Example Using the Hadoop Compiler App Workflow
Supported Platform: Linux® only.
This example shows you how to use the Hadoop Compiler app to create a deployable archive consisting of MATLAB® map and reduce functions and then pass the deployable archive as a payload argument to a job submitted to a Hadoop® cluster.
Goal: Calculate the maximum arrival delay of an airline from the given dataset.
| Dataset: | airlinesmall.csv |
| Description: |
Airline departure and arrival information from 1987-2008. |
| Location: | /usr/local/MATLAB/R2024b/toolbox/matlab/demos |
Prerequisites
Start this example by creating a new work folder that is visible to the MATLAB search path.
Before starting MATLAB, at a terminal, set the environment variable
HADOOP_PREFIXto point to the Hadoop installation folder. For example:Shell Command csh / tcsh % setenv HADOOP_PREFIX /usr/lib/hadoop
bash $ export HADOOP_PREFIX=/usr/lib/hadoop
Note
This example uses
/usr/lib/hadoopas directory where Hadoop is installed. Your Hadoop installation directory maybe different.If you forget setting the
HADOOP_PREFIXenvironment variable prior to starting MATLAB, set it up using the MATLAB functionsetenvat the MATLAB command prompt as soon as you start MATLAB. For example:setenv('HADOOP_PREFIX','/usr/lib/hadoop')
Install the MATLAB Runtime in a folder that is accessible by every worker node in the Hadoop cluster. This example uses
/usr/local/MATLAB/MATLAB_Runtime/R2024bas the location of the MATLAB Runtime folder.If you don’t have the MATLAB Runtime, you can download it from the website at:
https://www.mathworks.com/products/compiler/mcr.Note
For information about MATLAB Runtime version numbers corresponding MATLAB releases, see this list.
Copy the map function
maxArrivalDelayMapper.mfrom/usr/local/MATLAB/R2024b/toolbox/matlab/demosfolder to the work folder.For more information, see Write a Map Function.
Copy the reduce function
maxArrivalDelayReducer.mfrommatlabroot/toolbox/matlab/demosFor more information, see Write a Reduce Function.
Create the directory
/user/on HDFS™ and copy the file<username>/datasetsairlinesmall.csvto that directory. Here<username>$ ./hadoop fs -copyFromLocal airlinesmall.csv hdfs://host:54310/user/<username>/datasets
Procedure
Start MATLAB and verify that the
HADOOP_PREFIXenvironment variable has been set. At the command prompt, type:>> getenv('HADOOP_PREFIX')If
ansis empty, review the Prerequisites section above to see how you can set theHADOOP_PREFIXenvironment variable.Create a
datastoreto the fileairlinesmall.csvand save it to a.matfile. Thisdatastoreobject is meant to capture the structure of your actual dataset on HDFS.ds = datastore('airlinesmall.csv','TreatAsMissing','NA',... 'SelectedVariableNames','ArrDelay','ReadSize',1000); save('infoAboutDataset.mat','ds')
In most cases, you will start off by working on a small sample dataset residing on a local machine that is representative of the actual dataset on the cluster. This sample dataset has the same structure and variables as the actual dataset on the cluster. By creating a
datastoreobject to the dataset residing on your local machine you are taking a snapshot of that structure. By having access to thisdatastoreobject, a Hadoop job executing on the cluster will know how to access and process the actual dataset residing on HDFS.Note
In this example, the sample dataset (local) and the actual dataset on HDFS are the same.
Launch the Hadoop Compiler app through the MATLAB command line (
>> hadoopCompiler) or through the apps gallery.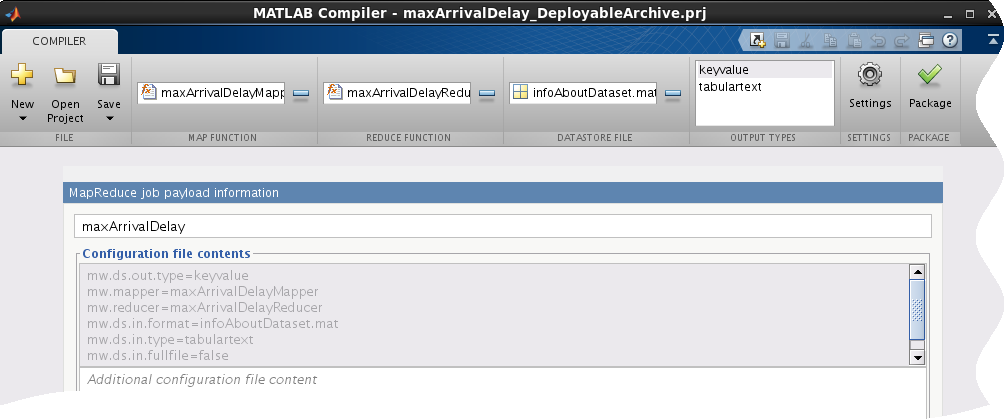
In the Map Function section of the toolstrip, click the plus button to add mapper file
maxArrivalDelayMapper.m.In the Reduce Function section of the toolstrip, click the plus button to add reducer file
maxArrivalDelayReducer.m.In the Datastore File section, click the plus button to add the
.matfileinfoAboutDataset.matcontaining thedatastoreobject.In the Output Types section, select
keyvalueas output type. Selectingkeyvalueas your output type means your results can only be read within MATLAB. If you want your results to be accessible outside of MATLAB, select output type astabulartext.Rename the MapReduce job payload information to
maxArrivalDelay.Click Package to build a deployable archive.
The Hadoop Compiler app creates a log file
PackagingLog.txtand two foldersfor_redistributionandfor_testing.for_redistributionfor_testingreadme.txtreadme.txtmaxArrivalDelay.ctfmaxArrivalDelay.ctfrun_maxArrivalDelay.shrun_maxArrivalDelay.shmccExcludedFiles.logrequiredMCRProducts.txtYou can use the log file
PackagingLog.txtto see the exactmccsyntax used to package the deployable archive.From a Linux shell navigate to the
for_redistributionfolder.Incorporate the deployable archive containing MATLAB map and reduce functions into a Hadoop mapreduce job from a Linux shell using the following command:
$ hadoop \ jar /usr/local/MATLAB/MATLAB_Runtime/R2024b/toolbox/mlhadoop/jar/a2.2.0/mwmapreduce.jar \ com.mathworks.hadoop.MWMapReduceDriver \ -D mw.mcrroot=/usr/local/MATLAB/MATLAB_Runtime/R2024b \ maxArrivalDelay.ctf \ hdfs://host:54310/user/<username>/datasets/airlinesmall.csv \ hdfs://host:54310/user/<username>/resultsAlternately, you can incorporate the deployable archive containing MATLAB map and reduce functions into a Hadoop mapreduce job using the shell script generated by the Hadoop Compiler app. At the Linux shell type the following command:
$ ./run_maxArrivalDelay.sh \ /usr/local/MATLAB/MATLAB_Runtime/R2024b \ -D mw.mcrroot=/usr/local/MATLAB/MATLAB_Runtime/R2024b \ hdfs://host:54310/user/username/datasets/airlinesmall.csv \ hdfs://host:54310/user/<username>/results
To examine the results, switch to the MATLAB desktop and create a
datastoreto the results on HDFS. You can then view the results using thereadmethod.d = datastore('hdfs:///user/<username>/results/part*'); read(d)ans = Key Value _________________ ______ 'MaxArrivalDelay' [1014]
To learn more about using the map and
reduce functions, see Getting Started with MapReduce.
See Also
datastore | TabularTextDatastore | KeyValueDatastore | deploytool
Related Topics
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)