refit
Refit neighborhood component analysis (NCA) model for regression
Description
mdlrefit = refit(mdl,Name=Value)mdl, with modified parameters specified by one
or more name-value arguments.
Examples
Load the sample data.
load("robotarm.mat")The robotarm (pumadyn32nm) data set is created using a robot arm simulator with 7168 training and 1024 test observations with 32 features [1], [2]. This is a preprocessed version of the original data set. Data are preprocessed by subtracting off a linear regression fit followed by normalization of all features to unit variance.
Compute the generalization error without feature selection.
nca = fsrnca(Xtrain,ytrain,FitMethod="none", ... Standardize=true); L = loss(nca,Xtest,ytest)
L = 0.9017
Now, refit the model and compute the prediction loss with feature selection, with = 0 (no regularization term) and compare to the previous loss value, to determine feature selection seems necessary for this problem. For the settings that you do not change, refit uses the settings of the initial model nca. For example, it uses the feature weights found in nca as the initial feature weights.
nca2 = refit(nca,FitMethod="exact",Lambda=0);
L2 = loss(nca2,Xtest,ytest)L2 = 0.1088
The decrease in the loss suggests that feature selection is necessary.
Plot the feature weights.
plot(nca2.FeatureWeights,"o")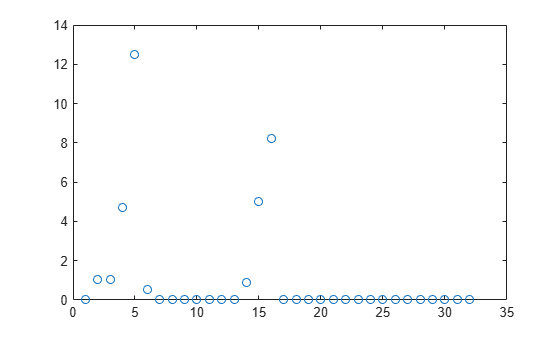
Tuning the regularization parameter usually improves the results. Suppose that, after tuning using cross-validation as in Tune Regularization Parameter in NCA for Regression, the best value found is 0.0035. Refit the nca model using this value and stochastic gradient descent as the solver. Compute the prediction loss.
nca3 = refit(nca2,FitMethod="exact",Lambda=0.0035, ... Solver="sgd"); L3 = loss(nca3,Xtest,ytest)
L3 = 0.0573
Plot the feature weights.
plot(nca3.FeatureWeights,"o")
After tuning the regularization parameter, the loss decreased even more and the software identified four of the features as relevant.
References
[1] Rasmussen, C. E., R. M. Neal, G. E. Hinton, D. van Camp, M. Revow, Z. Ghahramani, R. Kustra, and R. Tibshirani. The DELVE Manual, 1996, https://mlg.eng.cam.ac.uk/pub/pdf/RasNeaHinetal96.pdf
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2016b
See Also
FeatureSelectionNCARegression | loss | fsrnca | predict | selectFeatures