resnet3dLayers
resnet3dLayers is not recommended. Use the resnet3dNetwork
function instead. For more information, see Version History.
Description
lgraph = resnet3dLayers(inputSize,numClasses)inputSize and a number of classes specified by
numClasses. A residual network consists of stacks of blocks. Each
block contains deep learning layers. The network includes an image classification layer,
suitable for predicting the categorical label of an input image.
lgraph = resnet3dLayers(___,Name=Value)InitialNumFilters=32
specifies 32 filters in the initial convolutional layer.
Examples
Input Arguments
Name-Value Arguments
Output Arguments
More About
Residual networks (ResNets) are a type of deep network that consist of building blocks that have residual connections (also known as skip or shortcut connections). These connections allow the input to skip the convolutional units of the main branch, thus providing a simpler path through the network. By allowing the parameter gradients to flow more easily from the final layers to the earlier layers of the network, residual connections help mitigate the problem of vanishing gradients during early training.
The structure of a residual network is flexible. The key component is the inclusion of the residual connections within residual blocks. A group of residual blocks is called a stack. A ResNet architecture consists of initial layers, followed by stacks containing residual blocks, and then the final layers. A network has three types of residual blocks:
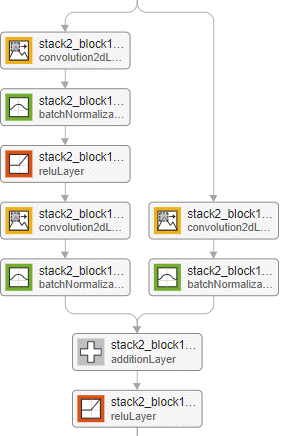
Initial residual block — This block occurs at the start of the first stack. The layers in the residual connection of the initial residual block determine if the block preserves the activation sizes or performs downsampling.
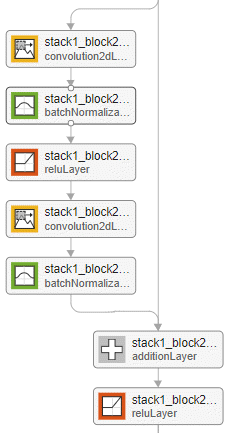
Standard residual block — This block occurs multiple times in each stack, after the first downsampling residual block. The standard residual block preserves the activation sizes.
Downsampling residual block — This block occurs once, at the start of each stack. The first convolutional unit in the downsampling block downsamples the spatial dimensions by a factor of two.
A typical stack has a downsampling residual block, followed by
m standard residual blocks, where m is a positive
integer. The first stack is the only stack that begins with an initial residual block.
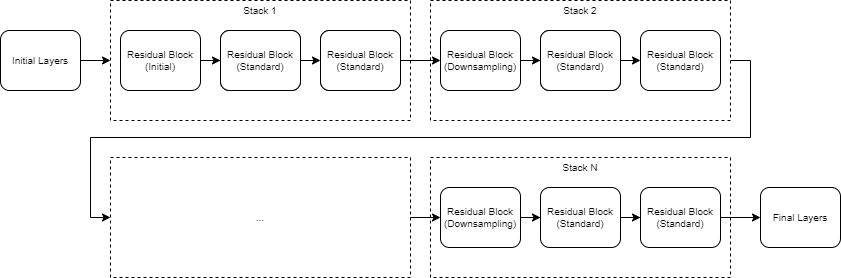
The initial, standard, and downsampling residual blocks can be bottleneck or nonbottleneck blocks. Bottleneck blocks perform a 1-by-1-by-1 convolution before the 3-by-3-by-3 convolution, to reduce the number of channels by a factor of four. Networks with and without bottleneck blocks have a similar level of computational complexity, but the total number of features propagating in the residual connections is four times larger when you use the bottleneck units. Therefore, using bottleneck blocks increases the efficiency of the network.
The layers inside each block are determined by the type of block and the options you set.
