Regressione lineare con una variabile predittiva
La regressione lineare semplice descrive la relazione tra una singola variabile predittiva e una variabile di risposta. Un modello di regressione lineare è utile per comprendere come le variazioni del predittore influenzano la risposta.
Questo esempio mostra come adattare, visualizzare e validare modelli di regressione lineare semplici di vari gradi utilizzando le funzioni polyfit e polyval. Per informazioni sull'adattamento e la visualizzazione di un modello utilizzando invece lo strumento Adattamento di base, vedere Interactively Fit Data and Visualize Model.
Utilizzare la regressione lineare semplice quando:
Si dispone di una variabile predittiva.
La relazione tra il predittore e la risposta è lineare nei coefficienti.
Si desidera quantificare l'effetto del predittore sulla risposta.
Plottaggio dei dati
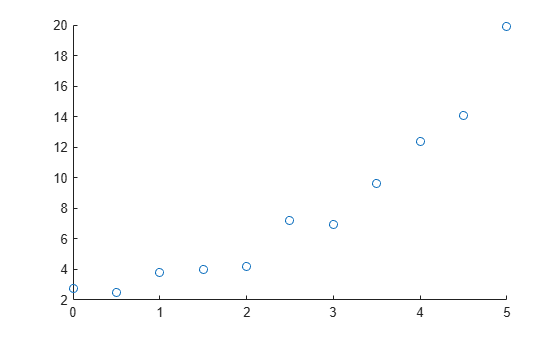
Iniziare tracciando i dati per identificare i possibili gradi per l'adattamento polinomiale.
Ad esempio, creare e visualizzare una variabile predittiva campione x e una variabile di risposta campione y. Questa visualizzazione suggerisce che un adattamento lineare o quadratico potrebbe descrivere la relazione tra le variabili predittive e quelle di risposta.
x = [0:0.5:5]'; y = [2.73 2.50 3.79 3.98 4.21 7.18 6.95 9.63 12.39 14.10 19.93]'; scatter(x,y)
Adattamento del modello di primo grado
Adattare un modello (lineare) di primo grado ai dati utilizzando la funzione polyfit. Specificare due argomenti di output per restituire i coefficienti polinomiali e la struttura di stima dell'errore.
[pLinear,SLinear] = polyfit(x,y,1)
pLinear = 1×2
3.1316 0.1155
SLinear = struct with fields:
R: [2×2 double]
df: 9
normr: 6.3071
rsquared: 0.8715
Visualizzare il modello adattato.
eqLinear = "Linear: " + pLinear(1) + "x + " + pLinear(2)
eqLinear = "Linear: 3.1316x + 0.11545"
Adattamento del modello di grado superiore
Se un modello di primo grado non descrive adeguatamente la relazione tra le variabili predittive e quelle di risposta, è possibile adattare un modello di grado superiore. Ad esempio, adattare un modello (quadratico) di secondo grado ai dati utilizzando la funzione polyfit. Specificare due argomenti di output per restituire i coefficienti polinomiali e la struttura di stima dell'errore.
[pQuad,SQuad] = polyfit(x,y,2)
pQuad = 1×3
0.7898 -0.8175 3.0773
SQuad = struct with fields:
R: [3×3 double]
df: 8
normr: 2.5152
rsquared: 0.9796
Visualizzare il modello adattato.
eqQuad = "Quadratic: " + pQuad(1) + "x^2 + " + pQuad(2) + "x + " + pQuad(3)
eqQuad = "Quadratic: 0.78984x^2 + -0.81755x + 3.0773"
Confronto di modelli
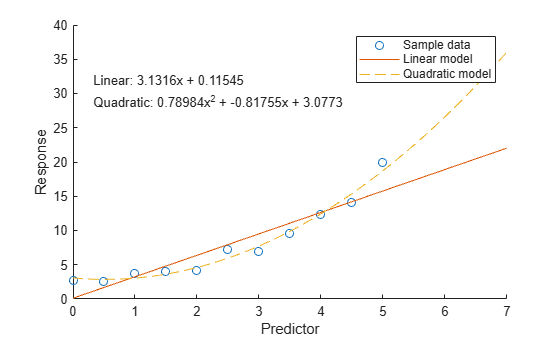
Per confrontare i modelli utilizzando un grafico, valutare innanzitutto ciascun modello nei punti di query e restituire i valori di risposta previsti utilizzando la funzione polyval. Quindi visualizzare i dati ed entrambi i modelli.
