robustfit
Fit robust linear regression
Description
Examples
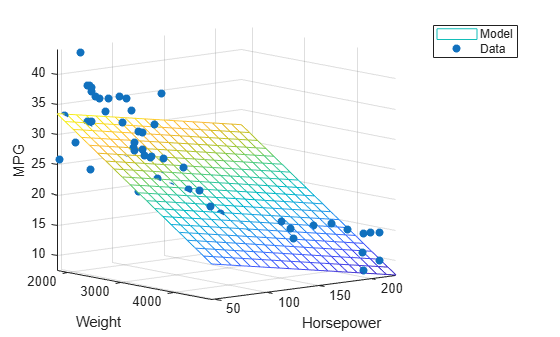
Estimate robust regression coefficients for a multiple linear model.
Load the carsmall data set. Specify car weight and horsepower as predictors and mileage per gallon as the response.
load carsmall
x1 = Weight;
x2 = Horsepower;
X = [x1 x2];
y = MPG;Compute the robust regression coefficients.
b = robustfit(X,y)
b = 3×1
47.1975
-0.0068
-0.0333
Plot the fitted model.
x1fit = linspace(min(x1),max(x1),20); x2fit = linspace(min(x2),max(x2),20); [X1FIT,X2FIT] = meshgrid(x1fit,x2fit); YFIT = b(1) + b(2)*X1FIT + b(3)*X2FIT; mesh(X1FIT,X2FIT,YFIT)
Plot the data.
hold on scatter3(x1,x2,y,'filled') hold off xlabel('Weight') ylabel('Horsepower') zlabel('MPG') legend('Model','Data') view(50,10) axis tight
Tune the weight function for robust regression by using different tuning constants.
Generate data with the trend , and then change one value to simulate an outlier.
x = (1:10)'; rng ('default') % For reproducibility y = 10 - 2*x + randn(10,1); y(10) = 0;
Compute the robust regression residuals using the bisquare weight function for three different tuning constants. The default tuning constant is 4.685.
tune_const = [3 4.685 6]; for i = 1:length(tune_const) [~,stats] = robustfit(x,y,'bisquare',tune_const(i)); resids(:,i) = stats.resid; end
Create a plot of the residuals.
scatter(x,resids(:,1),'b','filled') hold on plot(resids(:,2),'rx','MarkerSize',10,'LineWidth',2) scatter(x,resids(:,3),'g','filled') plot([min(x) max(x)],[0 0],'--k') hold off grid on xlabel('x') ylabel('Residuals') legend('tune = 3','tune = 4.685','tune = 6','Location','best')

Compute the root mean squared error (RMSE) of residuals for the three different tuning constants.
rmse = sqrt(mean(resids.^2))
rmse = 1×3
3.2577 2.7576 2.7099
Because increasing the tuning constant decreases the downweight assigned to outliers, the RMSE decreases as the tuning constant increases.
Generate data with the trend , and then change one value to simulate an outlier.
x = (1:10)'; rng('default') % For reproducibility y = 10 - 2*x + randn(10,1); y(10) = 0;
Fit a straight line using ordinary least-squares regression. To compute coefficient estimates for a model with a constant term, include a column of ones in x.
bls = regress(y,[ones(10,1) x])
bls = 2×1
7.8518
-1.3644
Estimate a straight-line fit using robust regression. robustfit adds a constant term to the model by default.
[brob,stats] = robustfit(x,y); brob
brob = 2×1
8.4504
-1.5278
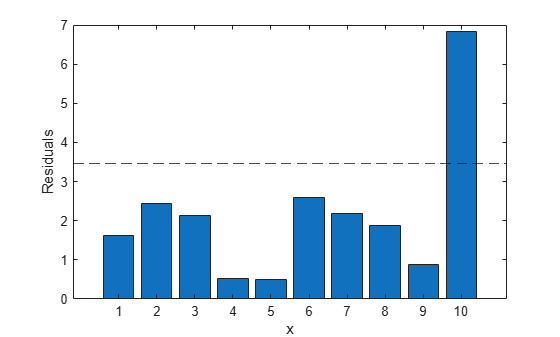
Identify potential outliers by comparing the residuals to the median absolute deviation of the residuals.
outliers_ind = find(abs(stats.resid)>stats.mad_s);
Plot a bar graph of the residuals for robust regression.
bar(abs(stats.resid)) hold on yline(stats.mad_s,'k--') hold off xlabel('x') ylabel('Residuals')
Create a scatter plot of the data.
scatter(x,y,'filled')Plot the outlier.
hold on plot(x(outliers_ind),y(outliers_ind),'mo','LineWidth',2)
Plot the least-squares and robust fit.
plot(x,bls(1)+bls(2)*x,'r') plot(x,brob(1)+brob(2)*x,'g') hold off xlabel('x') ylabel('y') legend('Data','Outlier','Ordinary Least Squares','Robust Regression') grid on
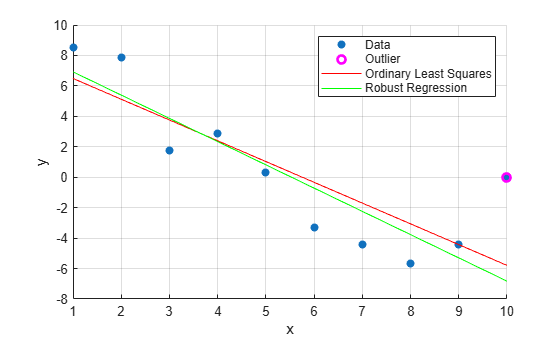
The outlier influences the robust fit less than the least-squares fit.
Input Arguments
Output Arguments
More About
Tips
Algorithms
robustfituses iteratively reweighted least squares to compute the coefficientsb. The inputwfunspecifies the weights.robustfitestimates the variance-covariance matrix of the coefficient estimatesstats.covbusing the formulainv(X'*X)*stats.s^2. This estimate produces the standard errorstats.seand correlationstats.coeffcorr.In a linear model, observed values of
yand their residuals are random variables. Residuals have normal distributions with zero mean but with different variances at different values of the predictors. To put residuals on a comparable scale,robustfit“Studentizes” the residuals. That is,robustfitdivides the residuals by an estimate of their standard deviation that is independent of their value. Studentized residuals have t-distributions with known degrees of freedom.robustfitreturns the Studentized residuals instats.rstud.
Alternative Functionality
robustfit is useful when you simply need the output arguments of the
function or when you want to repeat fitting a model multiple times in a loop. If you need to
investigate a robust fitted regression model further, create a linear regression model object
LinearModel by using fitlm. Set the value for the name-value pair
argument 'RobustOpts' to 'on'.
References
[1] DuMouchel, W. H., and F. L. O'Brien. “Integrating a Robust Option into a Multiple Regression Computing Environment.” Computer Science and Statistics: Proceedings of the 21st Symposium on the Interface. Alexandria, VA: American Statistical Association, 1989.
[2] Holland, P. W., and R. E. Welsch. “Robust Regression Using Iteratively Reweighted Least-Squares.” Communications in Statistics: Theory and Methods, A6, 1977, pp. 813–827.
[3] Huber, P. J. Robust Statistics. Hoboken, NJ: John Wiley & Sons, Inc., 1981.
[4] Street, J. O., R. J. Carroll, and D. Ruppert. “A Note on Computing Robust Regression Estimates via Iteratively Reweighted Least Squares.” The American Statistician. Vol. 42, 1988, pp. 152–154.
Version History
Introduced before R2006a