Import Pretrained ONNX YOLO v2 Object Detector
This example shows how to import a pretrained ONNX™ (Open Neural Network Exchange) you only look once (YOLO) v2 [1] object detection network and use the network to detect objects. After you import the network, you can deploy it to embedded platforms using GPU Coder™ or perform transfer learning and retrain it on custom data using the trainYOLOv2ObjectDetector function.
Import ONNX YOLO v2 Network
Download files related to the pretrained Tiny YOLO v2 network.
pretrainedURL = "https://ssd.mathworks.com/supportfiles/vision/deeplearning/models/yolov2/tiny_yolov2.tar"; pretrainedNetTar = "yolov2Tiny.tar"; if ~exist(pretrainedNetTar,"file") disp("Downloading pretrained network (58 MB)...") websave(pretrainedNetTar,pretrainedURL); end
Downloading pretrained network (58 MB)...
Extract the contents of the downloaded .tar file, which includes the Tiny YOLO v2 network. Load the Model.onnx model from the tiny_yolov2 folder. This model is an ONNX YOLO v2 network pretrained on the PASCAL VOC data set [2]. The network can detect objects from 20 different classes [3].
onnxfiles = untar(pretrainedNetTar); pretrainedNet = fullfile("tiny_yolov2","Model.onnx");
Import the downloaded network by using the importNetworkFromONNX function.
net = importNetworkFromONNX(pretrainedNet);
Create YOLO v2 Object Detector
Define YOLO v2 Anchor Boxes
YOLO v2 uses predefined anchor boxes to predict object locations. The anchor boxes used in the imported network are defined in the Tiny YOLO v2 network configuration file [4]. The ONNX anchors are defined with respect to the output size of the final convolution layer, which is 13-by-13. To use the anchors with a yolov2ObjectDetector, you must resize the anchor boxes to the network input size, which is 416-by-416. Specify the anchor boxes in the form [height width].
onnxAnchors = [1.08 1.19; 3.42 4.41; 6.63 11.38; 9.42 5.11; 16.62 10.52]; inputSize = net.Layers(1,1).InputSize(1:2); lastActivationSize = [13 13]; upScaleFactor = inputSize./lastActivationSize; anchorBoxesTmp = upScaleFactor.*onnxAnchors; anchorBoxes = [anchorBoxesTmp(:,2) anchorBoxesTmp(:,1)];
Reorder Detection Layer Weights
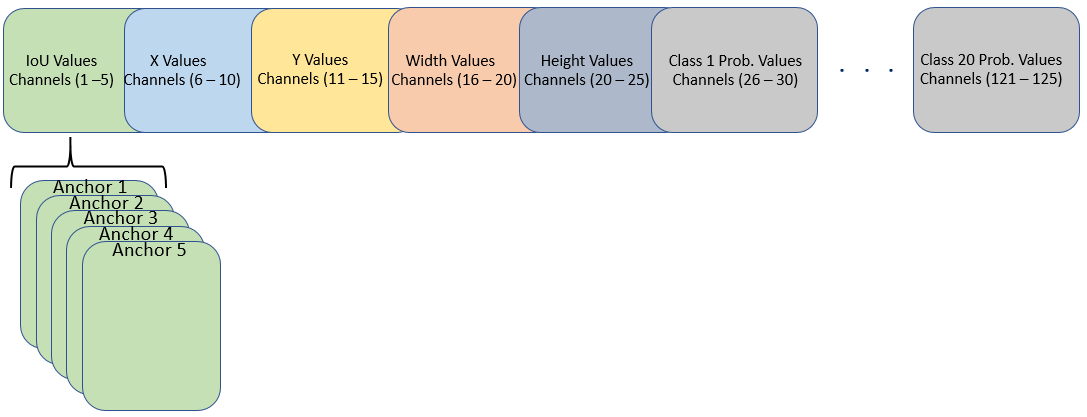
For efficient processing, reorder the weights and biases of the last convolution layer in the imported network to obtain the activations in the arrangement that yolov2ObjectDetector objects require. A yolov2ObjectDetector expects the 125 channels of the feature map of the last convolution layer in the following arrangement:
Channels 1 to 5 — IoU values for five anchors
Channels 6 to 10 — X values for five anchors
Channels 11 to 15 — Y values for five anchors
Channels 16 to 20 — Width values for five anchors
Channels 21 to 25 — Height values for five anchors
Channels 26 to 30 — Class 1 probability values for five anchors
Channels 31 to 35 — Class 2 probability values for five anchors
Channels 121 to 125 — Class 20 probability values for five anchors
