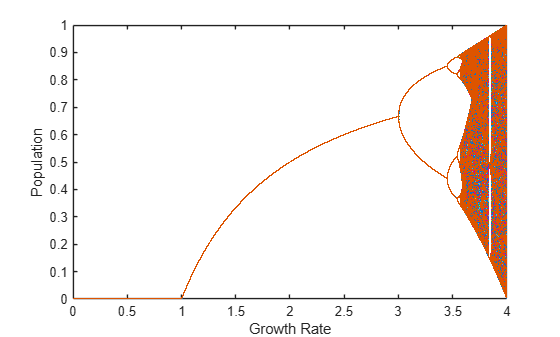
With default settings, parpool starts a parallel pool of process workers. Running code in parallel on process workers often results in data being copied to each worker which can use a significant amount of GPU memory when working with GPU arrays. In contrast, thread workers can share memory. To reduce memory usage and lower data transfer costs, use a parallel pool of thread workers by calling parpool("Threads"). Thread workers support only a subset of functions available for processes workers. For more information, see Choose Between Thread-Based and Process-Based Environments.
If you need greater control over your calculations, you can use more advanced parallel functionality. For example, you can use a parallel.pool.DataQueue to send data from the workers during computations. For an example, see Plot During Parameter Sweep with parfor.
If you want to generate a reproducible set of random numbers, you can control the random number generation on the GPU of a worker. For more information, see Random Number Streams on a GPU.
Use Multiple GPUs Asynchronously with parfeval
You can use parfeval to run computations asynchronously on parallel pool workers. If your computations use GPU-enabled functions, then the computations run on the GPU of the worker. As an example, you run Monte Carlo simulations on multiple GPUs asynchronously.
To hold the results of computations after the workers complete them, use future objects. Preallocate an array of future objects for the result of each simulation.
f(numSimulations) = parallel.FevalFuture;
To run computations with parfeval, you must place them inside a function. Define a function that contains the code of a single simulation.
function x = myParallelFcn(r) N = 200000; x = gpuArray.rand(1,N); numIterations = 1000; for n=1:numIterations x = r.*x.*(1-x); end end
Use a for loop to loop over simulations, and use parfeval to run them asynchronously on a worker in the parallel pool. myParallelFcn uses GPU-enabled functions on gpuArray input data, so they run on the GPU of the worker. Because parfeval performs the computations asynchronously, it does not block MATLAB, and you can continue working while computations happen.
for i=1:numSimulations f(i) = parfeval(@myParallelFcn,1,r); end
To collect the results from parfeval when they are ready, you can use fetchOutputs or fetchNext on the future objects. Also, you can use afterEach or afterAll to invoke functions on the results automatically when they are ready. For example, to plot the result of each simulation immediately after it completes, use afterEach on the future objects. Each color represents a different simulation.
figure xlabel("Growth Rate") ylabel("Population") hold on afterEach(f,@(x) plot(r,x,".",MarkerSize=1),0); wait(f) hold off
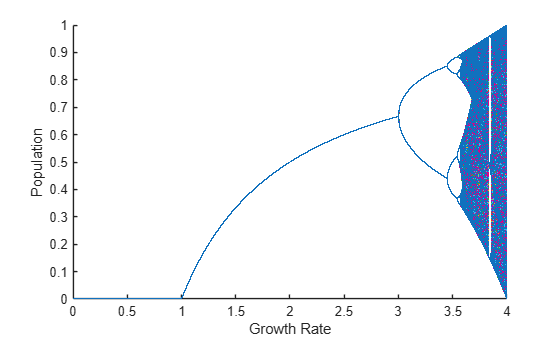
Use Multiple GPUs in a Cluster
If you have access to a cluster with multiple GPUs, then you can scale up your computations. Use the parpool function to start a parallel pool on the cluster. When you do so, parallel features, such as parfor loops or parfeval, run on the cluster workers. If your computations use GPU-enabled functions on gpuArray input data, then those functions run on the GPU of the cluster worker. Note that cluster features are supported only in process-based environments. For an example showing how to run your code on remote GPUs in a cluster, see Work with Remote GPUs. To learn more about running parallel features on a cluster, see Scale Up from Desktop to Cluster.
Advanced Support for Fast Multi-Node GPU Communication
Some multi-GPU features in MATLAB®, including the trainnet function, are optimized for
direct communication via fast interconnects for improved performance.
If you have appropriate hardware connections, then data transfer between multiple GPUs uses fast peer-to-peer communication, including NVLink, if available.
If you are using a Linux® compute cluster with fast interconnects between machines such as Infiniband,
or fast interconnects between GPUs on different machines, such as GPUDirect RDMA, you might
be able to take advantage of fast multi-node support in MATLAB. Enable this support on all the workers in your pool by setting the
environment variable PARALLEL_SERVER_FAST_MULTINODE_GPU_COMMUNICATION to
1. Set this environment variable in the Cluster Profile
Manager.
This feature is part of the NVIDIA NCCL library for GPU communication. To configure it, you must set additional environment variables to define the network interface protocol, especially NCCL_SOCKET_IFNAME. For more information, see the NCCL documentation and in particular the section on NCCL Environment Variables.
See Also
gpuArray | gpuDevice | parpool | parfor | parfeval | fetchOutputs | afterEach
Topics
- Run MATLAB Functions on a GPU
- Work with Remote GPUs
- Scale Up from Desktop to Cluster
- Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud (Deep Learning Toolbox)
- GPU Computing in MATLAB