Rilevamento, estrazione e corrispondenza di feature
Le feature locali e i relativi descrittori costituiscono i blocchi costitutivi di molti algoritmi di visione artificiale. Tra le loro applicazioni figurano la registrazione delle immagini, il rilevamento e la classificazione degli oggetti, il tracking, la stima del movimento e il recupero di immagini basato sul contenuto (CBIR). Questi algoritmi utilizzano feature locali per gestire meglio le variazioni di scala, la rotazione e l'occlusione. Gli algoritmi Computer Vision Toolbox™ includono i rilevatori di angoli FAST, Harris e Shi & Tomasi, nonché i rilevatori di blob SIFT, SURF, KAZE e MSER. La toolbox include i descrittori SIFT, SURF, FREAK, BRISK, LBP, ORB e HOG. È possibile combinare i rilevatori e i descrittori in base ai requisiti dell'applicazione.
App
| Registration Estimator | Register 2-D grayscale images |
Funzioni
Argomenti
- Local Feature Detection and Extraction
Learn the benefits and applications of local feature detection and extraction.
- Point Feature Types
Choose functions that return and accept points objects for several types of features.
- Sistemi di coordinate
Specificare gli indici dei pixel, le coordinate spaziali e i sistemi di coordinate in 3D
- Image Retrieval with Bag of Visual Words
Retrieve images from a collection of images similar to a query image using a content-based image retrieval (CBIR) system.
Esempi in primo piano

Image Retrieval Using Customized Bag of Features
Create a Content Based Image Retrieval (CBIR) system using a customized bag-of-features workflow.
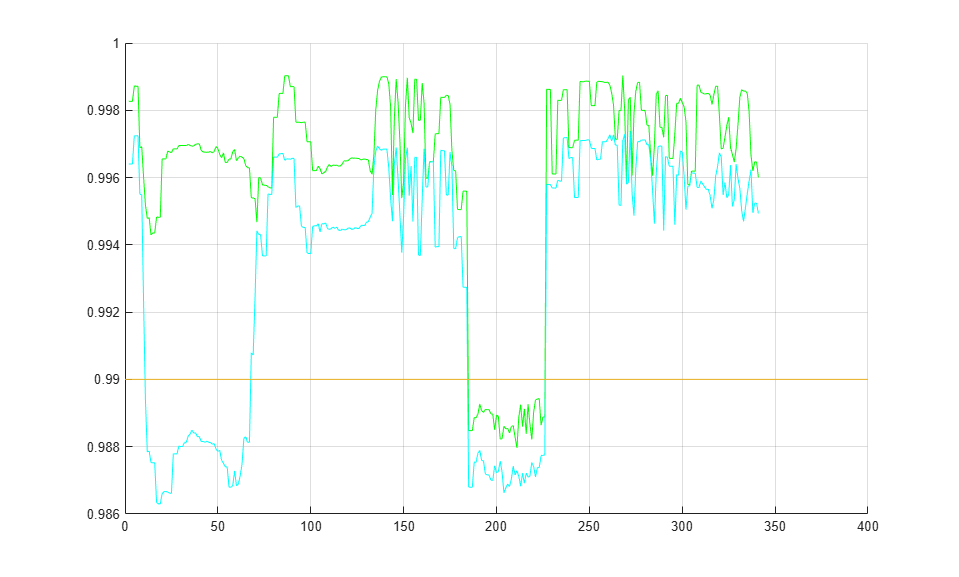
Pattern Matching
Use the 2-D normalized cross-correlation for pattern matching and target tracking. The example uses predefined or user specified target and number of similar targets to be tracked. The normalized cross correlation plot shows that when the value exceeds the set threshold, the target is identified.

Find Object in Cluttered Scene Using Image Point Features
Detect a particular object in a cluttered scene, given a reference image of the object.

Digit Classification Using HOG Features
Classify digits using HOG features and a multiclass SVM classifier.

Automatically Find Image Rotation and Scale
Demonstrates how to automatically determine the geometric transformation between two images. Specifically, when one image is distorted in relation to another due to rotation and scaling, the functions detectSIFTFeatures and estgeotform2d can be employed to identify the rotation angle and scale factor. Subsequently, these parameters can be used to transform the distorted image back to its original appearance.

Create Panorama
Automatically stitch multiple images into panorama. The procedure for image stitching is an extension of feature based image registration. Instead of registering a single pair of images, multiple image pairs are successively registered relative to each other to form a panorama.

Stabilize Video Using Image Point Features
Stabilize a video that was captured from a jittery platform. One way to stabilize a video is to track a salient feature in the image and use this as an anchor point to cancel out all perturbations relative to it. This procedure, however, must be bootstrapped with knowledge of where such a salient feature lies in the first video frame. In this example, we explore a method of video stabilization that works without any such apriori knowledge. It instead automatically searches for the "background plane" in a video sequence, and uses the observed distortion to correct for camera motion.

Object Counting
Use morphological operations to count objects in a video stream.

Cell Counting
Use a combination of basic morphological operators and blob analysis to extract information from a video stream. In this case, the example counts the number of E. Coli bacteria in each video frame. Note that the cells are of varying brightness, which makes the task of segmentation more challenging.