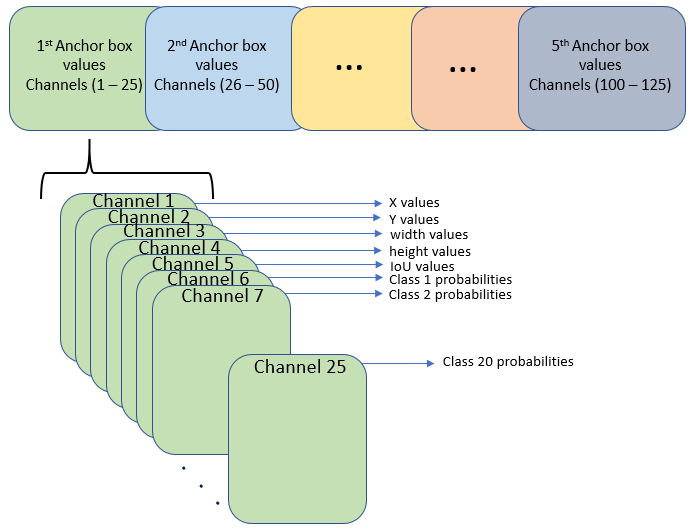
However, in the last convolution layer, which is of size 13-by-13, the activations are arranged differently. Each of the 25 channels in the feature map corresponds to:
Channel 1 — X values
Channel 2 — Y values
Channel 3 — Width values
Channel 4 — Height values
Channel 5 — IoU values
Channel 6 — Class 1 probability values
Channel 7 — Class 2 probability values
Channel 25 — Class 20 probability values
Use the supporting function rearrangeONNXWeights, listed at the end of this example, to reorder the weights and biases of the last convolution layer in the imported network and obtain the activations in the format required by yolov2ObjectDetector.
weights = net.Layers(end,1).Weights; bias = net.Layers(end,1).Bias; layerName = net.Layers(end,1).Name; numAnchorBoxes = size(onnxAnchors,1); [modWeights,modBias] = rearrangeONNXWeights(weights,bias,numAnchorBoxes);
Replace the weights and biases of the last convolution layer in the imported network with the new convolution layer using the reordered weights and biases.
filterSize = size(modWeights,[1 2]); numFilters = size(modWeights,4); modConvolution8 = convolution2dLayer(filterSize,numFilters, ... Name=layerName,Bias=modBias,Weights=modWeights); net = replaceLayer(net,"convolution8",modConvolution8);
Add YOLO v2 Transform Layer
A yolov2ObjectDetector object requires the network to end with a YOLO v2 transform layer. Create this layer and attach it to the last convolution layer.
classNames = tinyYOLOv2Classes; yolov2Transform = yolov2TransformLayer(numAnchorBoxes,Name="yolov2Transform"); net = addLayers(net,yolov2Transform); net = connectLayers(net,layerName,"yolov2Transform"); net.OutputNames = {'yolov2Transform'};
Because the ScalingLayer in the imported network duplicates the preprocessing operations performed by yolov2ObjectDetector, remove the ScalingLayer from the imported network.
yoloScaleLayerIdx = find( ... arrayfun(@(x)isa(x,"nnet.cnn.layer.ScalingLayer"), ... net.Layers)); if ~isempty(yoloScaleLayerIdx) for i = 1:size(yoloScaleLayerIdx,1) layerNames{i} = net.Layers(yoloScaleLayerIdx(i,1),1).Name; end net = removeLayers(net,layerNames); net = connectLayers(net,"image","convolution"); end
Create yolov2ObjectDetector Object
Initialize any unset learnable parameters and state values of the network.
net = initialize(net);
Create a YOLO v2 object detector as a yolov2ObjectDetector object.
yolov2Detector = yolov2ObjectDetector(net,classNames,anchorBoxes)
yolov2Detector =
yolov2ObjectDetector with properties:
Network: [1×1 dlnetwork]
InputSize: [416 416 3]
TrainingImageSize: [416 416]
AnchorBoxes: [5×2 double]
ClassNames: [20×1 categorical]
ReorganizeLayerSource: ''
LossFactors: [5 1 1 1]
ModelName: ''
Detect Objects Using Imported YOLO v2 Detector
Read a test image and convert the channels to BGR format.
I = imread("highway.png");
Ibgr = cat(3,I(:,:,3),I(:,:,2),I(:,:,1));Use the imported detector to detect objects in the test image. Display the results.