Ad esempio, ottenere i valori di risposta per il modello lineare e il modello quadratico su un intervallo più dettagliato di valori x.
xQuery = [0:0.05:7]'; yLinear = polyval(pLinear,xQuery); yQuad = polyval(pQuad,xQuery);
Se il modello di grado superiore non predice bene i valori della risposta, questo potrebbe indicare un sovradattamento. Per informazioni sulla validazione del modello e sulla selezione della complessità appropriata del modello, vedere la sezione Validate Model (Validazione del modello).
Quindi tracciare i dati campione e i dati del modello.
scatter(x,y) hold on plot(xQuery,yLinear,"-") plot(xQuery,yQuad,"--") hold off xlabel("Predictor") ylabel("Response") legend(["Sample data" "Linear model" "Quadratic model"]) text(0.3,30,[eqLinear eqQuad])
Validazione dei modelli
Per validare un modello, calcolare il coefficiente di determinazione (R quadro) o il coefficiente di determinazione corretto (R quadro corretto). Un valore vicino a 1 indica un buon adattamento.
Validazione del modello lineare con R quadro
Per un modello di primo grado, è possibile accedere al valore di R quadro utilizzando la struttura di stima dell'errore restituita dalla funzione polyfit. Ad esempio, eseguire una query nel campo rsquared in SLinear.
linearR2 = SLinear.rsquared
linearR2 = 0.8715
Validazione del modello di grado superiore con R quadro corretto
Per i modelli di grado superiore con più termini, il valore R quadro in genere aumenta, indicando un maggiore adattamento ai dati osservati. Tuttavia, questi modelli presentano un rischio maggiore di sovradattamento.
Il sovradattamento si verifica quando un modello descrive i dati originali troppo da vicino (compreso il rumore) e non è un buon predittore dei nuovi dati.
Per bilanciare la qualità della previsione e la complessità del modello, si consideri di validare il modello utilizzando il valore di R quadro corretto, che include una penalizzazione per il numero di predittori. È possibile calcolare il valore di R quadro corretto utilizzando questa equazione, dove è il valore del campo rsquared nella struttura di stima dell'errore, è il numero di osservazioni nei dati e è il grado del modello.
Ad esempio, calcolare il valore di R quadro corretto per il modello quadratico.
quadAdjRsq = 1 - (1 - SQuad.rsquared) * (numel(y) - 1) / (numel(y) - 2 - 1)
quadAdjRsq = 0.9744
Calcolo dell'errore di previsione massimo per ciascun modello
È inoltre possibile validare un modello calcolando l'errore massimo tra le previsioni del modello e i dati campione. Un errore massimo ridotto rispetto ai valori dei dati indica un buon adattamento.
Ad esempio, calcolare l'errore massimo sia per il modello lineare che per quello quadratico.
Lia = ismember(xQuery,x); linearMaxError = max(abs(yLinear(Lia) - y))
linearMaxError = 4.1564
quadMaxError = max(abs(yQuad(Lia) - y))
quadMaxError = 1.2926
Vedi anche
Funzioni
Argomenti
- Interactively Fit Data and Visualize Model
- Linear Regression with Nonpolynomial Terms
- Linear Regression with Multiple Predictor Variables
- Creazione e valutazione dei polinomi
- Linear Regression Workflow (Statistics and Machine Learning Toolbox)
- Fit Polynomial Models (Curve Fitting Toolbox)