Block Layers
| Name | Initial Layers | Initial Residual Block | Standard Residual Block
(BottleneckType="downsample-first-conv") | Standard Residual Block
(BottleneckType="none") | Downsampling Residual Block | Final Layers |
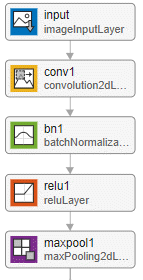
| Description | A residual network starts with the following layers, in order:
Set the optional pooling layer using the
| The main branch of the initial residual block has the same layers as a standard residual block. The
If | The standard residual block with bottleneck units has the following layers, in order:
The standard block has a residual connection from the output of the previous block to the addition layer. Set the
position of the addition layer using the | The standard residual block without bottleneck units has the following layers, in order:
The standard block has a residual connection from the output of the previous block to the addition layer. Set the position of the
addition layer using the | The downsampling residual block is the same as the standard block
(either with or without the bottleneck) but with a stride of
The layers on the residual
connection depend on the
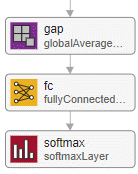
The downsampling block halves the height and width of the input, and increases the number of channels. | A residual network ends with the following layers, in order:
|
| Example Visualization |
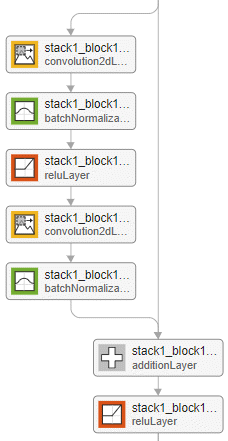
| Example of an initial residual block for a network without a bottleneck and with the batch normalization layer before the addition layer.
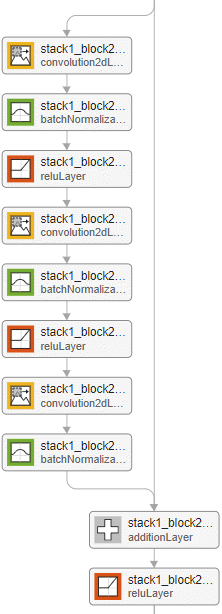
| Example of the standard residual block for a network with a bottleneck and with the batch normalization layer before the addition layer.
| Example of the standard residual block for a network without a bottleneck and with the batch normalization layer before the addition layer.
| Example of a downsampling residual block for a network without a bottleneck and with the batch normalization layer before the addition layer.
|
|
The convolution and fully connected layer weights are initialized using the He weight
initialization method [3]. For more information, see
convolution3dLayer.
Tips
When working with small images, set the
InitialPoolingLayeroption to"none"to remove the initial pooling layer and reduce the amount of downsampling.Residual networks are usually named ResNet-X, where X is the depth of the network. The depth of a network is defined as the largest number of sequential convolutional or fully connected layers on a path from the input layer to the output layer. You can use the following formula to compute the depth of your network:
where si is the depth of stack i.
Networks with the same depth can have different network architectures. For example, you can create a 3-D ResNet-14 architecture with or without a bottleneck:
The relationship between bottleneck and nonbottleneck architectures also means that a network with a bottleneck will have a different depth than a network without a bottleneck.resnet14Bottleneck = resnet3dLayers([224 224 64 3],10, ... StackDepth=[2 2], ... NumFilters=[64 128]); resnet14NoBottleneck = resnet3dLayers([224 224 64 3],10, ... BottleneckType="none", ... StackDepth=[2 2 2], ... NumFilters=[64 128 256]);
resnet50Bottleneck = resnet3dLayers([224 224 64 3],10); resnet34NoBottleneck = resnet3dLayers([224 224 64 3],10, ... BottleneckType="none");
References
[1] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep Residual Learning for Image Recognition.” Preprint, submitted December 10, 2015. https://arxiv.org/abs/1512.03385.
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Identity Mappings in Deep Residual Networks.” Preprint, submitted July 25, 2016. https://arxiv.org/abs/1603.05027.
[3] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." In Proceedings of the 2015 IEEE International Conference on Computer Vision, 1026–1034. Washington, DC: IEEE Computer Vision Society, 2015.