[bboxes,scores,labels] = detect(yolov2Detector,Ibgr);
detectedImg = insertObjectAnnotation(I,"rectangle",bboxes,scores);
imshow(detectedImg)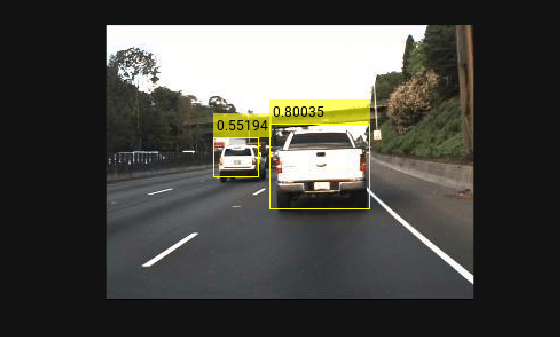
Supporting Functions
function [modWeights,modBias] = rearrangeONNXWeights(weights,bias,numAnchorBoxes) % rearrangeONNXWeights rearranges the weights and biases of an imported YOLO % v2 network as required by yolov2ObjectDetector. numAnchorBoxes is a scalar % value containing the number of anchors that are used to reorder the weights and % biases. This function performs these operations: % * Extract the weights and biases related to IoU, boxes, and classes. % * Reorder the extracted weights and biases as expected by yolov2ObjectDetector. % * Combine and reshape them back to the original dimensions. weightsSize = size(weights); biasSize = size(bias); sizeOfPredictions = biasSize(3)/numAnchorBoxes; % Reshape the weights with regard to the size of the predictions and anchors. reshapedWeights = reshape(weights,prod(weightsSize(1:3)),sizeOfPredictions,numAnchorBoxes); % Extract the weights related to IoU, boxes, and classes. weightsIou = reshapedWeights(:,5,:); weightsBoxes = reshapedWeights(:,1:4,:); weightsClasses = reshapedWeights(:,6:end,:); % Combine the weights of the extracted parameters as required by % yolov2ObjectDetector. reorderedWeights = cat(2,weightsIou,weightsBoxes,weightsClasses); permutedWeights = permute(reorderedWeights,[1 3 2]); % Reshape the new weights to the original size. modWeights = reshape(permutedWeights,weightsSize); % Reshape the biases with regard to the size of the predictions and anchors. reshapedBias = reshape(bias,sizeOfPredictions,numAnchorBoxes); % Extract the biases related to IoU, boxes, and classes. biasIou = reshapedBias(5,:); biasBoxes = reshapedBias(1:4,:); biasClasses = reshapedBias(6:end,:); % Combine the biases of the extracted parameters as required by yolov2ObjectDetector. reorderedBias = cat(1,biasIou,biasBoxes,biasClasses); permutedBias = permute(reorderedBias,[2 1]); % Reshape the new biases to the original size. modBias = reshape(permutedBias,biasSize); end function classes = tinyYOLOv2Classes() % Return the class names corresponding to the pretrained ONNX tiny YOLO v2 % network. % % The tiny YOLO v2 network is pretrained on the Pascal VOC data set, % which contains images from 20 different classes. classes = ["aeroplane","bicycle","bird","boat","bottle","bus","car", ... "cat","chair","cow","diningtable","dog","horse","motorbike", ... "person","pottedplant","sheep","sofa","train","tvmonitor"]; classes = categorical(classes); end
References
[1] Redmon, Joseph, and Ali Farhadi. "YOLO9000: Better, Faster, Stronger." In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517–25. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690.
[2] "Tiny YOLO v2." https://github.com/onnx/models/tree/main/validated/vision/object_detection_segmentation/tiny-yolov2.
[3] Everingham, Mark, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zisserman. "The Pascal Visual Object Classes (VOC) Challenge." International Journal of Computer Vision 88, no. 2 (June 2010): 303–38. https://doi.org/10.1007/s11263-009-0275-4.
[4] "yolov2-tiny-voc.cfg." https://github.com/pjreddie/darknet/blob/master/cfg/yolov2-tiny-voc.cfg.
See Also
Functions
importONNXNetwork|convolution2dLayer|replaceLayer|removeLayers|connectLayers|findPlaceholderLayers|detect(Computer Vision Toolbox) |trainYOLOv2ObjectDetector(Computer Vision Toolbox) |addLayers
Objects
yolov2ObjectDetector(Computer Vision Toolbox)